This guys is a legend, he doesn't have to explain anything this deep but he's got that passion to teach, really happy to see this!!!!!! Good that i noticed his page thanks Krish :)
I want to thank you, I've been watching your videos for a few months. I speak Spanish, and my English is not the best, because of your accent at first I thought I would never understand them because I had never heard that accent, but now I end up studying more English to be able to watch your videos faster. Thank you for your dedication and being part of the creators who democratize their knowledge, leaving everything in videos that are free for us.
hi krish, your are indeed making the videos in a manner that is so easy to understand. you are doing real good for the community and for aspirants that find it difficult to learn all the algorthims. Dont stop making such videos. God bless you
Thanks for the NLP series of videos. Please make a video on domain knowledge gaining. Teach us the domain knowledge wrt Datascience Fine with any specific domain. Also make a video explaining what are the data points to look for choosing a machine learning algorithm for example when do we need to go for Random forest for classification and when for SVM etc. I know you have covered couple these concepts in your earlier videos but a playlist with only these details at deeper level would work. Keep the good work going. Thanks a ton. You are a great inspiration.
A pity that your sentence 3 calculation got cut off from the video, but i got the gist of your explanation. Thanks for making this clear and simple to understand.
Hey Krish , I have been watching your videos for a while now .. i must say..you are AMAZING.. I have been doing small projects based on machine learning concepts , and thanks to you , your videos really helps me to understand the main concepts , both in theoretical and practical implementation..Thanks A Lot... Looking Forward For your New Videos ...
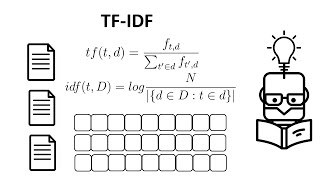
Let C = number of times a given word appears in a document; TW = total number of words in a document; TD = total number of documents in a corpus, and DF = total number of documents containing a given word; compute TF, IDF and TF*IDF score for each term
Correct me if I'm wrong. Bag Of Words ( count or Binary ) and TF-IDF will only give the values based on the frequency of the occurance and doesn't process based on semantics. To get the output based on semantics we need to use Word2Vec. @Krish Naik
Рік тому
amazing lesson!! thank you so much for this well-explained video!
Something to be aware of is that TF-IDF cannot help carry semantic meaning. It considers the importance of the words due to how it weighs them, but it cannot necessarily derive the contexts of the words and understand importance that way.
I really appreciate the simple but effective explanation of the concept, but I have a huge dataset to get the tfidf of, so how to write a code for it as it can’t be calculated manually
So how do we use it to test on unseen data ? since there is a possibility that some unseen word could come which is not present in our vocabulary because of which denominator of IDF may become zero right?









This guys is a legend, he doesn't have to explain anything this deep but he's got that passion to teach, really happy to see this!!!!!! Good that i noticed his page thanks Krish :)
I want to thank you, I've been watching your videos for a few months. I speak Spanish, and my English is not the best, because of your accent at first I thought I would never understand them because I had never heard that accent, but now I end up studying more English to be able to watch your videos faster. Thank you for your dedication and being part of the creators who democratize their knowledge, leaving everything in videos that are free for us.
@jesus Colin.
See the big words you’re using and you say you’re learning English.
I don’t believe you!
I like the way Krish really makes an effort to TEACH, vs simply regurgitating information.
Hi Krish, just wanted to say how helpful and well-explained your videos are. Looking forward to watching more of your series on NLP!
this is the most clear explanation of tfidf I've ever seen. Thank you so much!!
Wow, great explation! I not only understood how to calculate it, but also WHY it is used! Thanks!
Not a rocket science.. Absolutely mind blowing the way he breaks this to the simplest meaning.
You're really amazing Sir. Neatly explained. This explanation is just an example for "THE POWER OF SIMPLICITY". Thanks a lot
Thank you so much! man i cant express how much this video has taught me since i missed the lecture in school! Keep up the good work
A great teacher is one who makes complex things simple. Thank you very much!!
I've spent a bunch of time trying to understand TF-IDF, but with this video it just clicked right away. Thanks!
best channel for data science topics not focus only on theory but the implementation of theory as well.
The way he teaches is just Wow :)
Finally I saw the picture behind tfidf.. All doubts cleared. Thankyou
I really want to thank you as I cleared my ME dissertation because of I am able to understand the working of TFIDF
Thank you!
You explain very good, I send you a hug from Ecuador
I really love your way of explanation. You're explanation of the intuition followed by a demonstration of the code is really useful.
I don't have any words to appreciate again and again. really awesome explained. Thanks for ur help
hi krish, your are indeed making the videos in a manner that is so easy to understand. you are doing real good for the community and for aspirants that find it difficult to learn all the algorthims. Dont stop making such videos. God bless you
You are such an amazing teacher ❤📖
Wish I had you as a professor back in my college days, great vid! Thanks so much for providing a great explanation.
Thank you so much for this simple and clear explanation. Understood the concept on the first go, keep up the good work.
Always in many articles that I've read 'TF-IDF' I could never understand the meaning, but now it's different. Thanks for your video.
Yeah Exactly
Hey Krish M fan of ur teaching . You just teaches from very basic to advanced.
Amazing explanation, very clear and short steps, love it!
Thanks for the NLP series of videos. Please make a video on domain knowledge gaining. Teach us the domain knowledge wrt Datascience Fine with any specific domain. Also make a video explaining what are the data points to look for choosing a machine learning algorithm for example when do we need to go for Random forest for classification and when for SVM etc. I know you have covered couple these concepts in your earlier videos but a playlist with only these details at deeper level would work. Keep the good work going. Thanks a ton. You are a great inspiration.
Your way of teaching is very impressive.
Excellent krish. Keep Motivating. You are doing well
Thankyou so much Krish sir❤️ I'm having exam tmrw. Without the revision now I can directly write my exam...
Really loved it ❣️....u simplify things efficiently!!
A pity that your sentence 3 calculation got cut off from the video, but i got the gist of your explanation. Thanks for making this clear and simple to understand.
what an explanation . just love it . keep it coming sir👌
Hey Krish , I have been watching your videos for a while now .. i must say..you are AMAZING.. I have been doing small projects based on machine learning concepts , and thanks to you , your videos really helps me to understand the main concepts , both in theoretical and practical implementation..Thanks A Lot... Looking Forward For your New Videos ...
just wow Sir because ur explanation is like awesome.
Thanks that was an excellent explanation, could not have been any better...
You are such a talented teacher! Thanks!
Fantastic video! Well done and well explained. To the point, and clear.
Let C = number of times a given word appears in a document;
TW = total number of words in a document;
TD = total number of documents in a corpus, and
DF = total number of documents containing a given word;
compute TF, IDF and TF*IDF score for each term
C/TW, log(TD/DF), C/TW * log(TD/DF)
Great breakdown to layman words. Keep the work. I like the energy too :)
What an amazing guy! Very easy explanation, thank you.
Wonderfully explained sir ....i understood very well 👍
Hi Khris, loved the explanation. Thanks for this.
Great Job Krish (Y)
What a teacher!! Thank you
This is truly beneficial! Thanks for tutroial
Correct me if I'm wrong.
Bag Of Words ( count or Binary ) and TF-IDF will only give the values based on the frequency of the occurance and doesn't process based on semantics. To get the output based on semantics we need to use Word2Vec. @Krish Naik
amazing lesson!! thank you so much for this well-explained video!
Thank you. You are a great teacher.
I understand, thank you so much Mr.
Sir tomorrow is my AI pre board, thank you for this video really helpful
Great explanation ✌️👍
Great Explanation! Thank you for making this video
I love your videos. Thank you, man.
This is awesome 💛💛💛💛🙏🙏🙏❤️❤️❤️❤️❤️❤️❤️❤️❤️
Thank-You so much sir for Crystal clear explanation.
awesome, very well explained.
Thanks krish. Superb video once again.
Amazing video! Thanks!
thank you for this video. very well explained!
Your videos are very informative bro...keep going 🤩
Krish, great teching. WOW
you are perfect. thank youuuu
Thank, this video help me so much. Very easily understand
You are the teacher of half of the subjects in my masters degree. Until I watch your videos, I feel the topic is not complete.
Thanks a lot Sir for providing such great contents.
Incredible video - thank you
Thanku thanku thnku so much infinite thanku
Thanks for your effort. It was a good explain .
You should teach in our college, this is a great video
Amazing sir👍
Something to be aware of is that TF-IDF cannot help carry semantic meaning. It considers the importance of the words due to how it weighs them, but it cannot necessarily derive the contexts of the words and understand importance that way.
Excellent explanation
great video, thanks so much!
very good explaination, really helpfull, plz continue your good will
Bhot sahi bro one day you'll surely blow up 🔥🔥
Thankyou sir❤️🔥
great tutorials Krish, keep it up my man!
Why Indians are so good in teaching?
Very good explaination
Thanks for your video.
Hi krish naik, please answer my questions.
Why TF IDF use log 2? What the purpose of the log 2?
@krish naik
Very helpful, thank you.
Is stemming important before TFIDF or can we use *ing* *ed* etc with the words? Pls reply plsssssss🙏🏻🙏🏻🙏🏻
Thanks a lot! It helped a lot!!!
you are a Gem
Very helpful video.. thank you so much! 🙏🏼
Thank you krish sir
Great explanation
Really good sir
Excelent vídeo. Is there any videos where you explain how to implement TF IDF for better performance of sentiment analysis algorithms?
I really appreciate the simple but effective explanation of the concept, but I have a huge dataset to get the tfidf of, so how to write a code for it as it can’t be calculated manually
Wonderful and very much useful sir. Thank you very.
I request you to clear confusion between sentiment & semantic analysis
at the end do we just add up all the features of every word?
like : i love to code
OP: 0.458962 = f(i) + f(love) + f(to) + f(code) ?
Really great videos!!!
So how do we use it to test on unseen data ?
since there is a possibility that some unseen word could come which is not present in our vocabulary because of which denominator of IDF may become zero right?
Why is TD-IDF called an Instance-based Model?
Thanks Krish
very nicely explained.
What if the "good" is present in sentences 1 more than 2 time
What will the answer
great video!