I've been having these videos come up as recommendations to watch on youtube. Lex is so good at teaching these topics that can get a bit complicated. I wish I had more professors like Lex in college for courses that had difficult to understand concepts. He really breaks things down slowly, and explains things in a way that people can understand.
About the Udacity Challenge: It is very likely that none of these winning models will be able to steer a car. What they are really good at is predicting the steering angle depending on the last few frames. Actually you may be able to compute that by using the difference image of the last two frames without any network and achieve almost the same performance as the winning teams. As Nvidia mentioned in their paper End to End Learning for Self-Driving Cars without learning error correction the car will just leave the center of the road and the network has no idea how to correct that because the situation is not known from the training data. My point is steering a car correctly on a real road and the prediction of steering angles based on a video are two different challenges.
Thanks so much for this, Lex. Your lecture was how I finally understood how RNNs work and it helped me to successfully complete my university thesis back in 2017. It's funny how I came across you again through Joe Rogan and your podcast and figured it's the same dude that helped me through college. Hope you get to be the one that builds robots better than anybody else in the world.
Some, hopefully helpful for the audience, remarks: 1. You need a lot of data. Depends. A lot of unlabeled data helps - to model the world. Then u need very little supervised data. Easy problems require little data. Hard or badly defined tasks require a lot of data. You can always pick an easier to solve proxy objective and use data augmentation. 2. rnns are dynamic length. Hard Set sequence lengths are for speed since: sentences come at different lengths. So u cant create batches, unless you set a hard sequence length and then train same length sentences together in a batch, or fill up sentences that are too short by padding. If you batch sentence you can compute on them in parallel. Now of you are trying to predict relations between consecutive sentences, batching/ parallelization would not update the weights after each sentence, but on all of them at once - making it near impossible to learn inter (between) sentence relations but allowing the net to learn intra (within) sentence relations. Tip: read karparthys blog on rnns not the Colah one. Karpathys is more detailed allowing you to really grasp what an rnn does. An lstm is „just“ and rnn with attention/gating. Hope this helps, even if some concepts are very high level.
Am I the only person who thought that the video compression makes his shadow look like a low resolution shadow map...? Awesome content, great for getting into ML! A quick question regarding LSTM's, why do we need a separate way of saying 'this information isn't important, I don't want to update my weights'. Doesn't gradient descent already take care of this? That is, if we happen to see a feature that is unimportant, won't we compute low gradients, thus telling us we don't need to move the weight by much? Why doesn't that work here?
James Norton Theory vs practice. The gates separate out learning mechanism like accept knowledge, apply knowledge and forget knowledge making it easier for the memory cell to learn. The memory is just a fully connected layer. By modeling gates you ad human bias on how - by what learning concepts - it should learn. That way u give it prior knowledge on how to precess the data, which means faster learning or analogously learning better from less data. In probabilistic models we work with priors and regularizers (math tools) in NNs we can also work with code/information flow design (programmer tools). Cnns model sequences as well. Just not dynamic lengths. Since they see the whole sequence at once, rather than sequentially, they do not struggle with longer term sequence element dependencies - e.g. lstms struggle connecting words from the start of a long sentence with the end of the sentence. Cnns/ transformers see all words at once so they dont care.
I've never listened to anyone before without understanding anything at all. It's fascinating for me watching with zero understanding. I'm literally just listening to his words... 😂
Hey,Lex. Really great video! But as English is not my mother tongue, sometimes it's difficult to understand the video very well, it would be nice if you can turn on the cc subtitle options, thanks!
Really great video. Thanks! Quick question... At 1:13:34, the team used a CNN to create a distributed representation of each frame, and then they use this as the input to the RNN. Was this just a generic CNN trained on completely different types of images? Or did they train a new one using the driving images? If the latter, what target variable would they use to train it? Thanks!
Hello, thanks for uploading these lectures! Can LSTM networks integrate symbolic constructs in natural language learning? Can it help computers understand the relationship between language structure and real world? For example if I ask "Why is only raining outside? " It should know that the roof stops the rain falling inside. I have a feeling that we are mostly teaching the algorithm to interact with us, in some kind of smart language simulation but at it's core it doesn't really understand the meaning and relationships between words. Do you know some online references towards this?
Hi Lex, thanks for uploading these! When it comes to CNN + RNNs, is it only possible to use a pretrained CNN as a feature extractor, and then train just the weights in the RNN? Or, is it possible to use backprop to train the CNN and the RNN simultaneously? If it is possible to train both, is it desirable? Know if anyone has published anything on this?
The actual process is to train both CNN and RNN simultaneously. But a pretrained CNN would give a feature representation which will work pretty well with the RNN too. But yes, the actual method is to train the CNN and RNN simultaneously.
I still prefer the LSTM (for accuracy) | GRU (for speed) over the Transformer's architecture for both; their ability to learn long-dependencies and their simplicity.
Great Lecture. Thanks a lot for explaining gradient descent in a simple way. What is your opinion on using PSO for training DNN's? Do you think there is scope for research in that area?
It's says that things like PSO or GA (genetic algorithm) doesn't work better than SGD, for deep learning. Also says that it exist research in this area. Based in my expererience, PSO or GA are more robust to being stuck on locals minima, but they need a lot more computacional power ( Time ), than traditional numerical optimization methods. Deep learning takes now a lot of computer days time, so time is critic. Maybe it would be interesting some mix between the randomness of the bio inspired optimization method (PSO, GA) and the computacion eficiency of the classic numerical methods ( SGD do some kind of this mix whit the mini batches part, but it could be other approach).
Thanks! The position of the steering wheel doesn't equal 1:1 the angle of the car tire. There's a steering ratio that control how you map one to the other. Here's a helpful link: en.wikipedia.org/wiki/Steering_ratio
Hi Lex, To work around problems with local minima, is smoothing up the source data itself a good solution. The output needs to be approximate anyways. Why not manipulate the source data so that all the gradients are smooth and converging to one local minima?
To smooth it reliably, you need to know the landscape of the data. In other words you actually need to know the minima. After you know them there's no point in smoothing the data anymore, as you know all minima.
I am not sure if you would actually need to know the minima. I have seen and used algorithms that smoothens 3d point data. This is a different field but the end result of these algorithms is to remove rough edges or deep crevices. I wonder if we can come up with a similar general algorithm to smoothen multidimensional data.
I find the subject content, 'Recurrent Neural Networks for Steering Through Time', very well presented. An interactive class environment that was improvised self-learning discussion topics were explained. A suggestion for @lexfridman: On Modularity Expanded (ua-cam.com/video/nFTQ7kHQWtc/v-deo.html). You can definitely present how you visualize running graphs! Music; an example for ratings. A side note: Keep your ‘walking through the abstract’ as your own understanding, which I believe can be really useful to learners, and thank you for keeping it up :)
Hi Lex, are the Traffic/Tesla competitions still running? I see they're up on the site but with no end-dates. Were the prizes only for ver. 1.0 or also for the ver 1.1 currently up?
Hey , Lex It is Really Great lecture. Actually i am working on Deep Learning Specially on Autonomous Cars. Those Lectures are helped me a lot. But i have some Questions. the first thing is How could Motion Planing can be Machine learning ? if we are using GPS? second one, ( this is one might not related with your lectures) i am thinking about measuring a distance between the objects and the camera without using any Focal length or something related to the camera's property, to make it portable t any!! can we do this by deep learning! ?? and One more question , What is the title of the book ? (the Priceless one ) Thanks
Hey Israel, good questions. Answers: 1. Check out the deep RL lecture for how motion planning can be formulated as a machine learning problem: ua-cam.com/video/QDzM8r3WgBw/v-deo.html 2. The problem you're describing is essentially localization and visual odometry. Deep learning is beginning to be used for these applications, but there's a lot of work left to be done. 3. The deep learning book is called "Deep Learning" and you can find more about it here: www.deeplearningbook.org
Usually 3D-CNN is referring to convolution that works on a sequence of image not just a single image (even if it has 3 channels). I would recommend you check out this paper from Karpathy et al.: www.cv-foundation.org/openaccess/content_cvpr_2014/papers/Karpathy_Large-scale_Video_Classification_2014_CVPR_paper.pdf
Its super interesting - he really take his time with the answer when asked a question - but the quality of the answers is actually really high - also watching at 1.25 :) - Great Lectures!
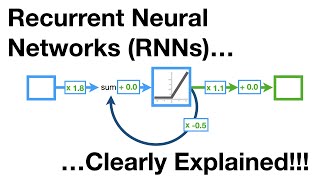
Well since its a recurrent neural network, one of your gradients might end up being multiplied by 2, so for everytime you back propogate the gradient would increase by 2^n, where n is the number of times you run the recurrent neural network. Sometimes your network can run like 40 times, where in your gradient would come out to 2^40, which is like close the the number of hydrogen atoms in the universe, no good. Same thing can happen when you are multiplying by n^-x where x is just a number greater than one, which would make your gradient infintesimally small. Sorry for my grammer and spelling.
Oh also most important part, this is why you use the sigmoid function, because as the gradient aproaches larger and larger numbers it normalizes out to 1
It is extremely concerning that these students are not expected to know calculus cold. There is no such thing as, "but I understand the concepts". You use basic technical skill to check your understanding of concepts, so without knowing your abcs, you will tend to convince yourself of things that aren't true. There is a lot of democratizing technology out there now where you don't need to know what's going on "under-the-hood", but without at least some knowledge, all you will be able to do is press buttons and make graphs.









I've been having these videos come up as recommendations to watch on youtube. Lex is so good at teaching these topics that can get a bit complicated. I wish I had more professors like Lex in college for courses that had difficult to understand concepts. He really breaks things down slowly, and explains things in a way that people can understand.
Academic by day... bouncer by night
rly?
Nailed it! 1st impression!
😅😅😂
About the Udacity Challenge: It is very likely that none of these winning models will be able to steer a car. What they are really good at is predicting the steering angle depending on the last few frames. Actually you may be able to compute that by using the difference image of the last two frames without any network and achieve almost the same performance as the winning teams. As Nvidia mentioned in their paper End to End Learning for Self-Driving Cars without learning error correction the car will just leave the center of the road and the network has no idea how to correct that because the situation is not known from the training data. My point is steering a car correctly on a real road and the prediction of steering angles based on a video are two different challenges.
What happens if you stop it from remembering the last few frames so it has to make the decision based on other factors?
Thanks so much for this, Lex. Your lecture was how I finally understood how RNNs work and it helped me to successfully complete my university thesis back in 2017. It's funny how I came across you again through Joe Rogan and your podcast and figured it's the same dude that helped me through college. Hope you get to be the one that builds robots better than anybody else in the world.
I have to say you are very talented for teaching very complex topics. Thank you so much MIT for choosing such a brilliant presenter.
"It's producing something that sounds like words...That could do this lecture for me. I wish..." 1:02:42 Oh Lex would rather be researching xD.
Will there be some example of ML that can do the research too?
Ive been following your videos but never knew you are/were a tutor/lecturer... I am going to enjoy this.
Great video, but I wish there was more math and a more thorough explanation of BPTT and the vanishing gradient problem.
Some, hopefully helpful for the audience, remarks:
1. You need a lot of data. Depends. A lot of unlabeled data helps - to model the world. Then u need very little supervised data. Easy problems require little data. Hard or badly defined tasks require a lot of data. You can always pick an easier to solve proxy objective and use data augmentation.
2. rnns are dynamic length. Hard Set sequence lengths are for speed since:
sentences come at different lengths. So u cant create batches, unless you set a hard sequence length and then train same length sentences together in a batch, or fill up sentences that are too short by padding.
If you batch sentence you can compute on them in parallel.
Now of you are trying to predict relations between consecutive sentences, batching/ parallelization would not update the weights after each sentence, but on all of them at once - making it near impossible to learn inter (between) sentence relations but allowing the net to learn intra (within) sentence relations.
Tip: read karparthys blog on rnns not the Colah one. Karpathys is more detailed allowing you to really grasp what an rnn does. An lstm is „just“ and rnn with attention/gating.
Hope this helps, even if some concepts are very high level.
Ooh I recognize what's on the blackboard! It's the spherical coordinate system...
Hi Lex, thank you for these lectures! Would you be uploading the guest lectures as well? There isn't any mention of them in the course home page now .
Niaz, definitely, working on it.
Am I the only person who thought that the video compression makes his shadow look like a low resolution shadow map...? Awesome content, great for getting into ML!
A quick question regarding LSTM's, why do we need a separate way of saying 'this information isn't important, I don't want to update my weights'. Doesn't gradient descent already take care of this? That is, if we happen to see a feature that is unimportant, won't we compute low gradients, thus telling us we don't need to move the weight by much? Why doesn't that work here?
James Norton Theory vs practice. The gates separate out learning mechanism like accept knowledge, apply knowledge and forget knowledge making it easier for the memory cell to learn. The memory is just a fully connected layer. By modeling gates you ad human bias on how - by what learning concepts - it should learn.
That way u give it prior knowledge on how to precess the data, which means faster learning or analogously learning better from less data.
In probabilistic models we work with priors and regularizers (math tools) in NNs we can also work with code/information flow design (programmer tools).
Cnns model sequences as well. Just not dynamic lengths. Since they see the whole sequence at once, rather than sequentially, they do not struggle with longer term sequence element dependencies - e.g. lstms struggle connecting words from the start of a long sentence with the end of the sentence. Cnns/ transformers see all words at once so they dont care.
This gave me so much understanding. Thank you for uploading!
I've never listened to anyone before without understanding anything at all. It's fascinating for me watching with zero understanding. I'm literally just listening to his words... 😂
Thank you Lex and MIT
Self driving cars 1:04:00
Hey,Lex. Really great video! But as English is not my mother tongue, sometimes it's difficult to understand the video very well, it would be nice if you can turn on the cc subtitle options, thanks!
1:14:17 Who else thought their battery was low paused the video to check their battery😂🤣😂🤣
Lex, Thanks for sharing, really appreciated!
Is there a playlist for the lectures leading up to this?
My god, Lex is so lost on this lecture. It's almost like he forgot what he wanted to say when building the presentation.
Really great video. Thanks! Quick question... At 1:13:34, the team used a CNN to create a distributed representation of each frame, and then they use this as the input to the RNN. Was this just a generic CNN trained on completely different types of images? Or did they train a new one using the driving images? If the latter, what target variable would they use to train it? Thanks!
Really cool course! Hi Lex, why only this the fourth lecture has no subtitle (Other 4 lectures do have)? Could you please upload one? Thank you.
Great course with huge content in it, I am curious whether the Guest Talks are available too.
Great lecture :) Mark and keep watching tomorrow ^.^
Parameter tuning can't be taught? But it can be learned? I wonder if that would be a useful thing to apply ML to?
Hello, thanks for uploading these lectures! Can LSTM networks integrate symbolic constructs in natural language learning? Can it help computers understand the relationship between language structure and real world? For example if I ask "Why is only raining outside? " It should know that the roof stops the rain falling inside. I have a feeling that we are mostly teaching the algorithm to interact with us, in some kind of smart language simulation but at it's core it doesn't really understand the meaning and relationships between words. Do you know some online references towards this?
Thanks for the course. I learned a lot from it. Thanks!
Hi Lex, thanks for uploading these!
When it comes to CNN + RNNs, is it only possible to use a pretrained CNN as a feature extractor, and then train just the weights in the RNN? Or, is it possible to use backprop to train the CNN and the RNN simultaneously? If it is possible to train both, is it desirable? Know if anyone has published anything on this?
The actual process is to train both CNN and RNN simultaneously. But a pretrained CNN would give a feature representation which will work pretty well with the RNN too. But yes, the actual method is to train the CNN and RNN simultaneously.
Cody Neil they have done this for action recognition
I think before introducing the backprop it is a good idea to start with the forward mode
Fantastic lecture. It explained a lot.
I still prefer the LSTM (for accuracy) | GRU (for speed) over the Transformer's architecture for both; their ability to learn long-dependencies and their simplicity.
Thank you so much Lex!!
Great Lecture. Thanks a lot for explaining gradient descent in a simple way. What is your opinion on using PSO for training DNN's? Do you think there is scope for research in that area?
It's says that things like PSO or GA (genetic algorithm) doesn't work better than SGD, for deep learning. Also says that it exist research in this area. Based in my expererience, PSO or GA are more robust to being stuck on locals minima, but they need a lot more computacional power ( Time ), than traditional numerical optimization methods. Deep learning takes now a lot of computer days time, so time is critic. Maybe it would be interesting some mix between the randomness of the bio inspired optimization method (PSO, GA) and the computacion eficiency of the classic numerical methods ( SGD do some kind of this mix whit the mini batches part, but it could be other approach).
Thanks for your sharing! I don't understand why the value of wheel could be bigger than pi/2, and what's the meaning of it?
Thanks! The position of the steering wheel doesn't equal 1:1 the angle of the car tire. There's a steering ratio that control how you map one to the other. Here's a helpful link: en.wikipedia.org/wiki/Steering_ratio
Hi Lex, To work around problems with local minima, is smoothing up the source data itself a good solution. The output needs to be approximate anyways. Why not manipulate the source data so that all the gradients are smooth and converging to one local minima?
To smooth it reliably, you need to know the landscape of the data. In other words you actually need to know the minima. After you know them there's no point in smoothing the data anymore, as you know all minima.
I am not sure if you would actually need to know the minima. I have seen and used algorithms that smoothens 3d point data. This is a different field but the end result of these algorithms is to remove rough edges or deep crevices. I wonder if we can come up with a similar general algorithm to smoothen multidimensional data.
I find the subject content, 'Recurrent Neural Networks for Steering Through Time', very well presented.
An interactive class environment that was improvised self-learning discussion topics were explained.
A suggestion for @lexfridman: On Modularity Expanded (ua-cam.com/video/nFTQ7kHQWtc/v-deo.html). You can definitely present how you visualize running graphs! Music; an example for ratings.
A side note: Keep your ‘walking through the abstract’ as your own understanding, which I believe can be really useful to learners, and thank you for keeping it up :)
Hi Lex, are the Traffic/Tesla competitions still running? I see they're up on the site but with no end-dates. Were the prizes only for ver. 1.0 or also for the ver 1.1 currently up?
Hey, yes 1.1 is still running with no firm deadline. I'm working hard to turn 1.1 to 2.0 in May or June with big prizes. Stay tuned.
Great to hear. Good luck & I'll be working on it.
Is it that most explanations given for RNN are top-down and most explanations for CNN are bottom-up?
Hey , Lex It is Really Great lecture. Actually i am working on Deep Learning Specially on Autonomous Cars. Those Lectures are helped me a lot. But i have some Questions. the first thing is How could Motion Planing can be Machine learning ? if we are using GPS? second one, ( this is one might not related with your lectures) i am thinking about measuring a distance between the objects and the camera without using any Focal length or something related to the camera's property, to make it portable t any!! can we do this by deep learning! ?? and One more question , What is the title of the book ? (the Priceless one )
Thanks
Hey Israel, good questions. Answers:
1. Check out the deep RL lecture for how motion planning can be formulated as a machine learning problem: ua-cam.com/video/QDzM8r3WgBw/v-deo.html
2. The problem you're describing is essentially localization and visual odometry. Deep learning is beginning to be used for these applications, but there's a lot of work left to be done.
3. The deep learning book is called "Deep Learning" and you can find more about it here: www.deeplearningbook.org
Great , Thank you Very Much!
Where is that sky view 360?
amazing lecture
What is 3D convolution of an Image? Is there a good link to study it?
Usually 3D-CNN is referring to convolution that works on a sequence of image not just a single image (even if it has 3 channels). I would recommend you check out this paper from Karpathy et al.: www.cv-foundation.org/openaccess/content_cvpr_2014/papers/Karpathy_Large-scale_Video_Classification_2014_CVPR_paper.pdf
Thanks Lex. Will check it out.
hi @Lex Fridman , this whole course will be put on UA-cam?
Ankur, yes every lecture and most of the guest talks will be uploaded to UA-cam. Just follow the site cars.mit.edu and the playlist goo.gl/SLCb1y
Thank you for your sharing and i will expect the coming lectures and the guest talks!
very nice lecture!
Good video!
Bruh I have no idea what he’s talking about but I’m some how interested
why their is no subtitle for this vedio ?!
Thanks For Sharing
Beautiful, Just Beautiful.
Woo hoo! Excellent lecture!!
Perfect at 1.25 speed
I am watching at 2x, but this guy is amazing teacher.
Its super interesting - he really take his time with the answer when asked a question - but the quality of the answers is actually really high - also watching at 1.25 :) - Great Lectures!
Brilliant
Can someone tell me why those vanishing gradients or exploding gradients occur, since i am such a dumb guy, i want to correlate it to nature.
Well since its a recurrent neural network, one of your gradients might end up being multiplied by 2, so for everytime you back propogate the gradient would increase by 2^n, where n is the number of times you run the recurrent neural network. Sometimes your network can run like 40 times, where in your gradient would come out to 2^40, which is like close the the number of hydrogen atoms in the universe, no good. Same thing can happen when you are multiplying by n^-x where x is just a number greater than one, which would make your gradient infintesimally small. Sorry for my grammer and spelling.
Oh also most important part, this is why you use the sigmoid function, because as the gradient aproaches larger and larger numbers it normalizes out to 1
I like this course. Thank you!
"If you enjoyed the video" he said ! Maybe you should rethink what you say.
Please answer me. What do I need to know to create my own Python deep learning framework? What are the books and courses to get knowledge for this?
I love this!
It is extremely concerning that these students are not expected to know calculus cold. There is no such thing as, "but I understand the concepts". You use basic technical skill to check your understanding of concepts, so without knowing your abcs, you will tend to convince yourself of things that aren't true. There is a lot of democratizing technology out there now where you don't need to know what's going on "under-the-hood", but without at least some knowledge, all you will be able to do is press buttons and make graphs.
Aweosome!
És um infeliz
@@vitoriasousa6298 Ai ai senhora Vitória
You look very cute compared to 2022 here 🤩
Vanilla is also what we call squares people who prefer missionary position are vanilla lol just saying
So you are familiar with vanilla... of course...
43:43
why the hell is this allowed to be on youtube ? he is literally just reading through the slides. There is no explanation, here
this presentation was bad. 1000 thumbs up was ...?
What specifically?
@@quintrankid8045 He's just reading crap, not teaching.
god DAMN he was chunky. Rlly Came a long way
No wonder he took up podcasting. He is very confused by simple calculus.
Amazing lecture
54:27