Thanks for the video. Why does the linear regression in SPSS have a correlation matrix that calculates the pearson correlation. I understand from previous videos, that normality of the independent variables isn't important for linear regression. The problem is I am trying to do a regression and one of the independent variables is not normally distributed (I tried to transform it, but couldn't get it normal) but I still put it in a regression and the correlation matrix calculated pearsons rather than spellmans coefficient respectively. Do you have any advice or recommendations?
SPSS just reports the Pearson correlations by default. It doesn't first check normality. If you're data are insufficiently normally distributed for a "regular" linear regression analysis, you should try to conduct the analysis with bootstrapping as the estimation procedure (to estimate the standard errors and p-values). I don't know if you have the bootstrapping module in SPSS or not.
@@how2stats I have just one non-normally distributed variable (I tried to transform but unsuccessfully). I have also tried bootstrapping (it is present on my system) but I'm not sure how to interpret it. Besides, the dataset has quite a few missing records. It is patients data from 2012 and for some of them certain variables were not taken. I had used the ''exclude cases pairwise" for the missing values so as not to miss out useful correlations in the matrix and I think that somehow messes up bootstrapping process and stops the output at the correlation stage.
I haven't come across any for Spearman's r, however, my hunch is that essentially the same guidelines would apply to Spearman (if the analysis were ever undertaken like Gignac & Szodorai (2016).
Hi! I have to perform correlation for my master thesis. My research is about word associations and my data are multiple response sets. I need to examine whether there is a correlation between the part of speech of stimuli items ( 38 nouns, 3 verbs and 4 adjectives) and the response category (paradigmatic, syntagmatic, phonological). What should I do?
Dear how2stats. I bother you for a SPSS related issue. I will be very grateful if you can help. A = categorical (2 categories, independent) variable B = numerical (dependent variable) C = numeric (covariant variable) Both B and C appeared significantly different between the two groups according to T-test. How do we analyze the effect of A on B, free from C? 1. ANCOVA (B dependent variable, C covariant). But because C is significantly different between the two groups, does it cause bias? 2. If we assign A (dummy variable) and C independent and B dependent variable and perform regression analysis but B and C show colinearity and regression assumptions cannot be provided?
3. Need to randomise the groups again in terms of C and then perform t test? 4. None :)?
I discuss the misconception that C must be unrelated to A to perform an ANCOVA in my free textbook (www.how2statsbook.com; the chapter on ANCOVA). In my opinion, you could do an ANCOVA, assuming you want to control for the effects of C on both B and A; if you only want to control for the effects of C on only B or only A, then you could do a semi-partial correlation (I discuss two types of semi-partial correlations in my free textbook).









Are you Ok? You haven't posted since 3 years.
Thanks for freshening up my statistics
Can you please do a video on mixed effect models with interaction...ALso generalized mixed effect models using SPSS
Very cool
Thank you this is great
Thank you sir.
Your videos helped me alot during COVID19
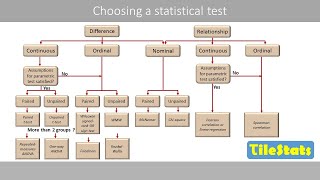
if we want to make a correlation between ordinal and nominal data, what type of test i should use?
Thank you!
Thanks for the video. Why does the linear regression in SPSS have a correlation matrix that calculates the pearson correlation. I understand from previous videos, that normality of the independent variables isn't important for linear regression. The problem is I am trying to do a regression and one of the independent variables is not normally distributed (I tried to transform it, but couldn't get it normal) but I still put it in a regression and the correlation matrix calculated pearsons rather than spellmans coefficient respectively. Do you have any advice or recommendations?
SPSS just reports the Pearson correlations by default. It doesn't first check normality. If you're data are insufficiently normally distributed for a "regular" linear regression analysis, you should try to conduct the analysis with bootstrapping as the estimation procedure (to estimate the standard errors and p-values). I don't know if you have the bootstrapping module in SPSS or not.
@@how2stats I have just one non-normally distributed variable (I tried to transform but unsuccessfully). I have also tried bootstrapping (it is present on my system) but I'm not sure how to interpret it. Besides, the dataset has quite a few missing records. It is patients data from 2012 and for some of them certain variables were not taken. I had used the ''exclude cases pairwise" for the missing values so as not to miss out useful correlations in the matrix and I think that somehow messes up bootstrapping process and stops the output at the correlation stage.
Do you know if any similar guidelines exist for Spearman's rho?
I haven't come across any for Spearman's r, however, my hunch is that essentially the same guidelines would apply to Spearman (if the analysis were ever undertaken like Gignac & Szodorai (2016).
Hi! I have to perform correlation for my master thesis. My research is about word associations and my data are multiple response sets. I need to examine whether there is a correlation between the part of speech of stimuli items ( 38 nouns, 3 verbs and 4 adjectives) and the response category (paradigmatic, syntagmatic, phonological). What should I do?
Dear how2stats. I bother you for a SPSS related issue. I will be very grateful if you can help.
A = categorical (2 categories, independent) variable
B = numerical (dependent variable)
C = numeric (covariant variable)
Both B and C appeared significantly different between the two groups according to T-test. How do we analyze the effect of A on B, free from C?
1. ANCOVA (B dependent variable, C covariant). But because C is significantly different between the two groups, does it cause bias?
2. If we assign A (dummy variable) and C independent and B dependent variable and perform regression analysis but B and C show colinearity and regression assumptions cannot be provided?
3. Need to randomise the groups again in terms of C and then perform t test?
4. None :)?
I discuss the misconception that C must be unrelated to A to perform an ANCOVA in my free textbook (www.how2statsbook.com; the chapter on ANCOVA). In my opinion, you could do an ANCOVA, assuming you want to control for the effects of C on both B and A; if you only want to control for the effects of C on only B or only A, then you could do a semi-partial correlation (I discuss two types of semi-partial correlations in my free textbook).
@@how2stats thank you very much :)
@@how2stats the last question is if the ancova assumptions are not met what can we do?
Woww This is very useful. Thank you so much
Dear Sir, Kindly Guide us on logistical regression too, when these are going to be released. waiting eagerly