I'd say without any doubt that Professor Strang is the best Algebra professor in the entire world. I'm sure he has helped tons of students all around the world to understand the beauty of algebra
After reading so many texts finally some actual geometric interpretation of L1 and L2 ...he explains it so beautifully.Came here only to understand definition but his charsima made me watch whole 50 mins
Teaching norms with their R2 pictures is just brilliant. So much insight, even emerging while teaching (sparsity of L1 optimum: it's on the axis!!). An absolute joy to watch & learn from
After passing the linear algebra course, i was kind of disappointed no need to see your lecture again . but for data analysis u came again in a HD resolution. So glad to see you professor .
"You start from the origin and you blow up the norm until you get a point on the line that satisfies your constraint, and because you are blowing up the norm, when it hit first, that's the smallest blow up possible, that's min, that's the guy that minimize" (31:23-31:42) that's 2-D optimization in a nutshell...clear and simple, thanks very much Professor Strang..
Probably, this has been said before, so forgive me if I repeat someone else's words. I acknowledge here, that professor Strang is a good pedagogue. I learnt some math over the years. I completely support the use of the geometrical visualization of some properties, as it is a learning need. I can say that for me it is easy to see how to derive properties like the one he gave for the assignment on the Frobenius norm. I say this, because I may not be the only one thinking it and I wanted to tell those people that there is more to math here. Only recently, I understood the huge degree of humility and teaching wit that it takes one to pass one's knowledge along. It requires to pretend or to honestly feel you are no better than any of your students. For instance, as I could witness here, Pr Strang shared with his students the latest cool research topics as if they were his colleagues, he thanked them for contributing to the course by giving out some answers. That's what allows him to successfully challenge them in solving some assignments, like the Frobenius norm - SVD problem. All of it is summarized by Gilbert himself at the very end in 48:12, when he explains his view of his relationship with the students (such as "We have worked to do!", an honest use of the pronoun "we" by the lecturer). This 48 min long lecture, honestly impressed me in this regard. Today, I had the privilege of a double lecture: one in math (that could have been compressed to 15 min, since most proofs were skipped) and one in being a better passer of knowledge (that could be extended to 10+ years). Hat off!
Great point on comparing matrix Nuclear norm with vector L1 norm, which tends to find the most sparse winning vector. I guess the matrix Nuclear norm may tend to find 'least' weights during the optimization.
I highly recommend doing the Frobenius norm proof he mentions. It is elegant and uses some nice properties of linear algebra. If you took 18.06 (or watched the lectures) using the column & row picture of matrix multiplication really helps. I'll finalize my proof and post a link - hopefully I didn't make a mistake ;)
Compelling lecture (as always), but I'm unsettled about one thing: much of it is based on the fact that the first singular vector of A is the maximizing x in the definition of ||A||2. However, this fact just seems to be mentioned without proof or argument, and accordingly it doesn't feel as though the proof that ||A||2 = sigma1 is complete. Thoughts?
I agree. I can give a proof sketch: 1. A = U Σ V^t by the SVD. 2. To maximize ||Σy|| for a unit vector y, we would choose y to have all 0's except for a 1 in the position multiplying the largest value in the diagonal matrix Σ, which is sigma1. This effectively scales every component of y by sigma1 (all the other components are 0). Any other choice of y results in some component of y being scaled by a value less than sigma1, and no component scaled by more than sigma1. 3. U is orthonormal, so ||Uz|| = ||z|| 4. 1 and 3 give us ||Ax|| = ||U Σ V^t x|| = ||Σ V^t x|| 5. Assume ||x|| = 1. V^t is orthonormal, so ||V^t x|| = 1. 6. Thus, the maximizing value of x satisfies V^t x = y for the y we found in step 2. 7. This gives x = v1, and ||Ax|| = sigma1. 8. Since the L2 norm of A is the maximum value of ||Ax||/||x|| over all x's, the L2 norm of A is sigma1 (small leap here, but straightforward)
Max ||Ax||/||x||=Max ||Akx||/||kx||=Max ||Ax||/||x||, ||x||=1. So you can think of a unit circle ||x||=1 with ||Ax|| plotted on the radius which might look like a circle and ellipse with a point on the Ellipse being at Max ||Ax||/||x||.
How do we actually see what sigma1 is the maximum blow-up factor and what v1 is the vector what gets blown up the most? Because i initially thought it would be the first eigenvector, and then it would make sense, but then i realised what sigma is not an eigenvalue after professor said it and i'm struggling a bit with imagening what's happening here
Recall the picture Prof. Strang draw when explaining SVD. Here's a refresher (in slide #25): ocw.mit.edu/resources/res-18-010-a-2020-vision-of-linear-algebra-spring-2020/videos/MITRES_18_010S20_LA_Slides.pdf As Prof. Strang mentioned, U and V only perform rotation or possible reflection of x, which does not changes the norm of x. It is Sigma that is responsible for stretching and among those sigma1 is the biggest and it is therefore the "maximum blow-up factor". I hope this helps.
There are no lectures notes available for this course; that is because the book (Strang, Gilbert. Linear Algebra and Learning from Data. Wellesley-Cambridge Press, 2018. ISBN: 9780692196380) is basically the lecture notes for the course. See the course on MIT OpenCourseWare for more info and materials at: ocw.mit.edu/18-065S18. Best wishes on your studies!
I've watched the first 6 videos without difficulty, but I'm confused by the definition and geometric meaning of different norms. Could anyone please tell me which textbook I should read to help me understand? Thanks for your helping!
When you earn 20 dollars, you can donate 1/2 dollars. When you earn 20,000 dollars, you can donate 100 dollars. When you earn 2 billion, you'll leave here and forget about donation for ever.
I can give available information . The lecture here connects the optimization problem with eigenvectors. But sorry , the lecture in Russian))) ua-cam.com/video/W5JLSKcuaQo/v-deo.html
The phenomenon he mentioned in the first 5 minutes is a very interesting psychological question. Is it about the sequential effects of decision making? Anyone knows the field? Please feel free to share some papers. Thank you.
L2 norm for a vector is the distance from origin. Since the candidate vectors have to be on the constraint line, the problem (find a vector that subject to the constraint minimize L2 norm) became "which point on that line has smallest distance to the origin".



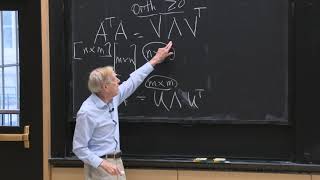






In times of Covid, I hope this makes young people realize why older people are so important. Long live Prof Strang.
In times of Covid I hear in the background of the class someone sneezing and nose-blowing and it gives me the chills ...
He is human equivalent of God
@@somadityasantra5572 Are you saying he doesn't exist?
@@godfreypigott U are assuming that I mean God does not exist. But how can u prove or disprove that?
@@somadityasantra5572 There is no "god" - that is a given. So by saying he is the "human equivalent of god" you are saying that he doesn't exist.
I'd say without any doubt that Professor Strang is the best Algebra professor in the entire world. I'm sure he has helped tons of students all around the world to understand the beauty of algebra
Long live your kindly,mild professor
Best linear algebra course ever! Best wishes for Prof. Strang's health during this horrible pandemic
What a smart and humble person! Long live Prof. Strang!
After reading so many texts finally some actual geometric interpretation of L1 and L2 ...he explains it so beautifully.Came here only to understand definition but his charsima made me watch whole 50 mins
Exactly the same for me
Ahah I am in the same situation.
the same for me 2222222
EXACTLY the same!!!
31:20 intuitive explanation of how the norm choice effects the minimization problem was eye opening to me
This man does not stop giving, many thanks.
Teaching norms with their R2 pictures is just brilliant. So much insight, even emerging while teaching (sparsity of L1 optimum: it's on the axis!!). An absolute joy to watch & learn from
This lecture needs to reach more people asap.
Total respect for the Professor!
LONG LIVE PROFESSOR STRANG!!!!!
After passing the linear algebra course, i was kind of disappointed no need to see your lecture again . but for data analysis u came again in a HD resolution. So glad to see you professor .
I'm currently reading Calculus by Dr. Strang. One of the best books on the subject I have ever come across.
"You start from the origin and you blow up the norm until you get a point on the line that satisfies your constraint, and because you are blowing up the norm, when it hit first, that's the smallest blow up possible, that's min, that's the guy that minimize" (31:23-31:42) that's 2-D optimization in a nutshell...clear and simple, thanks very much Professor Strang..
3D as well, no?
DR. Strang, thank you explaining and analyzing Norms. I understand this lecture from start to finish.
Love this man, thanks MIT for looking out for us!
Feeling so emotional watching him teaching at the age of 84😢
Probably, this has been said before, so forgive me if I repeat someone else's words.
I acknowledge here, that professor Strang is a good pedagogue. I learnt some math over the years. I completely support the use of the geometrical visualization of some properties, as it is a learning need. I can say that for me it is easy to see how to derive properties like the one he gave for the assignment on the Frobenius norm. I say this, because I may not be the only one thinking it and I wanted to tell those people that there is more to math here.
Only recently, I understood the huge degree of humility and teaching wit that it takes one to pass one's knowledge along. It requires to pretend or to honestly feel you are no better than any of your students. For instance, as I could witness here, Pr Strang shared with his students the latest cool research topics as if they were his colleagues, he thanked them for contributing to the course by giving out some answers. That's what allows him to successfully challenge them in solving some assignments, like the Frobenius norm - SVD problem. All of it is summarized by Gilbert himself at the very end in 48:12, when he explains his view of his relationship with the students (such as "We have worked to do!", an honest use of the pronoun "we" by the lecturer).
This 48 min long lecture, honestly impressed me in this regard. Today, I had the privilege of a double lecture: one in math (that could have been compressed to 15 min, since most proofs were skipped) and one in being a better passer of knowledge (that could be extended to 10+ years). Hat off!
This lecture just brought my understanding of norms to a whole new level! Thank you so much Professor Strang!
Frobenius norm squared = trace of (A transpose times A) = sum of eigenvalues of (A transpose times A) = sum of squares of singular values
He is such a sweet man and a genius teacher at the same time
The reason I went from hating math to loving math (especially linear algebra) is Gilbert Strang. What an incredible teacher.
Great point on comparing matrix Nuclear norm with vector L1 norm, which tends to find the most sparse winning vector. I guess the matrix Nuclear norm may tend to find 'least' weights during the optimization.
I highly recommend doing the Frobenius norm proof he mentions. It is elegant and uses some nice properties of linear algebra. If you took 18.06 (or watched the lectures) using the column & row picture of matrix multiplication really helps. I'll finalize my proof and post a link - hopefully I didn't make a mistake ;)
Maybe I shouldn't post a link... I wouldn't want anyone enrolled in 18.065 to copy it... Hmm......
The Largest Singular Value is the same as largest Eigen Value for a fully connected layer which is also called as spectral Normalization.
27:07 minimizing something with a constraint Lagrangian Formulation.
35:00 matrix norm
I would use laplace's succession rule in coin flipping problem
Protect him with all cost MIT
Dang - He's good!
come on.... He is Gilbert Strang......
Prof Strang...my respects sir...
Does anyone know something more concrete about the Srebro results? Have they been verified already? How general are they? 44:54
I love Linear Algebra!
@44:00 by now Prof. Strang should know that nothing is ever taken out of the tape haha.
This man is brilliant!
Why is L half not a good norm? Why the P is restricted to be >= 1 instead of just p >0?
so is a sigmoid a norm or a norm is a sigmoid?
Good Video about Norms. Thank you Prof.
Is L0 norm is not convex ????
yes, cause the origin point is excluded
At 32:41 when professor Strang says L2 norm of a matrix is 'sigma1', what does he mean by sigma1?
Hi Shaurov. He is referring to the largest singular value in the SVD of A
12:12
prof: it's just exploded in importance.
me: I just burst in laugh :)
Can someone explain to me when we should use Frobenius norm and when we should use the nuclear norm ?
thank you
perfect. God bless you...
Compelling lecture (as always), but I'm unsettled about one thing: much of it is based on the fact that the first singular vector of A is the maximizing x in the definition of ||A||2. However, this fact just seems to be mentioned without proof or argument, and accordingly it doesn't feel as though the proof that ||A||2 = sigma1 is complete. Thoughts?
I agree. I can give a proof sketch:
1. A = U Σ V^t by the SVD.
2. To maximize ||Σy|| for a unit vector y, we would choose y to have all 0's except for a 1 in the position multiplying the largest value in the diagonal matrix Σ, which is sigma1. This effectively scales every component of y by sigma1 (all the other components are 0). Any other choice of y results in some component of y being scaled by a value less than sigma1, and no component scaled by more than sigma1.
3. U is orthonormal, so ||Uz|| = ||z||
4. 1 and 3 give us ||Ax|| = ||U Σ V^t x|| = ||Σ V^t x||
5. Assume ||x|| = 1. V^t is orthonormal, so ||V^t x|| = 1.
6. Thus, the maximizing value of x satisfies V^t x = y for the y we found in step 2.
7. This gives x = v1, and ||Ax|| = sigma1.
8. Since the L2 norm of A is the maximum value of ||Ax||/||x|| over all x's, the L2 norm of A is sigma1 (small leap here, but straightforward)
Holy crap this is a good lecture
40:10 F norm
Max ||Ax||/||x||=Max ||Akx||/||kx||=Max ||Ax||/||x||, ||x||=1.
So you can think of a unit circle ||x||=1 with ||Ax|| plotted on the radius which might look like a circle and ellipse with a point on the Ellipse being at Max ||Ax||/||x||.
how would the shape look like for p, 1
Between the diamond and the circle.
Long live!
sure big professor
How do we actually see what sigma1 is the maximum blow-up factor and what v1 is the vector what gets blown up the most? Because i initially thought it would be the first eigenvector, and then it would make sense, but then i realised what sigma is not an eigenvalue after professor said it and i'm struggling a bit with imagening what's happening here
Recall the picture Prof. Strang draw when explaining SVD. Here's a refresher (in slide #25):
ocw.mit.edu/resources/res-18-010-a-2020-vision-of-linear-algebra-spring-2020/videos/MITRES_18_010S20_LA_Slides.pdf
As Prof. Strang mentioned, U and V only perform rotation or possible reflection of x, which does not changes the norm of x.
It is Sigma that is responsible for stretching and among those sigma1 is the biggest and it is therefore the "maximum blow-up factor".
I hope this helps.
Are the notes available somewhere?
There are no lectures notes available for this course; that is because the book (Strang, Gilbert. Linear Algebra and Learning from Data. Wellesley-Cambridge Press, 2018. ISBN: 9780692196380) is basically the lecture notes for the course. See the course on MIT OpenCourseWare for more info and materials at: ocw.mit.edu/18-065S18. Best wishes on your studies!
I love him so much
I don't believe in God but I prayed for his health
Awesome!
Is there a link to the notes Prof. Strang keeps alluding to?
@Bob Mama There aren't any lecture notes on that link.
well... How old are these students ?
why sigma 1 is the largest singular value ? Why it's position relate to largest or not ? I dont understand
Yes, singular values are ordered based on size
43:49 The "actual humans" statement is still on the tape 🤣
This is some nice chalk
I've watched the first 6 videos without difficulty, but I'm confused by the definition and geometric meaning of different norms. Could anyone please tell me which textbook I should read to help me understand? Thanks for your helping!
Rewatch the videos, and maybe you'll get it! It has worked for me!
Linear Algebra and Learning from Data by Gilbert Strang!
Whenever I make money I will donate!
You will make a lot of money man. In Wall Street, perhaps!
When you earn 20 dollars, you can donate 1/2 dollars. When you earn 20,000 dollars, you can donate 100 dollars. When you earn 2 billion, you'll leave here and forget about donation for ever.
Old people are really our pride
He forgot to finish PCA.
I can give available information . The lecture here connects the optimization problem with eigenvectors.
But sorry , the lecture in Russian)))
ua-cam.com/video/W5JLSKcuaQo/v-deo.html
How about referring to Andrew Ng lecture at cs229, which is not in Russian for English speakers
ua-cam.com/video/ey2PE5xi9-A/v-deo.html
@@justpaulo @BP C
MVPs.
Why ||A||2 = max ||Ax||2/||x||2? Can someone help me explain? :(
That is actually the definition of matrix norm, induced by a vector
@Rich Caputo shouldn't there be a l2 norm constraint for x? say, ||x|| = 1.
It's a definition rather than a result
The phenomenon he mentioned in the first 5 minutes is a very interesting psychological question. Is it about the sequential effects of decision making? Anyone knows the field? Please feel free to share some papers. Thank you.
Multi Arm Bandits problem?
Cool vid
can somebody provide lecture notes of this course?
Course materials are available on MIT OpenCourseWare at: ocw.mit.edu/18-065S18. Best wishes on your studies!
@@mitocw There aren't any lecture notes on that link.
github.com/ws13685555932/18.065_lecture_notes are some summary notes till lecture 14.
may I ask what the p mean?
it's the mode of norm
superelipses
I didn't get the part where he minimized the L2 norm geometrically, why was it that particular point?
L2 norm for a vector is the distance from origin. Since the candidate vectors have to be on the constraint line, the problem (find a vector that subject to the constraint minimize L2 norm) became "which point on that line has smallest distance to the origin".
💖💖💖🙏
RIP. He will be missed.
He's not dead yet!
Ć
20220527 簽