Arm-chair fractal geometry expert here. Was expecting to be bored, but was actually thrilled to see how your optimizations would perform. However I'm dispointed you didn't go on a 45 minute tangent about the existential implications of the fractal nature of life, the universe, and everything.
@@daedreaming6267 What he actually forgot to take into account is that there is no such things as the fractal nature of things, because things are not fractal in nature.
@@SpaghettiToaster in my point of view everything in nature is paralel (mirrored to infinite). We can't find the start since its infinit but we will be able to predict the future and change the lane of our evolution. In my mind a higher being developed us for God knows what purpose and to be paralel with that, someone else created them too, when our turn comes we will create other if we didn't already (animals).
@@emjizone I'm pretty sure that if you would iterate through every single color component of every single pixel in every single frame in every single video for every single video resolution as they are stored on the google servers you'd pretty much find the number 42 in all of them. And for the off-chance a video's video stream doesn't contain that number there are also the audio streams to sifter through... :)
Fractals are so named for their FRACTionAL dimensionality. for instance, the Mandelbrot set is neither 1D nor 2D but 1.72 dimensional. Fractals are characterized by their infinite perimeter but 0 area (or other applicable into)
From my own testing with other problems (N-Body) you don't actually need to do much. If you look here: gcc.gnu.org/projects/tree-ssa/vectorization.html You'll see that GCC will actually automatically compile SIMD instructions if you compile past -O2, just make sure your code is in a vector/array or otherwise contiguous in memory. I'd imagine MSVC will do something very similar.
Yes PLEASE!!! I'm at this point in my coding journey where I need to start getting the most performance I can and have started looking at parallelism so this would be very interesting
More SIMD/AVX videos? Yes, please. I'd love to learn more about those, I only know the basics sadly. I pray to the compiler gods that they have mercy upon my soul and vectorize it automatically.
In most cases, they can't auto-vectorize. Usually because it can't be certain your pointers aren't aliasing, it thinks your stores may be changing the values of subsequent loads, so it is afraid to use SIMD, it changes the results. You can help a lot with "restrict" pointers (__restrict in g++). It can be absolutely sure there is no aliasing when you say they are restrict. Saying restrict in the signature's pointers means that the function cannot deal with the restrict pointers pointing to the same memory. Applying that restriction sets the compiler free to assume that its stores won't be feeding back into loads, allowing vectorization.
Instead of praying, you can profile and inspect compiler output. It's hard to speed up your code when you don't know where the bottlenecks are and you can help the compiler with autovectorising if you provide it with some hints. Writing code with intrinsics directly is not very maintainable, and better thing to do would be to look into parallel processing libraries that manage this complexity for you. Also by looking at output assembly you're able to confirm that other optimisations are working such as instruction level paralellism
I think the Mandelbrot Set and fractals in general are so engaging because they're the closest thing we have of visualizing eternal cosmic inflation, and that pokes at a very powerful memory of our collective consciousness. Also the pretty colors.
For everybody interested in the mandelbrot set and not deep in the subject i woukd suggest to search for "numberphile mandelbrot". Really nice videos ... have fun!
This is exactly the type of computation that GPUs are designed for, and you would likely see a huge performance improvement there. In addition, while this approach generalizes fractal computation somewhat well, there are many techniques to be explored to optimize specifically the rendering of the mandelbrot set. For example, there is no need for the computation to go to the max iteration count for pixels which are clearly in the middle region and will go forever if possible. There are also ways to scale the values of the floating points based on the zoom so that the issue of precision is not a limitation. This would allow you to zoom indefinitely. Next, it does not make sense that 32 threads should have improved performance over 8 threads on your machine, since your 4 core processor can only effectively execute instructions from 8 threads simultaneously (two instruction streams per CPU core). I would also say avoid busy waiting for threads in the thread pool. Simply deschedule these threads if they do not have work to do, and make them runnable when they should run. It is perhaps possible that this is handled somehow by the OS/Compiler (if a loop is seen to jump to the previous instruction and the condition is not met, the processor may be able to dynamically see that no useful progress can be made and the thread will yield to another?), although unlikely. While it is a rule of thumb to avoid thread busy waiting at all costs on a single core machine, there are reasons why busy waiting may be an appropriate solution in a multi-core system: conditions can change while a thread is busy waiting due to the behavior of other threads, and the system call to make the thread runnable can be avoided. So the tradeoffs between these options should be weighed. Also your solution to thread synchronization (atomic counter) can be replaced more elegantly with a barrier or other synchronization primitive. An interesting experiment for the approach you have taken would be to disable the optimization flags of the compiler, so that simple code optimizations such as loop unrolling or strength reduction can actually be measured.
With the way he was doing things it absolutely makes sense that 32 threads would improve performance over 8 threads, what is probably tripping you up is that the number of threads isn't the reason it'll be faster (because more threads doesn't really help as you probably correctly concluded), but rather it is faster because he divides the area up based on the number of threads thus reducing the time it takes to process the most computationally expensive section, which with only 32 sections is likely still a major bottleneck. With just 8 threads and 8 sections whenever a thread completes its section then the hardware thread will sit idle until the others are all complete, but with 32 threads and 32 sections whenever a section is completed another software thread can utilise the hardware thread that was freed up, and the maximum time to complete a section is reduced to a quarter of what it would take with 8 sections allowing it to be up to nearly 4 times faster in the worst case scenario for 8 threads. However it is entirely dependent on the complexity of the sections and how well balanced they are, if all 8 sections are equally complex then there will be no performance benefit running 32 threads/sections, and 32 threads/sections may even be marginally slower in that case. Basically the more sections there are the better it can load balance and keep the CPU fully utilised, at least up to the point where the overhead of more threads starts negating the better utilisation.
AusSkiller is right. You're speaking of a better but way more complex implementation. Javi's goal is to use a minimalist implementation that still makes a good use (although not optimal) of the cores. For his algorithm makes sense to use more threads because it reduces the overall time to join them.
@@AusSkiller I see your point. The load balancing is the key issue here. For each thread to have somewhat equal work, each pixel should have an estimated cost and the total cost of the pixels for each thread should be similar. At least that's one way you could do it off the top of my head. Also the pixels chosen for each thread should be done so with memory access locality in mind.
One way to avoid the "waiting for the slowest thread" problem and to keep every thread busy till the end (and thus shorten the total time needed). Have the workers calculate the iterations for 1 pixel, then ask for the next pixel not yet started, then feeding the pixels to those threads until you've run out of pixels to do. All threads will be kept busy until the last few pixels. That should still give a significant improvement (especially on screen-areas that are unbalanced)
Yes please I would be interested in seeing more about the intrinsics and performance advantages. I've been programming for years and had no idea that was even a thing you can do in C/C++
I watched a numberphile video about the mandelbrot set (and the key fact that any value past a radius of 2 explodes to infinity) and I managed to write the code for a multithreaded implementation (not thread pooled) without any external resources. Seeing the mandelbrot pop up on the screen for the first time was an amazing feeling haha. Anyways now that I've stumbled across your video I can't wait to learn more about and implement the thread pool/vector co-processing (I just got my BS CS degree and am disappointed I didn't get to learn more about this stuff). This is definitely one of the better videos I've come across when it comes to mandelbrot implementation, so thanks for that!
I would love to see how to do conversion to SIMD! :) Btw, my first C++ project was Mandelbrot Set generator and I did most of the mistakes that you pinpointed here. Now I'm gonna rewrite it after final exams. :D
This is a totally riveting video! Not only do you dive deep into the Mandelbrot fractal, to the point where a mighty 64-bit double is inadequate, but you also dive into unearthing the incredible power of the Intel CPUs. I completely fell in love with SSE and AVX when I finally decided to learn how to make use of them, but I have not yet ventured into threads and multi-cores. I know that I need to. It's on my bucket list. No, actually it is much more imminent than that. I will get into multi-core programming soon. This is a *must*.
Could you make a video about dynamically resizing variables (ones, that when they run out of precision - they double their length)? That would of course require defining all calculations and make program slower, but would enable us to zoom "indefinitely".
javid you angel! just as i'm starting my master's thesis having to write a program that will have to crunch through a lot of complex numbers you post this, thanks!
I wish to register interest in the SIMD code. Also I wish to acknowledge that the part where you talked about running in release mode versus debug mode was for my benefit after the (stupid) question I asked in your last video regarding the speed of decal rendering. Keep up the good work! Awesome channel! 👍🏻
Highly enjoyable video there. I first came across the Mandlebot set on my BBC Micro as there was a viewer included on a Disc User Magazine cover disc. It wasn't *quite* as fast as your routine in execution. You've made me want to break off from my regular programming project to render the Mandelbrot set, something I have never done. Just one for the nerdy bucket list. Great stuff, and thanks for making it.
I had a lot of fun making a Mandelbrot fractal Web app with WebGL by putting the fractal calculations in a fragment shader. Highly recommend it as a learning project.
Awesome video. It seems I've struck gold by finding your channel. I can already tell I will never regret subscribing to you! Don''t ever change your format! You hear???
Few ideas: Every time you scroll you're recalculating the whole frame. If you saved the iteration data and scrolled 2 rows of pixels you'd only need to actually calculate the extra 2 rows which have become visible. Hell you could precalculate a border after the screenspace pixels have been calculated in anticipation of the user scrolling. Tthere's a few ways certain pixels could be predicted. You get bands of given iteration values and never get lower values inside higher values. Therefor if you hit the highest iteration value you could find the outline of this shape and simply fill it in. You could then work your way out from that shape to the 2nd highest iteration value and repeat the process. This would probably be insanely complicated but in certain circumstances it could be a colossal speed boost. Mirroring. If the screen space passes through zero on the Y axis you could simply mirror the pixels above the line for a nearly 2x speed boost. Scale x2 . If you had a button to double the zoom then you've already calculated 25% of the pixels if it's lined up correctly. The same is true zooming out though it would need calculating slightly differently. Between these I'd imagine it could hit an effortless 4K 60fps.
In addition to the great walkthrough of optimizations, and the fantastic explanations of successes and failures of optimizations, I immensely enjoyed your near-giddiness when playing with your Mandelbrot Set Explorer. Clearly, you love coding, but I feel like in this video, it was extra-apparent and frankly infectious.
Normal people pay top money for this kind of knowledge, not to mention the unfathomable amount of work put in scripting and compiling these vids. It's baffling how clean, simple yet detailed you can craft these tutorials. My IQ went up exponentially since I started watching you. Never stop making these vids, you'll go down in history as a legend. Also, please drop a link where I can donate single amounts for poor wankers like myself.
@24:36 I'm sure in most cases using the standard libraries is the preferred way, but tracing this back down to the square root function cutting performance in 1/2 did gave me an appreciation for why Id software made their own faster (but less accurate) square root algorithm for the Quake engine.
I just started learning programming and I was dreaming of making a Mandelbrot Fractal plotter and then improving it bit by bit(going lower and lower towards hardware) to optimize it. and now you did a video on it, amazing !
Amazing. I was using intrinsics to see if I could outperform the quake 3 square root dilemma a while back and brought back wonderful memories. I cant wait to try this mandelbrot concept using OpenGL! Thank you~ 👏👏👏
@@javidx9 I think the communication between cpu and gpu over the PCI bus will eat up most of the performance that a GPU implementation would give you as long as you don't have a way to directly give a device pointer to the graphics library/engine.
@@Gelikafkal GPU compute is very much viable for anything that can take advantage of mass parallelisation, otherwise why would that functionality even exist?
To anyone interested: the CUDA C book has a bare bones implementation of the Julia/Mandelbrot sets, written in C. It's very intuitive to use, and the difference is GIGANTIC if your GPU is reasonably modern.
Yup, I reimplemented the Mandelbrot set using recursive CUDA, although it was not a live updating viewer (following a tutorial). Indeed the transfer of data between host and device (GPU) is usually costly, but it should be possible to move fractal data directly to the frame buffer without transfering everything back to the CPU. There is also an optimization for parallel implementations of the Mandelbrot set, which takes advantage of the fact, that all points in the set are connected. You can divide the set into different rectangles which are computed by different threads. First you only compute each pixel on the border of the rectangle. If none of the border pixels contain any part of the fractal, then you can skip the calculation of the pixels inside the rectangle (assuming you are not zoomed out too far).
Loved the demonstration of how good the compiler optimization is! Question: Is there an abs_squared method for std complex values? That could be used instead of your implementation and still avoid the square root.
Compilers are not always good at optimizing. They are smart to do small optimizations, but generally you can do better with higher level ones. And there are a lot of differences between compilers. Visual Studio compiler is known to be one of the worst at optimizing. But that's the same story as why you should use STL or not. Visual Studio follows the standards more tightly and has to add a lot of tests in the generated code.
Its such a joy to see you program this fractal generator and I would love to see more about avx, gpu calculations on this problem and threads, very nice walkthrough. Keep it up as always.
If you had kept reading the wiki you would be my micro-processor professor who seems to think reading slides counts as teaching. Thanks for teaching! Your channel is amazing!
Great video! An improvement would be to divide the screen into many thin rows instead. Rows are better than columns for two reasons: 1- Better cache locality for threads when they're working on a particular job 2- You can increase the number of rows arbitrarily whereas number columns have to be tuned such that you're as close to a multiple of 8 pixels per column as possible (otherwise you give up potenial AVX benefits). This is important because in order to reduce bubbling you want to increase the number of jobs so that the workload is more balanced among threads. Of course to do that you need to decrease the size of each row/column. Maybe even down to one single pixel row per job, because at given width (1280) thread signaling overhead will likely be negligible even then.
Loved this. I remember entering Basic programs to plot the Mandelbrot set back on 8 bit computers and tweaking them myself without understanding them properly and getting wonderfully strange results.
What a terrific find! I'm working on a project based on the Mandelbrot set. I fell in love with it when It was an assignment in college many years ago. What is crazy is that I came across your channel not for the Mandelbrot part but when trying to find a good C++ development environment for the Raspberry Pi. I chose WXWidgets, Code:: Blocks and MinGW. So, I found the channel vid on WxWidhets setup. Now here I've run into you twice on the same project. How cool is that? I've already compiled my Mandelbrot starting point in C#, my favorite environment. My end point is a Raspberry PI and a 7" touchscreen in a permanent case. It should allow the user to zoom in (and out). I want it to behave as a purpose-built, single function appliance. No desktop, no multiple-windows, no choosing the app to run, just plug it in to the wall power. For extra credit, I thought I'd see if I could output the display on the HDMI connector at the same time so someone can enjoy it on a monitor or the living room TV. This would be the Manderbrot-set-top-box. Haha. So, thanks twice for the great content! Dave San Francisco
Blimey. Really enjoyed that 😀I’m not even a C++ programmer only comfortable with C# but I learned a lot from this. Also enjoyed the style and presentation. Thanks. Subbed 😁
Very interesting that brute force allows a two/three order of magnitude acceleration. Personal computers have gotten so fast it is incredible. The usual method at accelerating Mandelbrot set rendering was to use a series approximation. You can render a single pixel at full precision (the anchor) and use small residual numbers for all other pixels, thus shaving off many orders of magnitude in time.
funny because when you started using thread I thought what could happen if you go to a stressful region of the fractal to the processor while recording and thanks you killed my curiosity
One of the first optimizations I like to try is to take advantage of "superscalarness" ie "pipelining". The goal here is to keep your ALU pipelines fed (no bubbles). Achieving it can be as simple as unrolling for loops (processing 4 pixels in one step of the for loop, for example). It can sometimes be shocking how much can be gained from this simple technique. To get the most out of this technique you must be mindful of "dependency chains" which prevent concurrent execution of code. There are cases where it can be faster to do some redundant calculations, if it increases concurrency.
Thanks for the video! Add my name to those interested in learning more about AVX and SIMD. On a different topic, but still related to the but related to rendering the Mandelbrot set, I’d love to see how to get past the resolution limit of 64-bit doubles so one could explore even deeper into the set. Thanks again!
I absolutely loved this AVX implementation! I might just try to implement that on a game engine I'm building for parallel processing inside thread pool. Thank you so much for your amazing video on optimization! PS: I'm actually ashamed that I hadn't used .wait on my code for the pool. I literally had my threads pooling constantly and wasting circles. lol
About the condition variable wait, you should wrap the unique_lock and the wait in a block to avoid holding that lock for too long (doesn't really matter in this case because each worker has its own mutex), and you should guard against spurious wakeups. You could also try other pimitives for launching the threads like a semaphore or a barrier. The barrier is the superior method to do this kind of waiting as it can actually wake up multiple threads at the time (which you can't with condition variables even with broadcast due to thundering herd related issues) and the completion function can both signal completion to the main thread and then wait for the next task. (edit) Also if you divided tasks by row instead of column you might get some gains because of cache prefetching and false sharing avoidance.
19:05 you could use std::fma(z, z, c); and there's a chance it will use the fma instruction which should be faster if available in hardware. Although, the compiler may have already figured this out.
Amazing as always. This is great! Really interesting. I would love to see a video explaining the vector co-processing (immtrin/SIMD/AVX) further. Thank you. Great work :-)
Awesome long video love it ! Fractal are indeed hypnotizing ! Also Yes i definitly want to see that SIMD optimisation. I was thinking, couple things we coudl do to optimise the display of this woudl be 1. cache the world position, zoom level and itteration count, if thoses havent changed we can just re-render that frame thats already baked in. 2. once thoses are calculated once, you can use that data (time for the thread to finish) to guess where and how you shoudl divide up your thread grid, maybe some area (like that big half screen with very little calculation shoudl be handled by only one thread and that one sliver of fractal shoudl be calculated by the other 31 threads. (IE : you hold the thread time to finish for each of them, and an average of them all. On each frame or itteration if the thread finish time is shorter then the average, it shoudl take some screen space from other threads (verically or horizontal) if its higher it shoud give some up. That way, threads kind of dynamically exchange their screen space depending on their own finish time and the average time it takes. ) Sorry for the long comment, just had to put that out there ! :P Cheers !
You can divide the screen into a grid that is 4x the amount of threads that you plan on using in the pool (or more). As each thread is "start"ed, it can read the position of the list based on the mux variable that is decremented at the time of reading it....and when the thread is done, it can get another one and another, etc...only stopping if the mux is below zero and decrement the "thread done" mux. So if a particular set of grids are fast, they can help finish off other parts. For more advanced approach, you can have that same thread alter the grid coordinates at that list position when it is finished for the next iteration before advancing.....the controller code literally only has to reset the grid mux to the number of grids in the list and "thread done" mux to the number of threads, and then print the screen and repeat when the 'thread done' mux hits zero (the test for a mux to be zero is faster than comparing to a non zero value). So in a 1280x760 with 32 worker threads, I would suggest a list of 608 grids of size 40x40 pixels each. This would give an average of each thread to work on 19 grids each round.
At about the 41:30 mark, you say that the vertical columns are from the thread groups. But actually, the reason those columns are there is because there is more precision in the Y variable than the X variable. That's just because the Y value is closer to 0 than the X, so more of the mantissa can be put in the small details.
Hey javidx9, love this video and your channel. Commenting here to say I am definitely interested in that video about the 256 bit registers and parallelism
Processor envy! I explored Mandelbrot on my '286 (without a coprocessor). Filling a single EGA screen, at higher zooms, could take hours! Those were the days... Yours is running plenty fast for us consumers, but, seeking to 'optimise' my slow version, I recall using the log() of the zoom (somehow) to 'dynamically' adjust the iteration threshold... It was all long, long ago... Probably should have been "inverse square" functionality, but log() performed well enough... I'm no mathematician...
TL;DR Bisqwit also did this, search up "bisqwit parallelism in c++" I know you already covered SIMD I would just like to point out that another one of my favorite youtubers also did a great series on this subject. Search up "bisqwit parallelism in c++". It is a great series that you could probably draw some inspiration from! Great video as always, thanks!
A splendid video! Thank you very much. It might be interesting to insert a generator function to be called in place of the Mandelbrot-specific code, with arguments that will create different kinds of fractals for exploration. I am certainly interested in seeing more specifics w.r.t. implementing the AVX extensions. Amusingly, the Mandelbrot Set is based on iterating quadratic polynomials, similar to those which describe population growth and are being used to gain some insights into our current global predicament.
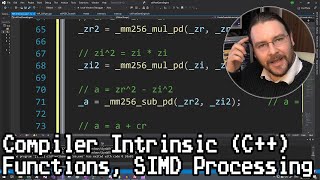
34:00 since "goto is evil" (as in "not as intuitive to see the loop at all times"), couldn't that "label: ....... if(...) goto label;" just be literally swapped out for "do{......}while(...)" to improve readability? or is there something weird about the mm256 stuff preventing that? afaik "do while" is pretty much the same as "label if goto" internally (just without a "{block}")? 46:30 "i just copied it in verbatim" couldn't you just call the one you've already implemented instead?
Seeing your code optimisation, (at about the 20 min mark) not working was one of the best parts of the video. In the past I would have done the same things that you did, move variable declarations outside the loop (would have probably missed the calculation optimisation though), but doing that troubles me, as it follows bad programming practice; separates point of declaration from use and increases the variable's scope. I've been hoping that the compiler would do lots of magic to allow me to write clear code that is optimised.
I have done the Fractal calculation on a 64 bit Linux system that has 2 processor cores with 6 calculation cores for each processor. I included the libomp Library and it performed very well.
11:10 It's not the metric that leads to unintuituve conclusions, it's how you present them. Whether you use FPS or elapsed time is irrelavant. Eg. "I made a change that added 100 ms to the elapsed time and this reduced the FPS by 50%" is equally as useless a comparison (other than knowing it decreased) as "I made a change that added 100 FPS and this increased the elapsed time by 50%" The unintuituve element you're trying to point out is that mixing additional and proportional comparisons leads to trivial statements. You solve this by not making additional+proportional comparisons, not by changing to another metric that has the exact same 'flaw'.
40:08 i was working on a similar problem and found just throwing 1000 threads at it was actually faster than trying to smartly divide the work between threads (i was using "greenthreads")
Thank you for the excellent video! I have a course next semester specifically regarding parallel processing and this was a great introduction into some of the techniques involved. And I would love to see the video mentioned about how to use a cpu's vector processor!
It would be nice to see a video on parallelism and avx, but your video are always super interesting. Please continue to do as you like in your videos, you are an amazing programmer
Man, this is awesome, the math performance calculations, I didn't know about that header file before. Yes I do want to see more videos about it and how you did the conversion. TIA.
I found this to be an excellent video and very enjoyable. As for the possibility of you making a video strictly based on the intrinsics library that is based on the CPU's extensions, I would truly be interested in it. I've always used Intel CPUs and I'm decently familiar with the x86 architecture, but never got to work with that part of the CPU's instruction set. Something else to consider... One possible optimization could be to calculate each iteration of the Mandelbrot set as a recursive Function Template. The compiler can precalculate the values for you. Then you can cache them repetitively for each loop, each iteration. Another technique would be similar to the concepts of how rendering pipelines work with a back buffer and a swap chain. You would write to a texture image that is the back buffer first, calculate the next iteration of values, and write it to the next texture to be rendered. Then have the swap chain present the image to the screen as a single texture image mapped to a quad that is the size of the screen using basic vertex and fragment(pixel) shaders. After that have a compute shader working in its own thread to calculate the next iteration based on the input of where the zoom took place within the image and the zoom amount and zoom level. This will then create the appropriate texture for the next iteration and feed it into the swap chain's back buffer. This ought to make it possible to have nearly an infinite amount of zooming levels with minimal overhead, providing the precision of a 64-bit unsigned integer to represent which zoom level we are on. This zoom level variable would, of course, end up being incremented or decremented accordingly depending on the direction of the next zoom provided by the user. Another thing to consider is that we do have double precision floating point variables to work with, but they shouldn't be needed. It should be possible to work with basic floating-point types, however, we have to know what level of scale we are at since this algorithm will end up generating a unique set of floating-point values for each iteration and zoom level. There may be a small amount of overhead as we would have to keep an extra floating-point value around to keep the state of the previous zoom level so that if the user does zoom out, we can easily reference the previous state to use that for the next set of calculations. It's almost the same thing you've already done in this video, but it would be adding a few different set of features, template metaprogramming to precalculate values for you and the usage of a graphics pipeline involving not just the basic shaders, the swap chain, and the back buffer, but to utilize compute shaders as well as giving us the ability to perform both pre and post-process calculations of data for the next iteration to be rendered.
Also note the set is symmetrical across the y axis at 0. The negative complex components match their corresponding positive point. So another optimization is just to calculate for positive complex components then reflect them into negative when that portion of the set is visible. Also, usually points which have exceeded max iterations are assumed inside the set are colored black -- have a go at that too, it makes for better plots.
Back in the days, about 93 I was working with massive parallelisation on multiple cups I remember there where big differences in how you iterated over the axles. This where related to the way the mmu swapped memory in and out (row or column oriented). Those where the days!









Arm-chair fractal geometry expert here. Was expecting to be bored, but was actually thrilled to see how your optimizations would perform. However I'm dispointed you didn't go on a 45 minute tangent about the existential implications of the fractal nature of life, the universe, and everything.
Well you see... What you forgot to take into account is that the fractal nature of things? Really boils down into one thing. And that thing? Is 42.
@@daedreaming6267 What he actually forgot to take into account is that there is no such things as the fractal nature of things, because things are not fractal in nature.
@@SpaghettiToaster in my point of view everything in nature is paralel (mirrored to infinite). We can't find the start since its infinit but we will be able to predict the future and change the lane of our evolution. In my mind a higher being developed us for God knows what purpose and to be paralel with that, someone else created them too, when our turn comes we will create other if we didn't already (animals).
@@emjizone I'm pretty sure that if you would iterate through every single color component of every single pixel in every single frame in every single video for every single video resolution as they are stored on the google servers you'd pretty much find the number 42 in all of them. And for the off-chance a video's video stream doesn't contain that number there are also the audio streams to sifter through... :)
Fractals are so named for their FRACTionAL dimensionality. for instance, the Mandelbrot set is neither 1D nor 2D but 1.72 dimensional. Fractals are characterized by their infinite perimeter but 0 area (or other applicable into)
The SIMD conversion would be super interesting I thing. I do like the low level part of things.
I would love to watch a SIMD video too!
Me too, i'd love to see it!
From my own testing with other problems (N-Body) you don't actually need to do much.
If you look here: gcc.gnu.org/projects/tree-ssa/vectorization.html
You'll see that GCC will actually automatically compile SIMD instructions if you compile past -O2, just make sure your code is in a vector/array or otherwise contiguous in memory. I'd imagine MSVC will do something very similar.
Yes PLEASE!!!
I'm at this point in my coding journey where I need to start getting the most performance I can and have started looking at parallelism so this would be very interesting
I also would very much like to see this.
More SIMD/AVX videos? Yes, please. I'd love to learn more about those, I only know the basics sadly. I pray to the compiler gods that they have mercy upon my soul and vectorize it automatically.
In most cases, they can't auto-vectorize. Usually because it can't be certain your pointers aren't aliasing, it thinks your stores may be changing the values of subsequent loads, so it is afraid to use SIMD, it changes the results. You can help a lot with "restrict" pointers (__restrict in g++). It can be absolutely sure there is no aliasing when you say they are restrict. Saying restrict in the signature's pointers means that the function cannot deal with the restrict pointers pointing to the same memory. Applying that restriction sets the compiler free to assume that its stores won't be feeding back into loads, allowing vectorization.
Instead of praying, you can profile and inspect compiler output. It's hard to speed up your code when you don't know where the bottlenecks are and you can help the compiler with autovectorising if you provide it with some hints. Writing code with intrinsics directly is not very maintainable, and better thing to do would be to look into parallel processing libraries that manage this complexity for you.
Also by looking at output assembly you're able to confirm that other optimisations are working such as instruction level paralellism
I hate to have to be the one to bring you the news, but there are no compiler gods. I SWEAR THAT I AM NOT MAKING THIS UP!
The AVX sounds interesting, I'd like to see more on it!
there is a youtuber named "what's a creel" that has some AVX in asm vids and also some VCL vids which is a vector library for c++
I'm a simple man. I see brute forcing and the Mandelbrot set, and I click on the video.
I'm a simpleton, I see overused formulaic cliche comments, and I join in.
@@kepeb1 Yeah, sorry, I didn't see any other comments and wanted to comment quickly, and that's the best I could do :p
I think the Mandelbrot Set and fractals in general are so engaging because they're the closest thing we have of visualizing eternal cosmic inflation, and that pokes at a very powerful memory of our collective consciousness. Also the pretty colors.
One does not simply brute-force into Mandelbrot...
very interesting, i'm rooting for the SIMD conversion video to come out :)
thanks and noted!
I'm in for a dedicated video on the SIMD conversion.
30:02 - should be "bit 255".
For everybody interested in the mandelbrot set and not deep in the subject i woukd suggest to search for "numberphile mandelbrot". Really nice videos ... have fun!
This is exactly the type of computation that GPUs are designed for, and you would likely see a huge performance improvement there.
In addition, while this approach generalizes fractal computation somewhat well, there are many techniques to be explored to optimize specifically the rendering of the mandelbrot set. For example, there is no need for the computation to go to the max iteration count for pixels which are clearly in the middle region and will go forever if possible.
There are also ways to scale the values of the floating points based on the zoom so that the issue of precision is not a limitation. This would allow you to zoom indefinitely.
Next, it does not make sense that 32 threads should have improved performance over 8 threads on your machine, since your 4 core processor can only effectively execute instructions from 8 threads simultaneously (two instruction streams per CPU core).
I would also say avoid busy waiting for threads in the thread pool. Simply deschedule these threads if they do not have work to do, and make them runnable when they should run. It is perhaps possible that this is handled somehow by the OS/Compiler (if a loop is seen to jump to the previous instruction and the condition is not met, the processor may be able to dynamically see that no useful progress can be made and the thread will yield to another?), although unlikely. While it is a rule of thumb to avoid thread busy waiting at all costs on a single core machine, there are reasons why busy waiting may be an appropriate solution in a multi-core system: conditions can change while a thread is busy waiting due to the behavior of other threads, and the system call to make the thread runnable can be avoided. So the tradeoffs between these options should be weighed. Also your solution to thread synchronization (atomic counter) can be replaced more elegantly with a barrier or other synchronization primitive.
An interesting experiment for the approach you have taken would be to disable the optimization flags of the compiler, so that simple code optimizations such as loop unrolling or strength reduction can actually be measured.
With the way he was doing things it absolutely makes sense that 32 threads would improve performance over 8 threads, what is probably tripping you up is that the number of threads isn't the reason it'll be faster (because more threads doesn't really help as you probably correctly concluded), but rather it is faster because he divides the area up based on the number of threads thus reducing the time it takes to process the most computationally expensive section, which with only 32 sections is likely still a major bottleneck. With just 8 threads and 8 sections whenever a thread completes its section then the hardware thread will sit idle until the others are all complete, but with 32 threads and 32 sections whenever a section is completed another software thread can utilise the hardware thread that was freed up, and the maximum time to complete a section is reduced to a quarter of what it would take with 8 sections allowing it to be up to nearly 4 times faster in the worst case scenario for 8 threads. However it is entirely dependent on the complexity of the sections and how well balanced they are, if all 8 sections are equally complex then there will be no performance benefit running 32 threads/sections, and 32 threads/sections may even be marginally slower in that case.
Basically the more sections there are the better it can load balance and keep the CPU fully utilised, at least up to the point where the overhead of more threads starts negating the better utilisation.
AusSkiller is right. You're speaking of a better but way more complex implementation. Javi's goal is to use a minimalist implementation that still makes a good use (although not optimal) of the cores. For his algorithm makes sense to use more threads because it reduces the overall time to join them.
@@AusSkiller I see your point. The load balancing is the key issue here.
For each thread to have somewhat equal work, each pixel should have an estimated cost and the total cost of the pixels for each thread should be similar.
At least that's one way you could do it off the top of my head.
Also the pixels chosen for each thread should be done so with memory access locality in mind.
yep, got 60fps all the way to float precision limit on my opengl implementation of the julia set
can you tell me how to overcome float precision ?
One way to avoid the "waiting for the slowest thread" problem and to keep every thread busy till the end (and thus shorten the total time needed). Have the workers calculate the iterations for 1 pixel, then ask for the next pixel not yet started, then feeding the pixels to those threads until you've run out of pixels to do. All threads will be kept busy until the last few pixels.
That should still give a significant improvement (especially on screen-areas that are unbalanced)
Yes please I would be interested in seeing more about the intrinsics and performance advantages. I've been programming for years and had no idea that was even a thing you can do in C/C++
I watched a numberphile video about the mandelbrot set (and the key fact that any value past a radius of 2 explodes to infinity) and I managed to write the code for a multithreaded implementation (not thread pooled) without any external resources. Seeing the mandelbrot pop up on the screen for the first time was an amazing feeling haha. Anyways now that I've stumbled across your video I can't wait to learn more about and implement the thread pool/vector co-processing (I just got my BS CS degree and am disappointed I didn't get to learn more about this stuff). This is definitely one of the better videos I've come across when it comes to mandelbrot implementation, so thanks for that!
Wow! It's incridible! Thanks for this video
I would love to see how to do conversion to SIMD! :)
Btw, my first C++ project was Mandelbrot Set generator and I did most of the mistakes that you pinpointed here. Now I'm gonna rewrite it after final exams. :D
This is a totally riveting video! Not only do you dive deep into the Mandelbrot fractal, to the point where a mighty 64-bit double is inadequate, but you also dive into unearthing the incredible power of the Intel CPUs. I completely fell in love with SSE and AVX when I finally decided to learn how to make use of them, but I have not yet ventured into threads and multi-cores. I know that I need to. It's on my bucket list. No, actually it is much more imminent than that. I will get into multi-core programming soon. This is a *must*.
double isn't that mighty in the Mandelbrot set
Could you make a video about dynamically resizing variables (ones, that when they run out of precision - they double their length)?
That would of course require defining all calculations and make program slower, but would enable us to zoom "indefinitely".
Variables can't change length, but you can replace objects with bigger objects. There are arbitrary-precision arithmetic libraries for this purpose
javid you angel! just as i'm starting my master's thesis having to write a program that will have to crunch through a lot of complex numbers you post this, thanks!
I wish to register interest in the SIMD code. Also I wish to acknowledge that the part where you talked about running in release mode versus debug mode was for my benefit after the (stupid) question I asked in your last video regarding the speed of decal rendering. Keep up the good work! Awesome channel! 👍🏻
"quite advance for this channel". My god, he's holding back his full power.
Highly enjoyable video there. I first came across the Mandlebot set on my BBC Micro as there was a viewer included on a Disc User Magazine cover disc. It wasn't *quite* as fast as your routine in execution.
You've made me want to break off from my regular programming project to render the Mandelbrot set, something I have never done. Just one for the nerdy bucket list. Great stuff, and thanks for making it.
I'm shocked by how smart you and the other commenters are. Absolutely incredible if anyone else can follow along.
I’d also love to see this extended into using the GPU.
I had a lot of fun making a Mandelbrot fractal Web app with WebGL by putting the fractal calculations in a fragment shader. Highly recommend it as a learning project.
Awesome video. It seems I've struck gold by finding your channel. I can already tell I will never regret subscribing to you!
Don''t ever change your format! You hear???
Few ideas:
Every time you scroll you're recalculating the whole frame. If you saved the iteration data and scrolled 2 rows of pixels you'd only need to actually calculate the extra 2 rows which have become visible. Hell you could precalculate a border after the screenspace pixels have been calculated in anticipation of the user scrolling.
Tthere's a few ways certain pixels could be predicted. You get bands of given iteration values and never get lower values inside higher values. Therefor if you hit the highest iteration value you could find the outline of this shape and simply fill it in. You could then work your way out from that shape to the 2nd highest iteration value and repeat the process. This would probably be insanely complicated but in certain circumstances it could be a colossal speed boost.
Mirroring. If the screen space passes through zero on the Y axis you could simply mirror the pixels above the line for a nearly 2x speed boost.
Scale x2
. If you had a button to double the zoom then you've already calculated 25% of the pixels if it's lined up correctly. The same is true zooming out though it would need calculating slightly differently.
Between these I'd imagine it could hit an effortless 4K 60fps.
maybe real time ray tracing??? 😄 I am trying to do it rn but I'd love your explanation and tricks!
Its a popular request for sure!
In addition to the great walkthrough of optimizations, and the fantastic explanations of successes and failures of optimizations, I immensely enjoyed your near-giddiness when playing with your Mandelbrot Set Explorer. Clearly, you love coding, but I feel like in this video, it was extra-apparent and frankly infectious.
this is fascinating, immensely helpful for scientific calculation coders
Normal people pay top money for this kind of knowledge, not to mention the unfathomable amount of work put in scripting and compiling these vids. It's baffling how clean, simple yet detailed you can craft these tutorials. My IQ went up exponentially since I started watching you. Never stop making these vids, you'll go down in history as a legend. Also, please drop a link where I can donate single amounts for poor wankers like myself.
@24:36 I'm sure in most cases using the standard libraries is the preferred way, but tracing this back down to the square root function cutting performance in 1/2 did gave me an appreciation for why Id software made their own faster (but less accurate) square root algorithm for the Quake engine.
I just started learning programming and I was dreaming of making a Mandelbrot Fractal plotter and then improving it bit by bit(going lower and lower towards hardware) to optimize it.
and now you did a video on it, amazing !
Amazing. I was using intrinsics to see if I could outperform the quake 3 square root dilemma a while back and brought back wonderful memories. I cant wait to try this mandelbrot concept using OpenGL! Thank you~ 👏👏👏
And now, Implemented on the GPU? :)
Well that is indeed the next phase is suppose, though I reckon there is a lot to squeeze out of the CPU yet!
@@javidx9 I think the communication between cpu and gpu over the PCI bus will eat up most of the performance that a GPU implementation would give you as long as you don't have a way to directly give a device pointer to the graphics library/engine.
@@Gelikafkal GPU compute is very much viable for anything that can take advantage of mass parallelisation, otherwise why would that functionality even exist?
To anyone interested: the CUDA C book has a bare bones implementation of the Julia/Mandelbrot sets, written in C. It's very intuitive to use, and the difference is GIGANTIC if your GPU is reasonably modern.
Yup, I reimplemented the Mandelbrot set using recursive CUDA, although it was not a live updating viewer (following a tutorial).
Indeed the transfer of data between host and device (GPU) is usually costly, but it should be possible to move fractal data directly to the frame buffer without transfering everything back to the CPU.
There is also an optimization for parallel implementations of the Mandelbrot set, which takes advantage of the fact, that all points in the set are connected. You can divide the set into different rectangles which are computed by different threads. First you only compute each pixel on the border of the rectangle. If none of the border pixels contain any part of the fractal, then you can skip the calculation of the pixels inside the rectangle (assuming you are not zoomed out too far).
Such a fun video! Didn't even feel like it was almost an hour long. Thanks for the content! Subscribed :)
Cheers!
Loved the demonstration of how good the compiler optimization is! Question: Is there an abs_squared method for std complex values? That could be used instead of your implementation and still avoid the square root.
That would be a dot product of the complex number against itself or multiplication of the number by a complex conjugate of itself.
Compilers are not always good at optimizing. They are smart to do small optimizations, but generally you can do better with higher level ones. And there are a lot of differences between compilers. Visual Studio compiler is known to be one of the worst at optimizing. But that's the same story as why you should use STL or not. Visual Studio follows the standards more tightly and has to add a lot of tests in the generated code.
std::norm(std::complex)
The accidental video recording lag near the end though lmao. Great video as always!
lol, hey its an interesting and very real side effect, so I thought it had value and kept it in :D
Its such a joy to see you program this fractal generator and I would love to see more about avx, gpu calculations on this problem and threads, very nice walkthrough. Keep it up as always.
@32:54 I think it would be neat to look at the conversion process!
yeah, me too! noted!
If you had kept reading the wiki you would be my micro-processor professor who seems to think reading slides counts as teaching. Thanks for teaching! Your channel is amazing!
Great performance! Really impressive what you can get out of the CPU.
+1 just for the profile pic. Very apropo.
Great video! An improvement would be to divide the screen into many thin rows instead. Rows are better than columns for two reasons: 1- Better cache locality for threads when they're working on a particular job 2- You can increase the number of rows arbitrarily whereas number columns have to be tuned such that you're as close to a multiple of 8 pixels per column as possible (otherwise you give up potenial AVX benefits). This is important because in order to reduce bubbling you want to increase the number of jobs so that the workload is more balanced among threads. Of course to do that you need to decrease the size of each row/column. Maybe even down to one single pixel row per job, because at given width (1280) thread signaling overhead will likely be negligible even then.
Awesome video man. Actually I was watching another video about the "Mandelbrot Conjunction" and I found it quite interesting to analyze.
Cheers Oscar, they just never get boring - I really find Mandelbulbs quite interesting
Loved this. I remember entering Basic programs to plot the Mandelbrot set back on 8 bit computers and tweaking them myself without understanding them properly and getting wonderfully strange results.
What a terrific find! I'm working on a project based on the Mandelbrot set. I fell in love with it when It was an assignment in college many years ago. What is crazy is that I came across your channel not for the Mandelbrot part but when trying to find a good C++ development environment for the Raspberry Pi. I chose WXWidgets, Code:: Blocks and MinGW. So, I found the channel vid on WxWidhets setup. Now here I've run into you twice on the same project. How cool is that?
I've already compiled my Mandelbrot starting point in C#, my favorite environment.
My end point is a Raspberry PI and a 7" touchscreen in a permanent case. It should allow the user to zoom in (and out). I want it to behave as a purpose-built, single function appliance. No desktop, no multiple-windows, no choosing the app to run, just plug it in to the wall power.
For extra credit, I thought I'd see if I could output the display on the HDMI connector at the same time so someone can enjoy it on a monitor or the living room TV. This would be the Manderbrot-set-top-box. Haha.
So, thanks twice for the great content!
Dave
San Francisco
The value of this video is incredible, thank you
Definitely interested in seeing that conversion. This is one of the best CS videos i've seen in quite a while.
Blimey. Really enjoyed that 😀I’m not even a C++ programmer only comfortable with C# but I learned a lot from this. Also enjoyed the style and presentation. Thanks. Subbed 😁
Thank you Jim, much appreciated!
Great video thank you. I really liked the pacing (as always) and while not a c++ programmer in any capacity I learned quite a lot as well.
Absolutely! I'd love to see a video explaining the conversion to SIMD data types.
Best fractal programming video on youtube
Very interesting that brute force allows a two/three order of magnitude acceleration. Personal computers have gotten so fast it is incredible. The usual method at accelerating Mandelbrot set rendering was to use a series approximation. You can render a single pixel at full precision (the anchor) and use small residual numbers for all other pixels, thus shaving off many orders of magnitude in time.
Just imagine these fractals as continents in a solar-system-sized ocean.
Literally breath-taking.
funny because when you started using thread I thought what could happen if you go to a stressful region of the fractal to the processor while recording
and thanks you killed my curiosity
One of the first optimizations I like to try is to take advantage of "superscalarness" ie "pipelining". The goal here is to keep your ALU pipelines fed (no bubbles). Achieving it can be as simple as unrolling for loops (processing 4 pixels in one step of the for loop, for example). It can sometimes be shocking how much can be gained from this simple technique. To get the most out of this technique you must be mindful of "dependency chains" which prevent concurrent execution of code. There are cases where it can be faster to do some redundant calculations, if it increases concurrency.
Consider this my shout-out for more vector processing instruction videos :3
Thanks for the video! Add my name to those interested in learning more about AVX and SIMD. On a different topic, but still related to the but related to rendering the Mandelbrot set, I’d love to see how to get past the resolution limit of 64-bit doubles so one could explore even deeper into the set. Thanks again!
I enjoy and appreciate all of your content. I would really like a video on intrinsics.
I absolutely loved this AVX implementation!
I might just try to implement that on a game engine I'm building for parallel processing inside thread pool.
Thank you so much for your amazing video on optimization!
PS: I'm actually ashamed that I hadn't used .wait on my code for the pool. I literally had my threads pooling constantly and wasting circles. lol
About the condition variable wait, you should wrap the unique_lock and the wait in a block to avoid holding that lock for too long (doesn't really matter in this case because each worker has its own mutex), and you should guard against spurious wakeups.
You could also try other pimitives for launching the threads like a semaphore or a barrier. The barrier is the superior method to do this kind of waiting as it can actually wake up multiple threads at the time (which you can't with condition variables even with broadcast due to thundering herd related issues) and the completion function can both signal completion to the main thread and then wait for the next task.
(edit) Also if you divided tasks by row instead of column you might get some gains because of cache prefetching and false sharing avoidance.
19:05 you could use std::fma(z, z, c); and there's a chance it will use the fma instruction which should be faster if available in hardware. Although, the compiler may have already figured this out.
Amazing as always.
This is great! Really interesting. I would love to see a video explaining the vector co-processing (immtrin/SIMD/AVX) further. Thank you. Great work :-)
luv ur vids very informational :) i've learned a lot
i would love to see a series on possibly making your own basic coding language in C++
It's certainly an interesting idea! If I find a need for such a language then it may make a good series
Awesome long video love it ! Fractal are indeed hypnotizing ! Also Yes i definitly want to see that SIMD optimisation.
I was thinking, couple things we coudl do to optimise the display of this woudl be
1. cache the world position, zoom level and itteration count, if thoses havent changed we can just re-render that frame thats already baked in.
2. once thoses are calculated once, you can use that data (time for the thread to finish) to guess where and how you shoudl divide up your thread grid, maybe some area (like that big half screen with very little calculation shoudl be handled by only one thread and that one sliver of fractal shoudl be calculated by the other 31 threads. (IE : you hold the thread time to finish for each of them, and an average of them all. On each frame or itteration if the thread finish time is shorter then the average, it shoudl take some screen space from other threads (verically or horizontal) if its higher it shoud give some up. That way, threads kind of dynamically exchange their screen space depending on their own finish time and the average time it takes. )
Sorry for the long comment, just had to put that out there ! :P Cheers !
Yeah, dividing screen to threads by bitmasks should do the trick. Didn't think of it. Thanks, gonna implement it in my own Mandelbrot generator :)
I come to this channel whenever I want to feel stupid.
You can divide the screen into a grid that is 4x the amount of threads that you plan on using in the pool (or more). As each thread is "start"ed, it can read the position of the list based on the mux variable that is decremented at the time of reading it....and when the thread is done, it can get another one and another, etc...only stopping if the mux is below zero and decrement the "thread done" mux. So if a particular set of grids are fast, they can help finish off other parts. For more advanced approach, you can have that same thread alter the grid coordinates at that list position when it is finished for the next iteration before advancing.....the controller code literally only has to reset the grid mux to the number of grids in the list and "thread done" mux to the number of threads, and then print the screen and repeat when the 'thread done' mux hits zero (the test for a mux to be zero is faster than comparing to a non zero value).
So in a 1280x760 with 32 worker threads, I would suggest a list of 608 grids of size 40x40 pixels each. This would give an average of each thread to work on 19 grids each round.
At about the 41:30 mark, you say that the vertical columns are from the thread groups. But actually, the reason those columns are there is because there is more precision in the Y variable than the X variable. That's just because the Y value is closer to 0 than the X, so more of the mantissa can be put in the small details.
THE INTRO SOUND is finally better!! thanks! hahah :)
Hey javidx9, love this video and your channel. Commenting here to say I am definitely interested in that video about the 256 bit registers and parallelism
Wow this video and in general your channel are a great motivation to keep programming and exploring the field :)
Thank you Crystal Music!
Processor envy!
I explored Mandelbrot on my '286 (without a coprocessor). Filling a single EGA screen, at higher zooms, could take hours! Those were the days...
Yours is running plenty fast for us consumers, but, seeking to 'optimise' my slow version, I recall using the log() of the zoom (somehow) to 'dynamically' adjust the iteration threshold... It was all long, long ago... Probably should have been "inverse square" functionality, but log() performed well enough... I'm no mathematician...
TL;DR Bisqwit also did this, search up "bisqwit parallelism in c++"
I know you already covered SIMD I would just like to point out that another one of my favorite youtubers also did a great series on this subject. Search up "bisqwit parallelism in c++". It is a great series that you could probably draw some inspiration from!
Great video as always, thanks!
SIMD definitively deserves at least one video
Please do more like this. I learned a lot!
A splendid video! Thank you very much. It might be interesting to insert a generator function to be called in place of the Mandelbrot-specific code, with arguments that will create different kinds of fractals for exploration. I am certainly interested in seeing more specifics w.r.t. implementing the AVX extensions.
Amusingly, the Mandelbrot Set is based on iterating quadratic polynomials, similar to those which describe population growth and are being used to gain some insights into our current global predicament.
I too would be interested in the SIMD conversion video. I'm always fascinated by low level stuff and would happily watch the video.
Really enjoyed this, thanks. I'm all for hearing about how the AVX-256 works.
Big thumb here. I find this tube content rather elegant with some funky twist in it. ;}
34:00 since "goto is evil" (as in "not as intuitive to see the loop at all times"), couldn't that "label: ....... if(...) goto label;" just be literally swapped out for "do{......}while(...)" to improve readability? or is there something weird about the mm256 stuff preventing that? afaik "do while" is pretty much the same as "label if goto" internally (just without a "{block}")?
46:30 "i just copied it in verbatim" couldn't you just call the one you've already implemented instead?
thanks for this! it explains a lot of questions i had regarding sse and simd
please do more of this, optimization is my jam
Awesome video. Great touching on the different techniques available, never even knew about SIMD! 👍
This may be the most C++ video in a while.
Seeing your code optimisation, (at about the 20 min mark) not working was one of the best parts of the video. In the past I would have done the same things that you did, move variable declarations outside the loop (would have probably missed the calculation optimisation though), but doing that troubles me, as it follows bad programming practice; separates point of declaration from use and increases the variable's scope. I've been hoping that the compiler would do lots of magic to allow me to write clear code that is optimised.
I have done the Fractal calculation on a 64 bit Linux system that has 2 processor cores with 6 calculation cores for each processor. I included the libomp Library and it performed very well.
Definitely your best video.
11:10
It's not the metric that leads to unintuituve conclusions, it's how you present them. Whether you use FPS or elapsed time is irrelavant.
Eg. "I made a change that added 100 ms to the elapsed time and this reduced the FPS by 50%" is equally as useless a comparison (other than knowing it decreased) as "I made a change that added 100 FPS and this increased the elapsed time by 50%"
The unintuituve element you're trying to point out is that mixing additional and proportional comparisons leads to trivial statements. You solve this by not making additional+proportional comparisons, not by changing to another metric that has the exact same 'flaw'.
40:08 i was working on a similar problem and found just throwing 1000 threads at it was actually faster than trying to smartly divide the work between threads (i was using "greenthreads")
Really? That's interesting!
Thank you for the excellent video! I have a course next semester specifically regarding parallel processing and this was a great introduction into some of the techniques involved. And I would love to see the video mentioned about how to use a cpu's vector processor!
It would be nice to see a video on parallelism and avx, but your video are always super interesting. Please continue to do as you like in your videos, you are an amazing programmer
"I assumed I could do a better job than the compiler. I thought I was smart. I now know one doesn't mess with the compiler gods." Hahahaha love it!!
Man, this is awesome, the math performance calculations, I didn't know about that header file before.
Yes I do want to see more videos about it and how you did the conversion.
TIA.
This was really interesting. Thank you for making the video.
Hi David, the vids are awesome, and I loved them! You are supposed to be earning more subs!
I found this to be an excellent video and very enjoyable. As for the possibility of you making a video strictly based on the intrinsics library that is based on the CPU's extensions, I would truly be interested in it. I've always used Intel CPUs and I'm decently familiar with the x86 architecture, but never got to work with that part of the CPU's instruction set.
Something else to consider...
One possible optimization could be to calculate each iteration of the Mandelbrot set as a recursive Function Template. The compiler can precalculate the values for you. Then you can cache them repetitively for each loop, each iteration.
Another technique would be similar to the concepts of how rendering pipelines work with a back buffer and a swap chain. You would write to a texture image that is the back buffer first, calculate the next iteration of values, and write it to the next texture to be rendered. Then have the swap chain present the image to the screen as a single texture image mapped to a quad that is the size of the screen using basic vertex and fragment(pixel) shaders. After that have a compute shader working in its own thread to calculate the next iteration based on the input of where the zoom took place within the image and the zoom amount and zoom level.
This will then create the appropriate texture for the next iteration and feed it into the swap chain's back buffer. This ought to make it possible to have nearly an infinite amount of zooming levels with minimal overhead, providing the precision of a 64-bit unsigned integer to represent which zoom level we are on. This zoom level variable would, of course, end up being incremented or decremented accordingly depending on the direction of the next zoom provided by the user.
Another thing to consider is that we do have double precision floating point variables to work with, but they shouldn't be needed. It should be possible to work with basic floating-point types, however, we have to know what level of scale we are at since this algorithm will end up generating a unique set of floating-point values for each iteration and zoom level. There may be a small amount of overhead as we would have to keep an extra floating-point value around to keep the state of the previous zoom level so that if the user does zoom out, we can easily reference the previous state to use that for the next set of calculations.
It's almost the same thing you've already done in this video, but it would be adding a few different set of features, template metaprogramming to precalculate values for you and the usage of a graphics pipeline involving not just the basic shaders, the swap chain, and the back buffer, but to utilize compute shaders as well as giving us the ability to perform both pre and post-process calculations of data for the next iteration to be rendered.
Javidx9 brute-forcing youtube compression algorithm, great video!
Also note the set is symmetrical across the y axis at 0. The negative complex components match their corresponding positive point. So another optimization is just to calculate for positive complex components then reflect them into negative when that portion of the set is visible.
Also, usually points which have exceeded max iterations are assumed inside the set are colored black -- have a go at that too, it makes for better plots.
Back in the days, about 93 I was working with massive parallelisation on multiple cups I remember there where big differences in how you iterated over the axles. This where related to the way the mmu swapped memory in and out (row or column oriented). Those where the days!
For millenia, every kid:
"meh, math seems like boring black and whit..."
BAM
Mandelbrot entered the chat.
YES!!! INTERESTED!!!