Also please correct me if I am wrong but I think at minute 17 you should not use the same theta notation for both "g_theta()" and "p_theta()" since you assumed that you do not know the theta parameters (the main cause of differentiation problem) for "p()" but you know the parameters for "g()".
16:27 It's unclear (for me) (in context of gradient operator and expectation) why f_theta(z) can't be differentiated and WHY replacement of f_theta to g_theta(eps, x) allows to move gradient op inside of expectation and "make something differentiable" (from math point of view) p.s in practice we train MSE and KL divergence between two gaussians (q(z:x):p(z)) where p_mean = 0 and p_sigma = 1 and it allows us to "train" mean and var vectors in VAE
Thank you for the feedback :) I will try to address both items: 1. The replacement makes the function (or the neural network) deterministic and thus differentiable and smooth. Looking at the definition of the derivative can help understand this better: lim h->inf ( f(x+h) - f(x) / h ) where a slight change in x produces a small change in the derivative of f(x), makes the function "continuously differentiable". This is the case for the g function we defined in the video: a slight change in epsilon produces a slightly different z. On the other, i.i.d sampling does not have any relation for two subsequent samples, by definition, so the derivative is not smooth enough for the model to actually learn. 2. Yes, I've considered adding an explanation for the VAE loss function (ELBO) but I wanted the focus of the video to be solely on the trick itself since it can be used for other things like the Gumble Softmax Distribution. I will consider making future videos both on ELBO loss and Gumble Softmax Distribution.
@@ml_dl_explained Thank for an answer ! ❤ Ohh, I'm just missed that we make random sample.. my confusion was at 15:49 you have E_p_theta = "sum of terms" which are contains z(sample) and on the next slide you just remove them (by replacement z to epsilon and f -> g)
Yes, I understand your confusion. The next slide on re-parametrizes does not divide into two terms like in the "sum of terms" you described. This is because the distribution is not parametrized and so when calculating the gradient the case changes: Instead of a multiplication of two functions (p_theta(z)*f_theta(z) -- like we had in the first slide) we now only have one function and the distribution parameters are encapsulated inside of it (f_theta(g_theat(eps, x)) -- like we had in the second slide). Hope this helps :)
This was the analogy I got from ChatGPT to understand the problem 😅. Hope it's useful to someone: "Certainly, let's use an analogy involving shooting a football and the size of a goalpost to explain the reparameterization trick: Imagine you're a football player trying to score a goal by shooting the ball into a goalpost. However, the goalpost is not of a fixed size; it varies based on certain parameters that you can adjust. Your goal is to optimize your shooting technique to score as many goals as possible. Now, let's draw parallels between this analogy and the reparameterization trick: 1. **Goalpost Variability (Randomness):** The size of the goalpost represents the variability introduced by randomness in the shooting process. When the goalpost is larger, it's more challenging to score, and when it's smaller, it's easier. 2. **Shooting Technique (Model Parameters):** Your shooting technique corresponds to the parameters of a probabilistic model (such as `mean_p` and `std_p` in a VAE). These parameters affect how well you can aim and shoot the ball. 3. **Optimization:** Your goal is to optimize your shooting technique to score consistently. However, if the goalpost's size (randomness) changes unpredictably every time you shoot, it becomes difficult to understand how your adjustments to the shooting technique (model parameters) are affecting your chances of scoring. 4. **Reparameterization Trick:** To make the optimization process more effective, you introduce a fixed-size reference goalpost (a standard normal distribution) that represents a known level of variability. Every time you shoot, you still adjust your shooting technique (model parameters), but you compare your shots to the reference goalpost. 5. **Deterministic Transformation:** This reference goalpost allows you to compare and adjust your shooting technique more consistently. You're still accounting for variability, but it's structured and controlled. Your technique adjustments are now more meaningful because they're not tangled up with the unpredictable variability of the changing goalpost. In this analogy, the reparameterization trick corresponds to using a reference goalpost with a known size to stabilize the optimization process. This way, your focus on optimizing your shooting technique (model parameters) remains more effective, as you're not constantly grappling with unpredictable changes in the goalpost's size (randomness)."
I have a small question about the video, that slightly bothers me. What this normal distribution we are sampling from consists of? If it's distribution of latent vectors, how do we collect them during training?
Thanks for the vid 👋 Actually lost the point in the middle of the math explanation, but that's prob because I'm not that familiar with VAEs and don't know some skipped tricks 😁 I guess for the field guys it's a bit more clear :)
Thank you very much for the positive feedback 😊. Yes, the math part is difficult to understand and took me a few tries until I eventually figured it out. Feel free to ask any question about unclear aspects and I will be happy to answer here in the comments section.
You will often hear people talk about expectation being a linear operator, particularly when it comes to this fact about derivatives. Linearity of Differentiation property in calculus tells us this works for all linear transformations of functions.



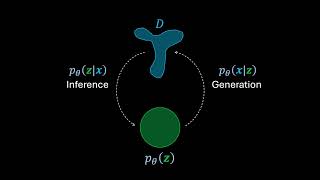






Sometimes understanding the complexity makes a concept clearer. This was one such example. Thanks a lot.
WOW! THANK U. FINALLY MAKING IT EASY TK UNDERSTAND. WATCHED SO MANY VIDEOS ON VAE AND THEY JUST BRIEFLY GO OVER THE EQUATION WITHOUT EXPLAINING
Holy God. What a great teacher..
Amazing explanation
Thank you for your effort, it all tied up nicely at the end of the video. This was clear and useful.
Thank you for the positive feedback
Very nice video, it helped me a lot. Finally someone explaining math without leaving the essential parts aside.
Thanks, this is a good explanation of the black point of VAE
Great work. Thanks...
Thank you, I liked your intuition, amazing effort.
Also please correct me if I am wrong but I think at minute 17 you should not use the same theta notation for both "g_theta()" and "p_theta()" since you assumed that you do not know the theta parameters (the main cause of differentiation problem) for "p()" but you know the parameters for "g()".
Very good explanation thank you
Thank you for this video, this has helped a lot in my own research on the topic
This is a life changing video, thank you very much 😊 🙏🏻
Thank you so much! Please continue with more videos on ML.
Will do :) let me know if you have a specific topic in mind.
Thank you for this video, this has helped me a lot
very clear explanation. subscribed!
Thanks for the video ,subbed!
Great video! Extremely clear :)
super clear explained, thanks
Your explanation is brilliant! We need more thinks like this. Thank you!
Thank you very much for the positive feedback!
Beautifully said. Love how you laid out things, both the architecture and math. Thanks a million.
Glad you enjoyed it!
16:27 It's unclear (for me) (in context of gradient operator and expectation) why f_theta(z) can't be differentiated and WHY replacement of f_theta to g_theta(eps, x) allows to move gradient op inside of expectation and "make something differentiable" (from math point of view)
p.s
in practice we train MSE and KL divergence between two gaussians (q(z:x):p(z)) where p_mean = 0 and p_sigma = 1 and it allows us to "train" mean and var vectors in VAE
Thank you for the feedback :)
I will try to address both items:
1. The replacement makes the function (or the neural network) deterministic and thus differentiable and smooth. Looking at the definition of the derivative can help understand this better: lim h->inf ( f(x+h) - f(x) / h ) where a slight change in x produces a small change in the derivative of f(x), makes the function "continuously differentiable". This is the case for the g function we defined in the video: a slight change in epsilon produces a slightly different z. On the other, i.i.d sampling does not have any relation for two subsequent samples, by definition, so the derivative is not smooth enough for the model to actually learn.
2. Yes, I've considered adding an explanation for the VAE loss function (ELBO) but I wanted the focus of the video to be solely on the trick itself since it can be used for other things like the Gumble Softmax Distribution. I will consider making future videos both on ELBO loss and Gumble Softmax Distribution.
@@ml_dl_explained
Thank for an answer ! ❤
Ohh, I'm just missed that we make random sample..
my confusion was at 15:49 you have E_p_theta = "sum of terms" which are contains z(sample) and on the next slide you just remove them (by replacement z to epsilon and f -> g)
Yes, I understand your confusion. The next slide on re-parametrizes does not divide into two terms like in the "sum of terms" you described. This is because the distribution is not parametrized and so when calculating the gradient the case changes: Instead of a multiplication of two functions (p_theta(z)*f_theta(z) -- like we had in the first slide) we now only have one function and the distribution parameters are encapsulated inside of it (f_theta(g_theat(eps, x)) -- like we had in the second slide).
Hope this helps :)
This was the analogy I got from ChatGPT to understand the problem 😅. Hope it's useful to someone:
"Certainly, let's use an analogy involving shooting a football and the size of a goalpost to explain the reparameterization trick:
Imagine you're a football player trying to score a goal by shooting the ball into a goalpost. However, the goalpost is not of a fixed size; it varies based on certain parameters that you can adjust. Your goal is to optimize your shooting technique to score as many goals as possible.
Now, let's draw parallels between this analogy and the reparameterization trick:
1. **Goalpost Variability (Randomness):** The size of the goalpost represents the variability introduced by randomness in the shooting process. When the goalpost is larger, it's more challenging to score, and when it's smaller, it's easier.
2. **Shooting Technique (Model Parameters):** Your shooting technique corresponds to the parameters of a probabilistic model (such as `mean_p` and `std_p` in a VAE). These parameters affect how well you can aim and shoot the ball.
3. **Optimization:** Your goal is to optimize your shooting technique to score consistently. However, if the goalpost's size (randomness) changes unpredictably every time you shoot, it becomes difficult to understand how your adjustments to the shooting technique (model parameters) are affecting your chances of scoring.
4. **Reparameterization Trick:** To make the optimization process more effective, you introduce a fixed-size reference goalpost (a standard normal distribution) that represents a known level of variability. Every time you shoot, you still adjust your shooting technique (model parameters), but you compare your shots to the reference goalpost.
5. **Deterministic Transformation:** This reference goalpost allows you to compare and adjust your shooting technique more consistently. You're still accounting for variability, but it's structured and controlled. Your technique adjustments are now more meaningful because they're not tangled up with the unpredictable variability of the changing goalpost.
In this analogy, the reparameterization trick corresponds to using a reference goalpost with a known size to stabilize the optimization process. This way, your focus on optimizing your shooting technique (model parameters) remains more effective, as you're not constantly grappling with unpredictable changes in the goalpost's size (randomness)."
oh my god !! So good.
dam nice bro, thank you for this
Thanks for explenation
it is reaally fantastic
Isn't the random node, e, used here is to parameterize the latent space with e, such that the user can explore the space with e?
I have a small question about the video, that slightly bothers me. What this normal distribution we are sampling from consists of? If it's distribution of latent vectors, how do we collect them during training?
your'e voice is literally from Giorgio by moroder song
Thanks for the vid 👋
Actually lost the point in the middle of the math explanation, but that's prob because I'm not that familiar with VAEs and don't know some skipped tricks 😁
I guess for the field guys it's a bit more clear :)
Thank you very much for the positive feedback 😊.
Yes, the math part is difficult to understand and took me a few tries until I eventually figured it out. Feel free to ask any question about unclear aspects and I will be happy to answer here in the comments section.
Perfect!
Thank you so much for your video! It definitely saved my life :)
You are most welcome :)
It is cool although I don't really understand the second half. 😅
The derivative of the expectation is the expectation of the derivative? That's surprising to my feeble mind.
You will often hear people talk about expectation being a linear operator, particularly when it comes to this fact about derivatives. Linearity of Differentiation property in calculus tells us this works for all linear transformations of functions.
They're both linear, and commute.
dope