Variational Autoencoder - Model, ELBO, loss function and maths explained easily!

Вставка
- Опубліковано 14 тра 2024
- A complete explanation of the Variational Autoencoder, a key component in Stable Diffusion models. I will show why we need it, the idea behind the ELBO, the problems in maximizing the ELBO, the loss function and explain the math derivations step by step.
Link to the slides: github.com/hkproj/vae-from-sc...
Chapters
00:00 - Introduction
00:41 - Autoencoder
02:35 - Variational Autoencoder
04:20 - Latent Space
06:06 - Math introduction
08:45 - Model definition
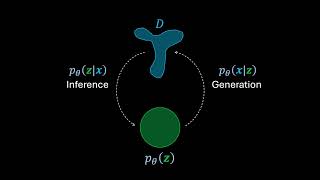
12:00 - ELBO
16:05 - Maximizing the ELBO
19:49 - Reparameterization Trick
22:41 - Example network
23:55 - Loss function - Наука та технологія








It's the clearest explanation about VAE that I have ever seen.
If you're up to the challenge, watch my other video on how to code Stable Diffusion from scratch, which also uses the VAE
I would pay so much to have you as my teacher, that's not only the best video i've ever seen on deep leanring, but probably the most appealing way anyone ever taught me CS !
The peps starting from 06:40 are the gem. Totally agree.
Incredible explanation. Thanks for making this video. It's extremely helpful!
PLATO MENTIONED PLATO MENTIONED I LOVE YOU THAT'S THE BEST VIDEO I'VE EVER SEEN !!!
Getting philosophical w/ the Cave Allegory. I love it. Great stuff.
This is the best explanation on the internet!
Simply amazing. Thank you so much for explaining so beautifully. :)
this is the best video on the Internet
You solved my confusion since long! Thank you !
so clear! so on point! love the way you teach!
I love this so much, this channel lands in my top 3 ML channels ever
Wow thank you very informative
You are a great teacher.
Great Explanation!!
Thanks, this video have many explanations that are missing from other tutorials on VAE.
Like the part from 22:45 onwards. I saw a lot of other videos that didn't explain how the p and q functions were related to the encoder and decoder.
(every other tutorial felt like they started talking about VAE, and then suddenly changed subject to talk about some distribution functions for no obvious reason).
Glad you liked it!
thanks UMAR!
Hey, thank you for the great video. Curious if there is any plan to have a session for code for VAE? Many thanks!
Thanks!
A normalizing flow video would complement this nicely
Would you please give the url for normalizing flows
You rock!
Hey can you do a video on SWin transformer next??
Thanks for sharing . In the chicken and egg example, will p(x, z) be trackable? if x, z is unrelated, and z is a prior distribution, so p(x, z) can be writen in a formalized way?
Can you do more explanations with coding walk through that video you did on transformer with the coding helped me understand it a lot
Hi Oio! I am working on a full coding tutorial to make your own Stable Diffusion from scratch. Stay tuned!
@@umarjamilai i hope to see it soon, sir
Sad that you have not released video "Hot to code the VAE"(
Link to the slides: github.com/hkproj/vae-from-scratch-notes
thx for the video, this is awesome!
14:41 you dont maximiye log p(x), that is a fixed quantity.
why does learning distribution via a latent variable capture semantic meaning. ? can you please elaborate a bit on that
Latent variable is of low dimension compare to input which is of high dimension…so this low dimension latent variable contains features which are robust, meaning these robust features survive the encoding process coz encoding process removes redundant features….imagine a collection had images of cat and a bird image distribution, what an encoder can do in such a process is to outline a bird or cat by its outline without going into details of colours and texture….these outlines is more than enough to distinguish a bird from a cat without going into high dimensions of texture and colors
@@quonxinquonyi8570 that doesnt answer the question. Latent space in autoencoders dont capture semantic meaning , but when we enforce regularization on latent space and learn a distribution thats when it learns some manifold
@@prateekpatel6082 learning distribution means that you could generate from that distribution or in other words sample from such distribution…but since the “ sample generating distribution “ can be too hard to learn, so we go for reparametrization technique to learn the a standard normal distribution so that we can optimize
I wasn’t talking about auto encoder,I was talking about variational auto encoder…
“ learning the manifold “ doesn’t make sense in the context of variational auto encoder….coz to learn the manifold, we try to approach the “score function” ….score function means the original input distribution….there we have to noised and denoised in order to get some sense of generating distribution….but the problem still holds in form of denominator of density of density function….so we use log of derivative of distribution to cancel out that constant denominator….then use the high school level first order derivative method to learn the noise by using the perturbed density function….
The Cave Allegory was overkill lol
I'm more of a philosopher than an engineer 🧘🏽
Missing a lot of details and whys.
I lost you at 16:00