SimCLR: A Simple Framework for Contrastive Learning of Visual Representations

Вставка
- Опубліковано 3 тра 2024
- Full paper:
arxiv.org/abs/2002.05709?ref=...
Presenter: Dan Fu
Stanford University, USA
Abstract:
This paper presents SimCLR: a simple framework
for contrastive learning of visual representations.
We simplify recently proposed contrastive selfsupervised learning algorithms without requiring
specialized architectures or a memory bank. In
order to understand what enables the contrastive
prediction tasks to learn useful representations,
we systematically study the major components of
our framework. We show that (1) composition of
data augmentations plays a critical role in defining
effective predictive tasks, (2) introducing a learnable nonlinear transformation between the representation and the contrastive loss substantially improves the quality of the learned representations,
and (3) contrastive learning benefits from larger
batch sizes and more training steps compared to
supervised learning. By combining these findings,
we are able to considerably outperform previous
methods for self-supervised and semi-supervised
learning on ImageNet. A linear classifier trained
on self-supervised representations learned by SimCLR achieves 76.5% top-1 accuracy, which is a
7% relative improvement over previous state-ofthe-art, matching the performance of a supervised
ResNet-50. When fine-tuned on only 1% of the
labels, we achieve 85.8% top-5 accuracy, outperforming AlexNet with 100× fewer labels. - Розваги
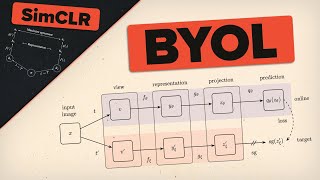







starts at 6:30
contrastive loss 9:20
self supervised contrastive loss 15:30
key findings 20:07
thanks
The group is awesome.. they are asking most question that the audience might ask!
It was a good summary indeed...seeing this after going through the paper actually makes more sense!
In 24:05, I think the green bar is only present for the 2048 dimensional size (in the y-axis) and not for the other dimensionalities because the representation 'h' is fixed (2048) according to the caption in the figure 8 of the paper. In the presence of a linear or non-linear layer, the output dimension may be altered (32, 64, 128 etc), but for no-projection, the 'h' is directly being used in the loss function. Since, h is fixed for 2048, it is not being compared for other dimensional sizes.
thanks for sharing guys
Really good explanation!
You eased my burden!
Can you share paper presentation slides Dan Fu?
why is that 2 FC Layers layers become non-linear at 25:00?
I think for the 1 FC case, it's just the linear layer without activation, and in the 2 FC case, there is a relu activation between them that makes it nonlinear (btw "relu" in that slide is written in a small font so it's hard to see)