Thank you for the good explanation! You forgot to link the paper you mentioned (at 12:43). For all who are interested: I think it was about this paper: "Convolutional Neural Networks for Sentence Classification" by Yoon Kim
Hey there! I normally don’t leave comments, or likes but I had to stop here! You’ve explained a convoluted topic in a clear, digestible and concise way. Thank you!
One of best lecture i have heard ever. Seriously i was totally in to your video for 15mins, which i forgot external world. Awaiting for next set of topics.
Soon we will upload the next video of this series! If you liked the video, please press the like button so that other people can find this video! Regards
@@MachineLearningTV at 11:19 I am confused about why each gram we learn 100 filters? What is the filter in this case? I thought by applying the 3-gram kernel using the same padding, we will get (1,n) vector, where n: number of words in this case n=5. Then we have 3,4,5 gram, shouldn't we just have 3 (1,n) vectors? If we get max value for each gram, shouldn't we just have 3 outputs, where each output from each x-gram vector (size =(1,n))? Can you explain why you said 300 outputs? Thanks,
This is the most comprehensive video I've ever seen on neural networks! Thank you so much! I study and develop AI, but was using something more like the bag of words representation. The other thing, aside from accuracy that I noticed to be an issue with the bag of words representation, was actually the amount of resources it required from the machine it was operating on. To give some insight into just how bad it was, while the machine I was using wasn't exactly top of the line, the machine I'm using now is pretty high performance (i5-8400, 16gb RAM, 1TB Samsung Evo 860 SSD) and yet, the facial recognition usually dropped down the camera feed to about 3-5fps when it would detect a face. Even generating a response (using Speech-to-Text, then a custom-tailored version of the Levenshtein Distance algorithm to correct any misinterpretation of speech) was using at least 7GB of RAM even with a relatively small data set in the vicinity of maybe 50GB, and using 40-60% of my CPU power. Anyhow, my intent with watching this video was to learn about better algorithms, with the intent of actually implementing a neural network on an FPGA (Field-Programmable-Gate-Array). Now I feel well-equipped with enough information to conquer that finally, as I feel I finally understand CNNs well enough. Thanks so much!
This is not a pretty high performance setup. This is an average PC I bought a PC for 3d rendering and it's a 32 cores CPU E5-2670 0 @ 2.60GHz, 128GB of RAM and storage is a some kind of SSD on PCI-E. Pretty good setup
at 11:19 I am confused about why each gram we learn 100 filters? What is the filter in this case? I thought by applying the 3-gram kernel using the same padding, we will get (1,n) vector, where n: number of words in this case n=5. Then we have 3,4,5 gram, shouldn't we just have 3 (1,n) vectors? If we get max value for each gram, shouldn't we just have 3 outputs, where each output from each x-gram vector (size =(1,n))? Can you explain why you said 300 outputs? Thanks,
at 4:25, the result of convolution is not 0.9, it is 0.88. How CNN create these filters? For instance we defined 16 filters to apply. How CNN library determine the content of filters ( numbers) ?
This seems to use lots of terms that are undefined here. Is this part of a larger presentation? If so, numbering the parts would be useful. If not, then this really expect you to know a lot about the terminology before watching. Frankly, I find this completely confusing.
@@ruslanmurtazin7918 but that may be in case for feature eng in unsupervised learning. What about supervised learning algo..do we still need i this case?









Thank you for the good explanation!
You forgot to link the paper you mentioned (at 12:43). For all who are interested: I think it was about this paper:
"Convolutional Neural Networks for Sentence Classification" by Yoon Kim
Great content.
Hey there! I normally don’t leave comments, or likes but I had to stop here!
You’ve explained a convoluted topic in a clear, digestible and concise way. Thank you!
Really nice explanations even if the convolution network internals are not enough explained.
this is the best explanation i've seen on CNN applied on text input
One of best lecture i have heard ever. Seriously i was totally in to your video for 15mins, which i forgot external world. Awaiting for next set of topics.
Soon we will upload the next video of this series! If you liked the video, please press the like button so that other people can find this video!
Regards
I have subscribed, added push notification, liked videos.
@@MachineLearningTV at 11:19 I am confused about why each gram we learn 100 filters? What is the filter in this case? I thought by applying the 3-gram kernel using the same padding, we will get (1,n) vector, where n: number of words in this case n=5. Then we have 3,4,5 gram, shouldn't we just have 3 (1,n) vectors? If we get max value for each gram, shouldn't we just have 3 outputs, where each output from each x-gram vector (size =(1,n))? Can you explain why you said 300 outputs? Thanks,
This is the most comprehensive video I've ever seen on neural networks! Thank you so much! I study and develop AI, but was using something more like the bag of words representation. The other thing, aside from accuracy that I noticed to be an issue with the bag of words representation, was actually the amount of resources it required from the machine it was operating on. To give some insight into just how bad it was, while the machine I was using wasn't exactly top of the line, the machine I'm using now is pretty high performance (i5-8400, 16gb RAM, 1TB Samsung Evo 860 SSD) and yet, the facial recognition usually dropped down the camera feed to about 3-5fps when it would detect a face. Even generating a response (using Speech-to-Text, then a custom-tailored version of the Levenshtein Distance algorithm to correct any misinterpretation of speech) was using at least 7GB of RAM even with a relatively small data set in the vicinity of maybe 50GB, and using 40-60% of my CPU power. Anyhow, my intent with watching this video was to learn about better algorithms, with the intent of actually implementing a neural network on an FPGA (Field-Programmable-Gate-Array). Now I feel well-equipped with enough information to conquer that finally, as I feel I finally understand CNNs well enough. Thanks so much!
Thanks for your feedback
How would you go about getting started if you have a decent grasp of python and are trying to get into the space?
This is not a pretty high performance setup. This is an average PC
I bought a PC for 3d rendering and it's a 32 cores CPU E5-2670 0 @ 2.60GHz, 128GB of RAM and storage is a some kind of SSD on PCI-E. Pretty good setup
i5-8400 is horrible lol, definitely not high performance.
@@GameChanger77 Dude this post was from 3 years ago. Also, thank you for wasting both of our time by commenting this! Have a great day
2:05 freudian slip? made me crack up haha
Excellent video, thanks for sharing!
Your explanation was great, thx
One of the best videos to understand string inputs for Neural Nets.
ua-cam.com/video/07resLdT7nI/v-deo.html
Wonderful explanation.
Fantastic! You have explained it very very well. Please upload more videos on related and Machine Learning topics. Thank you so much.
ua-cam.com/video/07resLdT7nI/v-deo.html
Excellent video. This video made me watch the whole playlist
ua-cam.com/video/07resLdT7nI/v-deo.html
IT is the best explanation of word embeddings ever seen
ua-cam.com/video/07resLdT7nI/v-deo.html
This is just brilliant!
Great work thanks. Can't wait for the next. Very well explained
Try original course: www.coursera.org/learn/language-processing
How does this compare with the attention mechanism in transformers?
Excelente
Thank you so much. Got clear idea.
ua-cam.com/video/07resLdT7nI/v-deo.html
excuse my stupidity, on 4:19 how do you get 0.9 from word embeddings and convolutional filter, is it a dot product? or some thing else?
Where did the 0.9 and 0.84 come from? Sorry, I'm new to this...
great efforts!!
at 11:19 I am confused about why each gram we learn 100 filters? What is the filter in this case? I thought by applying the 3-gram kernel using the same padding, we will get (1,n) vector, where n: number of words in this case n=5. Then we have 3,4,5 gram, shouldn't we just have 3 (1,n) vectors? If we get max value for each gram, shouldn't we just have 3 outputs, where each output from each x-gram vector (size =(1,n))? Can you explain why you said 300 outputs? Thanks,
Amazing explanation! Thank you!
ua-cam.com/video/07resLdT7nI/v-deo.html
how to find values for convolution filter?
at 1:54 what are the inputs are they [very, good, movie] or are they the [x1, x2, x3].
top vidéo thanks !!!
Brilliant! Please share link to the next lecture.
Dear, in the description of the video you can find the link of the course.
@@MachineLearningTV I dint find any links in the description. Please provide the link
at 4:25, the result of convolution is not 0.9, it is 0.88. How CNN create these filters? For instance we defined 16 filters to apply. How CNN library determine the content of filters ( numbers) ?
Good question! These filters are learned through back-propagation!
Thanks man. May God guide you.
ua-cam.com/video/07resLdT7nI/v-deo.html
What about the context of the text. Why would you use this rather than use something like a GRU or LSTM
Please, explain the meaning of the final vector obtained after the 1d convolution and i guess, trained in some way.
Need your advice for my ML project. Please help
what do i need to learn before can follow this video? i can't follow the explanation after hearing "bags of words" and the "neural network"
Linear algebra would be a start.
@@Ragnarok540 thanks man
1:20 "good movie very" ?
This seems to use lots of terms that are undefined here. Is this part of a larger presentation? If so, numbering the parts would be useful.
If not, then this really expect you to know a lot about the terminology before watching. Frankly, I find this completely confusing.
do we always need a vector representation before neural network??
Yup
@@ruslanmurtazin7918 but that may be in case for feature eng in unsupervised learning. What about supervised learning algo..do we still need i this case?
Can you please tell me the precision and recall of this network?
ua-cam.com/video/07resLdT7nI/v-deo.html
thx sir its very nice lecture, i wanted to text processing on web page content can you take lecture on this
ua-cam.com/video/07resLdT7nI/v-deo.html
Sir mujhe bhi sikhna hai please🙏
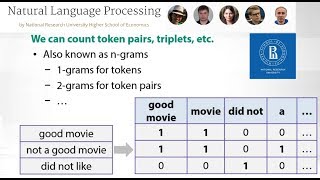
Sorry, but I do not understand why you do not use 2-grams windows. Without them the 2-grams are not taken into account.
How does one learn these filters?
These filters are learned by the Deep Learning algorithm. As a matter of fact, these filters are the weights that Neural Networks try to learn.
TFW you google in english but end up watching a russian video.
It’s elon musk from 2019
Please send me the paper link
Link to the paper please?
a kala
Very interesting video .... I need your Email...
I need code source please