Great explanation, just adding my thoughts here. @12:20, you've mentioned K=1 is underfitting. I think it's the other way around. Low K means highly flexible and jagged boundaries (low bias high variance) leading to overfitting.
Hey kamran do you got the point why he used 23 as k and why not 33 as it is giving the highest accuracy. Yeah i get the point of overfitting maybe thats why we didn't chose 33 but why 23 either..
I don't understand the idea of using KNN for a regression problem. For classification, it's fine: - There you know the location of the point (x and y value) and you have to predict it's category. picking up the five nearest points is understandable. But in a regression problem, you only know the x value of a point and you have to predict the Y value, If I'm not wrong here. In the video, you first plot the point and then pick 5 or some nearest points. But if you already know the location (x,y) of the point, what is the problem here? The mean of 5 neighbors distances gives you what? I'm guessing the Y value but if that is so then how will you pick k neighbors. Please Answer!
@@krishnaik06 I'm really sorry sir. But that doesn't answer my question. I understand you're busy and maybe couldn't go through the whole question. Please try to look at it once more and reply whenever you have time. Thanks!
@@manikaransingh3234 Iam not sure exactly but according to lecture we should always select the k value as 5 the mean value 5 nearest neighbour value gives y value.
@Krish Naik The dataset you explained here is a Regression problem right? then why have you used "KNearestClassifier" in the codes while importing from sklearn library? could you please tell me? Also why classification report is needed for a regression problem here?
In the error rate vs value of the K plot, shouldn't the value of K be around 37? At k=37, we are getting the least error. At this point, the error is less than 0.6?
I didn't get why you took k=23 as in the accuracy plot, we can see that the accuracy is increasing after that point. We should take k value so as to maximize the accuracy, right?
In this video, you told that your model will underfitting when k=1, but in this case model always go to overfitting when k is low but we increase the k then our model goes to underfitting .
If a give an input list for the KNN algorithm to predict the classes of each element, How can I print out the list of inputs only belonging to a particular class?
I think we need to plot error rate for train vs CV then we have a better plot to look at,and decided to choose 23/33. If the gap between train and cv is less k=33 then k=23 then use k=23 ,otherwise 23 is good.
Hello Sir for k=1 im getting overfitting data and as i increase the value of k the error rate is increasing. How to choose k value if the error graph is linear
HI Sir thank you very much for your transfer of knowledge Can Please explain about concept of Weight of Evidence(WOE) and how it is used in classification algorthims
why we need training if we just calculate distance from points in testing ? What exactly is done in training phase if we just classify points based on distance ?
Internally, KNN uses a tree data structure to sort feature vectors so that it does not have to search the entire training set for finding nearest neighbors. This data structure is generated during training
sir I have gone through ML playlist and some videos are not according to step by step after 50 th video so can you check it again please. bcz some videos are interchange up down
choosing k=5 is just for reference it's like just another example. You have to pick the best value of k for which the final error is minimum. The value of k will basically depend on the dataset points.
I have started learning about Data Modelling and ML. My doubt is K-Nearest Neighbour will come under classification algorithm which is type of supervised learning. But here it is explained with regression also. Can anyone help me to understand!
It works for both classification as well as regression problem. And it comes under supervised machine learning.But in real data scinario KNN mostly used for classification problems.
These are 2 musical (jazz) solos generated using K Nearest Neighbor classifier: ua-cam.com/video/zt3oZ1U5ADo/v-deo.html ua-cam.com/video/Shetz_3KWks/v-deo.html



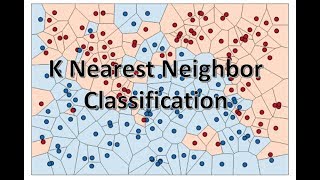






grt explanation my teacher took 2 days i didnt undersatand a word by watching this 18 min main done with knn thnku
Excellent Krish...you are really giving a lot to the society..
Excellent Video! 3:41 Euclidean Distance is nothing but Pythagoras theorem's way of calculating the hypotenuse
Thank you so much! This is exactly what I need it.
Thank you sir, KNN is pretty clear to me now !! : )
lmao
Imo
@@vaibhavkhobragade9773 why are you two lmaoing?
Thank you so much for explaning the concept and code in such a friendly manner.
this is what is needed, thank you so much sir
Great explanation, just adding my thoughts here.
@12:20, you've mentioned K=1 is underfitting. I think it's the other way around.
Low K means highly flexible and jagged boundaries (low bias high variance) leading to overfitting.
Good point
Hey kamran do you got the point why he used 23 as k and why not 33 as it is giving the highest accuracy. Yeah i get the point of overfitting maybe thats why we didn't chose 33 but why 23 either..
🙏nice video easy to understand
I don't understand the idea of using KNN for a regression problem. For classification, it's fine: - There you know the location of the point (x and y value) and you have to predict it's category. picking up the five nearest points is understandable.
But in a regression problem, you only know the x value of a point and you have to predict the Y value, If I'm not wrong here. In the video, you first plot the point and then pick 5 or some nearest points. But if you already know the location (x,y) of the point, what is the problem here? The mean of 5 neighbors distances gives you what? I'm guessing the Y value but if that is so then how will you pick k neighbors.
Please Answer!
For Knn regressorr u take the average of 5 nearest neighbour
@@krishnaik06 I'm really sorry sir. But that doesn't answer my question.
I understand you're busy and maybe couldn't go through the whole question.
Please try to look at it once more and reply whenever you have time.
Thanks!
@@manikaransingh3234 Iam not sure exactly but according to lecture we should always select the k value as 5 the mean value 5 nearest neighbour value gives y value.
@@sathishs1756 you too didn't understand my question.
Okay,
You say five neighbors, neighbors of which point?
@manikaranasingh Same doubt here
Thanks Krish. Good explanation..!
great way of teaching by putting code and implementation
@Krish Naik The dataset you explained here is a Regression problem right? then why have you used "KNearestClassifier" in the codes while importing from sklearn library? could you please tell me? Also why classification report is needed for a regression problem here?
Thanks for giving a lucid explanation.
In the error rate vs value of the K plot, shouldn't the value of K be around 37? At k=37, we are getting the least error. At this point, the error is less than 0.6?
Very well explained sir. ..... Thanks a lot for making my concept clear
Amazingly explained.Thanks a lot
You did not mentioned which metrics is applied when test. Eucledian, Manhattan? sklearn library seems to be use minkowski by default.
Perfectly explained
Finished practicing in Jupyter notebook.Thanks
superb ..good job very much appreciated
Excellent work.. Done a good job.
Superb explanation. Now just need to make my hands dirty in the Jupyter notebook.Thanks.
Thanks Krish
Very nice explaination, thank u for this video
I didn't get why you took k=23 as in the accuracy plot, we can see that the accuracy is increasing after that point. We should take k value so as to maximize the accuracy, right?
Same with me, did you got the point now?
In this video, you told that your model will underfitting when k=1, but in this case model always go to overfitting when k is low
but we increase the k then our model goes to underfitting .
yeah i have the same doubt k=1 it will be overfitting and k=n it will be underfitting
Yes
If a give an input list for the KNN algorithm to predict the classes of each element, How can I print out the list of inputs only belonging to a particular class?
Than you Krish, can we call all multiclass logit regressions are non-linear? please confirm or post small video. Thank you
It this is also necessary to standardize the categorical variable in KNN to find the better K-value?
hi krish in what situations we can use KNN and logistic regression and what is the difference between them.
Instead of standard scalar can't we use MinMaxScalar?
Hi, Krish why not use k =33 it has min error and max accuracy instead of 23?
It leads you to Overfitting. Too less training error is also not acceptable.
I think we need to plot error rate for train vs CV then we have a better plot to look at,and decided to choose 23/33.
If the gap between train and cv is less k=33 then k=23 then use k=23 ,otherwise 23 is good.
Hello Sir for k=1 im getting overfitting data and as i increase the value of k the error rate is increasing. How to choose k value if the error graph is linear
Thank u sir 4 ur logic.
Hi Krish did u find error.rate (1-mean) becz u standardised the data points forehand; that part confuses me
How does outlier effect knn??
how to find radius in knn ( in jupyter notebook with code )
Can you tell me how I can choose variables for KNN? I have 20+ variables, and not sure how I would keep some of the variables with what criteria.
HI Sir thank you very much for your transfer of knowledge Can Please explain about concept of Weight of Evidence(WOE) and how it is used in classification algorthims
Hi Kris. Can you please share the link of video on imbalance dataset.
Hi Krish Why we didnt take sqrt of datapoints to calculate K?
why we need training if we just calculate distance from points in testing ? What exactly is done in training phase if we just classify points based on distance ?
KNN does not have training phase.
Internally, KNN uses a tree data structure to sort feature vectors so that it does not have to search the entire training set for finding nearest neighbors. This data structure is generated during training
Hi Krish, I am trying to learn about algorithms which can be used for text base analysis. Could you please advise?
If K is 4, and there are 2 2 equal distribution, what would be the classification?
No k value will be always odd.
How does it train itself on the data?
Thank you so much ....!!! It's really nice explanation.
sir I have gone through ML playlist and some videos are not according to step by step after 50 th video so can you check it again please. bcz some videos are interchange up down
I don't understand why to choose k=5 while later in the video it chooses 23?
choosing k=5 is just for reference it's like just another example. You have to pick the best value of k for which the final error is minimum. The value of k will basically depend on the dataset points.
Could you please briefly explain about euclidean and Manhattan distance
Why we take k=5,
We can take any other value or not
I do not understand why you take k nearest neighbors as 23?
pls reply me sir...
Refer following video buddy,
ua-cam.com/video/otolSnbanQk/v-deo.html
we are choosing k by seeing the graph
, on x axis "k", y axis error rate. so like that k is 23
thank you sir
great explanation
sir can you make one video on yolo algorithm?
Great
Hello sir would you please explain about Nearest Neighbour Algorithms
for Forecasting Call Arrivals in Call Centers article
Sir DO you have any discord or slack community if yes please share it here i would like to join your community.
Thankyou sir :)
Where is the link to this kaggle code
Impressive ! Nice Clarification..
sir what is the name of this data set on kaggle
I have started learning about Data Modelling and ML. My doubt is K-Nearest Neighbour will come under classification algorithm which is type of supervised learning. But here it is explained with regression also. Can anyone help me to understand!
It works for both classification as well as regression problem. And it comes under supervised machine learning.But in real data scinario KNN mostly used for classification problems.
best comparing other resources !!!!!!!!!!!
Can u please provide ppt
PLEASE HELP ME TO FIND OUT ML TUTORIAL -44
These are 2 musical (jazz) solos generated using K Nearest Neighbor classifier:
ua-cam.com/video/zt3oZ1U5ADo/v-deo.html
ua-cam.com/video/Shetz_3KWks/v-deo.html
could see kadhal vandhale sonf from your bookmarks !!! hah hah ...nice song though
Hue = hoie 😀
Wa.kn was.pkw
go corona corona go!!
Thanks Krish