The beta-VAE seems enforcing a sparse representation. It magically picks the mostly relevant latent variables. I am glad that you mentioned ‘causal’, because that’s probably how our brain deals with high dimensional data. When resources are limited (corresponding to use large beta), the best representation turns out to be a causal model. Fascinating! Thanks
Great explanation on why we actually need the reparameterization trick. Everyone just skims over that and explains the part that mu+var*N(0,1) = N(mu,var), but ignores the part why you need it. Good job!
Hi, I am a Graduate Student at UMass Amherst. I really liked your video, it gave me a lot of ideas. Watching this before reading the paper would really help. Please keep it coming I'll be waiting for more.
@@shrangisoni8758 He's explained the fundamental concepts, you can take those concepts and translate them to code. He shouldn't have to do that for you.
@@pixel7038 Please stop spreading his name. He has faked his way more than enough already. Read more here: twitter.com/AndrewM_Webb/status/1183150368945049605 and here www.reddit.com/r/learnmachinelearning/comments/dheo88/siraj_raval_admits_to_the_plagiarism_claims/ And what really bugs me is not the plagiarism- that's bad and shameful in itself- but the level of stupidity this guys had shown while plagiarizing- "gates" to "doors" and "complex Hilbert space" to "complicated Hilbert space".
Great Video!! I just watched 4 hours worth of lectures, in which nothing really became clear to me, and while watching this video everything clicked! Will definitely be checking out your other work
I hand such a hart time understanding the Reparameterization trick, now i finally got it. Thanks for the great explanation. Would love to see more Videos from you.
Great video! I have a minor correction: At 6:14, calling the cursive L a "loss" might be a misnomer, since loss is something we almost always want to minimize, and the formula of (reconstruction likelihood - KL divergence) should be maximized. In fact, the Kingma and Welling paper call that term the "(variational) lower bound on the marginal likelihood of datapoint i", not a loss.
Bloody nicely explained than the Stanford people. Subscribed to the channel, I remember watching your first video on Alpha, but didn't subscribed then, I hope there will be more content on channel with same level of quality, otherwise its hard for people to stick around when the reward is sparse.
I was very interested in this topic, read the paper, watched some videos, read some blogs. This is by far the best explanation I've come across. You add a lot of value here to the original rapper's contribution. It could even be said you auto-encoded it for my consumption ;)
Your videos are quite good. I am sure you will get an audience in no time if you continue. Thank you so much for making these videos. I like the style you use a lot and love the time format (not too short and long enough to do a good overview dive). Well done.
Just found your channel and I realize how with some passion and effort you explain things better than some of my professors. Of course, you don't go into too much detail but putting together the big picture comprehensively is valuable and not everyone can do it.
I like the subtle distinction you made between the disentangled variational auto-encoder versus the normal variational auto-encoder: Changing the first dimension in the latent space of the disentangled version rotates the face while leaving everything else in the image unchanged. But changing the first dimension in the normal version not only rotates the image, but changes other features as well. Thank you. Me gleaning that distinction from Higgins, et al. Beta-VAE Deepmind paper would be unlikely...
Subscribed. Very useful -- i'm an applied ML researcher (applying these techniques to real-world problems) so I need a way to quickly "scan" methods and determine what may be useful before diving in-depth. These styles of videos are exactly what I need.
Sublime text editor is so aesthetic. Anyway, yes, great point, the input dimensionality needs to be reduced. Even the original Atari DeepMind breakthrough relied on a smaller (handcrafted) representation of the pixel data. With the disentangled variational autoencoder it may be feasible or even an improvement to deal with the full input.
Really liked it. Firstly giving an intuition of the concept, its application and then to the objective function while explaining its individual terms, in a way everyone can understand, it was simply professional and elegant. Nice work and thanks!
This is really great! Thanks for sharing. I think it would be very informative if you linked to a few of the papers related to the concepts in the video (for those who want to slough through dry text after being sufficiently intrigued by the video).
It would be interesting to apply this to word embeddings. There is the well know example that king-queen = man-woman, (so king-man+woman = queen), but the question that immediately comes up is what are the "real" semantic dimensions. I don't think there is an answer to this in the short term, because of the homonym problem, but it is interesting to think that this kind of network could discover such abstract features.
@1:21 "...with two principal components: ... Encoder... Decoder..." I know that you did it without bad intention but using this terminology may lead to confusion. PCA (Principal Component Analysis) is also used for dimensionality reduction and often compared to autoencoders. In PCA world the term "principal components" has really significant meaning. By the way, great video and keep up with the outstanding work!!!
Great episode. Came here for a good explanation of VAEs, but was blown away when you dug into Beta-VAEs and the Deepmind RL paper. Have you read the group's newest paper "SCAN" on combining Beta-VAEs with symbol representation and manipulation?
I liked arxiv.org/pdf/1709.05047.pdf more, but the SCAN paper is also cool. BTW compliments for your channel, it's the only Deep Learning channel which is worth following.
Great content ! The format and delivery is perfect, hope to see more of these videos :) . Are you planning on doing a video on Capsule Networks in the future ?
More videos are definitely coming, the next one will be on novel state-of-the-art methods in Reinforcement Learning! I don't plan on making a video on Capsule Nets since there is an amazingly good video by Aurélien Géron on that topic and there's no way I can explain it any better than he did, no need to reinvent the wheel :p Here is his video: ua-cam.com/video/pPN8d0E3900/v-deo.html
Great video! I am still a bit confused about the advantage of using a VAE over a normal (deterministic auto encoder). As far as I understand (assuming you have 2 classes/labels for your data), your input data gets mapped to a vector in the latent space. In the deterministic case, you have one point in this space for each image, in the VAE case you have an n-dim Gaussian distribution (say an ellipse in a 2D latent space) for each image. However, in the end you want the point (or ellipses) corresponding to different classes to cluster in different regions of your latent space. So ideally you end up with 2 separate cluster. Why is it better to have 2 clusters made of ellipses than 2 clusters made of points. Is it just the area of the latent space that they cover (which is bigger for an ellipse than for a point)? Or is it a deeper meaning? Thank you!
Hey its been 4 years, but as far as I think variational AE help resolving the discontuinity problem and plus as you mentioned they cover a greater area reducing bias and the problem of generating data from "holes" or empty spaces. Let me knof if what Im saying makes sense lol
Exactly, Siraj' videos are fantastic but I think he's aiming for a larger audience. I'm trying to bring a bit more technical depth and I have the idea enough people are interested in this to make the effort of creating these videos totally worth it!
Yeah, personally, I wouldn't hide behind "no offense." That guy is, in fact, manic and incompetent, and I intend just as much offense as those words imply.
I was a huge fan of Siraj, but recently I could tell that he just keep looping the same topics over and over again, copying other's code and sometimes does not understand the concept he is going through.
I know, I am being a prick. I just have scorn for Siraj because he seems to be trying to get attention from riding a hot trend without giving much back to the community. I used to spend a lot of time on his videos trying to implement but his code would be unworkable.
6:14 - these equations are tough! Looks like mathematical jargon, as if the guys were saying "ok, we don't have time to explain, but you'll figure out".
QUESTION CONCERNING VAE! Using VAE with images, we currently start by compressing an image into the latent space and reconstructing from the latent space. QUESTION: What if we start with the photo of adult human, say a man or woman 25 years old (young adult) and we rebuild to an image of the same person but at a younger age, say man/woman at 14 years old (mid-teen). Do you see where I'm going with this? Can we create a VAE to make the face younger from 25 years (young adult) to 14 years (mid-teen)? In more general term, can VAE be used with non-identity function?



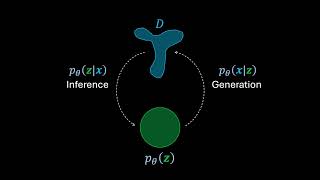






Variational Autoencoders starts at 5:40
You just saved five minutes of my life!
@@pouyan74 no the first part was necessary...
@@Moaaz-SWE you think someone would enter a video about Variational Autoencoders if he doesn't know what Autoencoders are
@@selmanemohamed5146 yeah i did... 😂😂😂 and i was lucky he explained both 😎🙌😅 + the difference between them and that's the important part
@Otis Rohan Interested
This kind of well-articulated explanation of research is a real service to the ML community. Thanks for sharing this.
Except for "Gaussian" that is weirdly russian pronunced "khaussian" wat?
This guy does a real job of explaining things rather than hyping up things like "some other people".
are you referring to Siraj Raval? lol
@@malharjajoo7393 lol
The beta-VAE seems enforcing a sparse representation. It magically picks the mostly relevant latent variables. I am glad that you mentioned ‘causal’, because that’s probably how our brain deals with high dimensional data. When resources are limited (corresponding to use large beta), the best representation turns out to be a causal model. Fascinating! Thanks
Your way of simplifying things is truly amazing! We really need more people like you!
Three years later and this still the best VAE video I've seen. Thanks Xander!
hands down this was the best autoencoder and variational autoencoder tutorial I found on Web.
This guy was a VAE to the VAE explanation. Really need more of such explanations with the growing literature! Thanks!
always the best place to have a good overview before diving deeper
Great explanation on why we actually need the reparameterization trick. Everyone just skims over that and explains the part that mu+var*N(0,1) = N(mu,var), but ignores the part why you need it. Good job!
I love your channel. A perfect amount of technicality so as to not scare off beginners, and also keep the intermediates/ experts around. Brilliant.
A really great talk! I have been reading about VAE a lot and this video helps me to understand it even better.
Thanks!
Bro this was insanely helpful! I'm writing my thesis and am missing a lot of the basics in a lot of relevant areas. Great summary!
Finally, someone who cares their viewers actually get to understand VAEs.
Hi, I am a Graduate Student at UMass Amherst. I really liked your video, it gave me a lot of ideas. Watching this before reading the paper would really help. Please keep it coming I'll be waiting for more.
Don't you ever stop explaining papers like this. Better than Siraj's video.
Just explain the code part a bit longer. And your channel is set.
exactly. show some more code please.
Yea we can't really do much until we code and see results ourselves.
Siraj has improved his videos and provides more content. Don’t be stuck in the past ;)
@@shrangisoni8758 He's explained the fundamental concepts, you can take those concepts and translate them to code. He shouldn't have to do that for you.
@@pixel7038 Please stop spreading his name. He has faked his way more than enough already. Read more here: twitter.com/AndrewM_Webb/status/1183150368945049605 and here www.reddit.com/r/learnmachinelearning/comments/dheo88/siraj_raval_admits_to_the_plagiarism_claims/
And what really bugs me is not the plagiarism- that's bad and shameful in itself- but the level of stupidity this guys had shown while plagiarizing- "gates" to "doors" and "complex Hilbert space" to "complicated Hilbert space".
This is sooooooo useful for 2am and you dragged by all the math in the actually paper. Thanks man for the clear explanation!
Great Video!! I just watched 4 hours worth of lectures, in which nothing really became clear to me, and while watching this video everything clicked! Will definitely be checking out your other work
Your explanations are quite insightful and flawless. You are are a gifted explainer! Thanks for sharing them. Please keep sharing more.
Great! No BS, strait and plain English! That`s what I want!! :) Congratulations!
I hand such a hart time understanding the Reparameterization trick, now i finally got it. Thanks for the great explanation. Would love to see more Videos from you.
Great video! I have a minor correction: At 6:14, calling the cursive L a "loss" might be a misnomer, since loss is something we almost always want to minimize, and the formula of (reconstruction likelihood - KL divergence) should be maximized. In fact, the Kingma and Welling paper call that term the "(variational) lower bound on the marginal likelihood of datapoint i", not a loss.
Bloody nicely explained than the Stanford people. Subscribed to the channel, I remember watching your first video on Alpha, but didn't subscribed then, I hope there will be more content on channel with same level of quality, otherwise its hard for people to stick around when the reward is sparse.
Best explanation found on the internet so far. Congratulations!
This is a LIT channel for watching alongside papers. Thanks
Great video, better than many tutor lessons in university, this animation and simplified the things with simple words
I was very interested in this topic, read the paper, watched some videos, read some blogs. This is by far the best explanation I've come across. You add a lot of value here to the original rapper's contribution. It could even be said you auto-encoded it for my consumption ;)
Your videos are quite good. I am sure you will get an audience in no time if you continue. Thank you so much for making these videos. I like the style you use a lot and love the time format (not too short and long enough to do a good overview dive). Well done.
Thank you very much for supporting me man! New video is in the making, I expect to upload it hopefully somewhere next week :)
"You cannot push gradients through a sampling node"
TensorFlow: *HOLD MY BEER!*
Your explanation is crisp and to the point. Thanks.
Just found your channel and I realize how with some passion and effort you explain things better than some of my professors. Of course, you don't go into too much detail but putting together the big picture comprehensively is valuable and not everyone can do it.
what a gem of a channel I have found her...
Im always intimidated when he says it is going to be technical, but then he explains it so concisely.
Great! Crisply clear explanations in such a short time.
I like the subtle distinction you made between the disentangled variational auto-encoder versus the normal variational auto-encoder: Changing the first dimension in the latent space of the disentangled version rotates the face while leaving everything else in the image unchanged. But changing the first dimension in the normal version not only rotates the image, but changes other features as well. Thank you. Me gleaning that distinction from Higgins, et al. Beta-VAE Deepmind paper would be unlikely...
Thank you very much, this is the first time I understand the benefit of reparameterization trick.
Finally I understood the intuition of sampling from mu and sigma and reparameterization trick. Thanks!
Great video ! Very clear and understandable explanaitions of hard to understand topics.
Subscribed. Very useful -- i'm an applied ML researcher (applying these techniques to real-world problems) so I need a way to quickly "scan" methods and determine what may be useful before diving in-depth. These styles of videos are exactly what I need.
Your videos are absolute crackin for a quick revision before an interview!
Sublime text editor is so aesthetic. Anyway, yes, great point, the input dimensionality needs to be reduced. Even the original Atari DeepMind breakthrough relied on a smaller (handcrafted) representation of the pixel data. With the disentangled variational autoencoder it may be feasible or even an improvement to deal with the full input.
Really liked it. Firstly giving an intuition of the concept, its application and then to the objective function while explaining its individual terms, in a way everyone can understand, it was simply professional and elegant. Nice work and thanks!
Good explanation. Enough and relevant math that support the explanation which we can understand the insight.
Great explanations. This filled two crucial gaps in my understanding of VAEs, and introduced me to beta-VAEs.
Dude what a next level genius you are!
You made them so easy to be understood, and just look at the quality of the content.
Damn bro!🎀
Just found this channel ... today... one word Brilliant...!!!
This was very lucid. You are gifted at explaining things!
I would like to see more videos from you. Clear explanation of concept and gentle presentation of math. Great job!
This is really great! Thanks for sharing.
I think it would be very informative if you linked to a few of the papers related to the concepts in the video (for those who want to slough through dry text after being sufficiently intrigued by the video).
Elre Oldewage Really good point, I'll add the links tonight!
Thanks :)
6 years ago and I now use this video as a guidance to understanding StableDiffusion
an you help me out as well? I have so many questions but no one to answer them.
It would be interesting to apply this to word embeddings. There is the well know example that king-queen = man-woman, (so king-man+woman = queen), but the question that immediately comes up is what are the "real" semantic dimensions. I don't think there is an answer to this in the short term, because of the homonym problem, but it is interesting to think that this kind of network could discover such abstract features.
Thanks a lot for sharing such a succinct summarization of VAEs. Very helpful!
Very good explanation of Variational Autoencoders! Kudos!
wait how did I not know of this channel. Beautiful explanation, perfectly clear. Thanks for the awesome work!
Thank you! This was comprehensive and comprehendible.
Really appreciate your effort of simplifying research papers for viewers.Keep it up.I want more such videos
I’ve come from the future of 2024 to say this is a great, comprehensive video!
Thanks, this video clarified many things from the original paper.
So many ideas come to mind after watching this video. Well done!
I discovered your channel today and I'm hooked! Excellent work. Thank you so much for your hard work
your videos are awesome don't lose track bcuz of subscribers.
Excellent video!! Probably the best VAE video I saw. Thanks a lot :)
Your explanation is so clear.
I love you. I spent so long on this and couldn't understand the intuition behind it, with this video I understood immediately. Thanks
This video suddenly popped up today morning on my home page. Now i know my Sunday will be great. :D
mapping the latent vectors is really smart
Great work. Thanks a lot! Highly appreciate your effort. Creating these videos takes time but I still hope you will continue.
Wow! Great video. Very concise and easy to understand something quite complex.
Epic video Xander! I learned a lot from your explanation. Now to try an implement some code!
Thanks for this video. It gave a nice overall idea about variational auto-encoders.
We needed a serious and technical channel about latest findings in DL. That siraj crap is useless. Keep going! Awesome
Amazing explanation to a complicated topic! Thank you so much!!!!
This was an amazing video! Thanks man. Will stay tuned for more!
@1:21 "...with two principal components: ... Encoder... Decoder..."
I know that you did it without bad intention but using this terminology may lead to confusion.
PCA (Principal Component Analysis) is also used for dimensionality reduction and often compared to autoencoders. In PCA world the term "principal components" has really significant meaning.
By the way, great video and keep up with the outstanding work!!!
Great episode. Came here for a good explanation of VAEs, but was blown away when you dug into Beta-VAEs and the Deepmind RL paper. Have you read the group's newest paper "SCAN" on combining Beta-VAEs with symbol representation and manipulation?
Sean Goldberg Haven't had the time yet, it's somewhere in my 658 open chrome tabs though :p
I liked arxiv.org/pdf/1709.05047.pdf more, but the SCAN paper is also cool. BTW compliments for your channel, it's the only Deep Learning channel which is worth following.
Very Helpfully Arxiv! keep the good Quality videos coming
I rarely like videos on youtube but this video is so freaking good for beginners like me!
Big Fan. Would love to see videos where you breakdown some of the applications using deep learning tools.
Great content ! The format and delivery is perfect, hope to see more of these videos :) . Are you planning on doing a video on Capsule Networks in the future ?
More videos are definitely coming, the next one will be on novel state-of-the-art methods in Reinforcement Learning! I don't plan on making a video on Capsule Nets since there is an amazingly good video by Aurélien Géron on that topic and there's no way I can explain it any better than he did, no need to reinvent the wheel :p Here is his video: ua-cam.com/video/pPN8d0E3900/v-deo.html
This is really good. I like the way you explain things. Thank you for sharing!
First video I see from this channel. Immediately subscribed!
Shared your work with my followers. Keep making amazing content
Thank you very much, I was trying to understand it, but it's much easier when I found this video!
Excellent Content. I'm using VAE for music generation. Your explainations are very interesting.
Thanks again
Jeremy Uzan
IRCAM Paris
You help so much with my exams, thanks man, subscribed for more high quality stuff!
One minute watching this video is enought to be a new subscriber! Awesome
Great video! I am still a bit confused about the advantage of using a VAE over a normal (deterministic auto encoder). As far as I understand (assuming you have 2 classes/labels for your data), your input data gets mapped to a vector in the latent space. In the deterministic case, you have one point in this space for each image, in the VAE case you have an n-dim Gaussian distribution (say an ellipse in a 2D latent space) for each image. However, in the end you want the point (or ellipses) corresponding to different classes to cluster in different regions of your latent space. So ideally you end up with 2 separate cluster. Why is it better to have 2 clusters made of ellipses than 2 clusters made of points. Is it just the area of the latent space that they cover (which is bigger for an ellipse than for a point)? Or is it a deeper meaning? Thank you!
Hey its been 4 years, but as far as I think variational AE help resolving the discontuinity problem and plus as you mentioned they cover a greater area reducing bias and the problem of generating data from "holes" or empty spaces. Let me knof if what Im saying makes sense lol
No offence to Siraj, but much much better than manic Siraj.
Exactly, Siraj' videos are fantastic but I think he's aiming for a larger audience. I'm trying to bring a bit more technical depth and I have the idea enough people are interested in this to make the effort of creating these videos totally worth it!
Makes little sense to offend someone like that and then put "No offence" before it
Yeah, personally, I wouldn't hide behind "no offense." That guy is, in fact, manic and incompetent, and I intend just as much offense as those words imply.
I was a huge fan of Siraj, but recently I could tell that he just keep looping the same topics over and over again, copying other's code and sometimes does not understand the concept he is going through.
I know, I am being a prick. I just have scorn for Siraj because he seems to be trying to get attention from riding a hot trend without giving much back to the community. I used to spend a lot of time on his videos trying to implement but his code would be unworkable.
Wow, love your videos. I have not worked with reinforcement learning, but I’d love to hear your analysis of other generative models.
6:14 - these equations are tough! Looks like mathematical jargon, as if the guys were saying "ok, we don't have time to explain, but you'll figure out".
Very clearly explained. Good job.
Great videos man, keep them going, you're gonna find an audience!
Great thanks for the video and the paper explanation! Really, really helpful, keep that paper explanation content!
Really really awesome channel!!! Look forward to watching more of your videos!
Thank god I got a Masters in CS. I could be wrong but I do Imagine these topics are much harder to follow without decades of technical education.
You're explaining this very well! Finally an explanation on an AI technique that's easy to follow and understand. Thank you.
Very good and informative overview thanks!
QUESTION CONCERNING VAE! Using VAE with images, we currently start by compressing an image into the latent space and reconstructing from the latent space.
QUESTION: What if we start with the photo of adult human, say a man or woman 25 years old (young adult) and we rebuild to an image of the same person but at a younger age, say man/woman at 14 years old (mid-teen). Do you see where I'm going with this? Can we create a VAE to make the face younger from 25 years (young adult) to 14 years (mid-teen)?
In more general term, can VAE be used with non-identity function?
Great video, and the algorithm is finally recognizing it! Come back and produce more videos?
Amazing description...
Need more videos on different things