OUTLINE: 0:00 - Intro & Overview 2:30 - Problem Statement 8:00 - Probabilistic formulation of dynamic halting 14:40 - Training via unrolling 22:30 - Loss function and regularization of the halting distribution 27:35 - Experimental Results 37:10 - Sensitivity to hyperparameter choice 41:15 - Discussion, Conclusion, Broader Impact
I believe that the recurrent structure is the reason that they're able to maintain stability despite attempting to solve two problems at once. My feeling is that the reason it's typically bad to solve two problems at once is that you will be inconsistent about credit assignment in ways that are determined by incidental noise. The incidental noise washes out, in a within-sample sense (as opposed to an across-sample one, which wouldn't be sufficient), due to the recurrent structure of the model. Learning how to do credit assignment correctly in the sense needed for the particular sample under situation is encouraged by the architecture. Across-sample washing out of incidental noise doesn't work because each sample has a different credit assignment problem associated with it. But for a given sample, at different time steps in the network's operation, the underlying credit assignment problem to be solved remains the same.
Thanks for reviewing this! I love papers that push for different approaches, I think another interesting field coming up is making more things differentiable like rendering (I am sure you saw that recent painting transformer paper) or optimization. A benchmark I wish they did for PonderNet was learning how to sum and do other operations on integers, since it seems to be something quite hard even for the largest transformers.
@@WatchAndGame Paint Transformer: Feed Forward Neural Painting with Stroke Prediction What they do is very similar to DETR (a paper Yannic reviewed), the architecture is quite simple but the core thing they need is a neural renderer, something that can take as input the strokes to draw and actually displays them on an image all while being differentiable in order to backpropagate to the rest of the architecture. This helps them in not needing to use Reinforcement Learning, which is usually much less stable.
@@Supreme_Lobster The main issue of RL is that, while you can make *part of it* differentiable (Deep Q Learning, Policy Gradient), you usually don't have a differentiable model of the game state and no information over what causes a good reward (so you can't have backpropagate a loss over "Hey I want the end game screen to look like this"). Think for example in Chess: you get a reward only at the end of the game (win/lose) but you don't have information over what specific action was good and what was bad, this is called the "Score Assignment Problem" and a lot of algorithms try tackling this but it's still largely unsolved. This isn't to say that RL is impossible, but it's one of the areas where ML still struggles a lot, all methods we use are still very specific, are unstable (some runs may converge to a good game playing agent, some don't, out of pure chance) and require **TONS** of compute power for anything non trivial. Meanwhile if you check the paper of painting transformer, their differentiable renderer allowed them to just optimize everything based on the desired image loss; compared to other approaches that solve the same problem they trained it much faster and are able to run it faster too (check their benchmarks)
21:20 my impression is that the (?)regularization(?) or, err, the term they add to make it prefer to halt earlier if it can while still having good results, should somewhat counteract that? But maybe it wouldn’t be enough, I wouldn’t know Edit: nvm you were about to get to that part Oh good, I remembered that word “regularization” correctly.
Hello Yannic, you confused P with Lambda in the loss function. Pn=Ln * prod(1-Li). This is why the trivial solution is not making all lambdas equal to zero.
Nice! I normally take notes while watching these and often leave side notes to myself about stuff I didn't understand in order to look into further in the paper. But this time I paused and wrote a note that I was confused about the loss function because I don't get how they handle the risk of λ going to 0 and the 2 variable problem being unstable....... unpause and you say basically the exact same concerns. I feel like I actually must have understood an ML paper at first glance for once! It was very gratifying, haha. I think the regularization term does a lot of work in forcing the loss to push towards a sane output though. But that creates an assumption on calculations that might not follow in the real world. I mean, if I'm given a math problem, I don't gradually improve my understanding past some threshold, some math problems are instant, some I can't solve. At least at first glance, as I type this, I don't think that this algorithm will be as useful on types of problems that have highly variable amounts of computation needed but I'd probably have to implement to be certain.
As always, you've made another fascinating video. Thank you. What I wonder is what kinds of models can be trained and used for inference using this architecture on small GPUs? Does this open up possibilities given resource constraints? Can I get GPT3-like performance on a K80 using PonderNet because my network isn't so deep? Or is this just a way to speed up inference? I suppose that with each pass through the model, the combinations of parameters multiply to a Cartesian product, but it's not intuitive to me how this works with a backward pass. After all, this doesn't seem to give new functionality over a feed forward model other than the ability to halt early. In other words, only the same kinds of things can be learned, but perhaps they can be learned more quickly.
i'm no expert but...seems like a dreamcoder punishing Kolmogorov complexity works better for parity, and the general idea of 'aligning model & task complexity?
I wonder if one can just use the expectation of the distribution induced by p_i as a regularizer. Such regularizer would not force a geometric shape on p_i, just ask it to make fewer steps. And the network would be able to model things like sudden changes in p_i more easily.
Hi, thanks for your video!. I plan to do a project on the complexity of tasks on image dataset like imagenet, cifar 100. If I use a vision transformer, then can I implement my project? and Is it meaningful?
I don't see how the training works with that added output of every timestep. By adding all possible outputs and their probabilties, you get an overall, statistical error but no feedback signal for individual outputs?
Yes it does! In the bAbI, they compare them with transformers + pondernet and they seem to do better, but imo the big deal of the paper is that the architecture is very general and can be applied on anything you might think of
@@mgostIH So there isn't really an "architecture" in the sense of, say, Transformers vs LSTMs. The contribution is more: (1) The clearer formulation (?), and (2) The corrected term for the stopping probability. Yes?
@@aspergale9836 Indeed, you can apply this method for pretty much any DL model you can think of, instead of putting more layers you use this procedure so that the network learns how deep it needs to be per each input. In this sense, it's similar to Deep Equilibrium Models, without the need to redefine backpropagation.
Maybe I'm just a noob and I'm missing something... But why not just train a feed forward network to do a halting mechanism on another simple CNN like a nn manager? Seems way simpler than integrating the halting procedure in a single network
There's a hyperparameter determining the minimum cumulative halt probability before ending network rollouts. I'm guessing that when calculating the expected loss, they normalize by the actual cumulative halt probability of the rollouts during training?

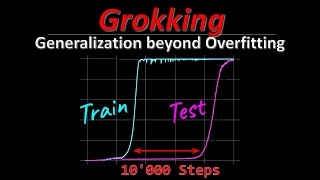






OUTLINE:
0:00 - Intro & Overview
2:30 - Problem Statement
8:00 - Probabilistic formulation of dynamic halting
14:40 - Training via unrolling
22:30 - Loss function and regularization of the halting distribution
27:35 - Experimental Results
37:10 - Sensitivity to hyperparameter choice
41:15 - Discussion, Conclusion, Broader Impact
Yasss! paper explained is back! :D
About time...
Thank you sir. An international treasure.
Amazing! So happy to see paper explained series back!
I believe that the recurrent structure is the reason that they're able to maintain stability despite attempting to solve two problems at once. My feeling is that the reason it's typically bad to solve two problems at once is that you will be inconsistent about credit assignment in ways that are determined by incidental noise. The incidental noise washes out, in a within-sample sense (as opposed to an across-sample one, which wouldn't be sufficient), due to the recurrent structure of the model. Learning how to do credit assignment correctly in the sense needed for the particular sample under situation is encouraged by the architecture.
Across-sample washing out of incidental noise doesn't work because each sample has a different credit assignment problem associated with it. But for a given sample, at different time steps in the network's operation, the underlying credit assignment problem to be solved remains the same.
So glad to watch your paper introduction video again :-)
Thanks for reviewing this! I love papers that push for different approaches, I think another interesting field coming up is making more things differentiable like rendering (I am sure you saw that recent painting transformer paper) or optimization.
A benchmark I wish they did for PonderNet was learning how to sum and do other operations on integers, since it seems to be something quite hard even for the largest transformers.
Could you tell me what this "painting paper" is called? I am interested :)
@@WatchAndGame Paint Transformer: Feed Forward Neural Painting with Stroke Prediction
What they do is very similar to DETR (a paper Yannic reviewed), the architecture is quite simple but the core thing they need is a neural renderer, something that can take as input the strokes to draw and actually displays them on an image all while being differentiable in order to backpropagate to the rest of the architecture. This helps them in not needing to use Reinforcement Learning, which is usually much less stable.
@@mgostIH Cool thanks!
@@mgostIH is RL not differentiable. I'm quite new to ML and NNs and I'm entirely sure what "differentiable" means, other than "you can backpropagate"
@@Supreme_Lobster The main issue of RL is that, while you can make *part of it* differentiable (Deep Q Learning, Policy Gradient), you usually don't have a differentiable model of the game state and no information over what causes a good reward (so you can't have backpropagate a loss over "Hey I want the end game screen to look like this").
Think for example in Chess: you get a reward only at the end of the game (win/lose) but you don't have information over what specific action was good and what was bad, this is called the "Score Assignment Problem" and a lot of algorithms try tackling this but it's still largely unsolved.
This isn't to say that RL is impossible, but it's one of the areas where ML still struggles a lot, all methods we use are still very specific, are unstable (some runs may converge to a good game playing agent, some don't, out of pure chance) and require **TONS** of compute power for anything non trivial.
Meanwhile if you check the paper of painting transformer, their differentiable renderer allowed them to just optimize everything based on the desired image loss; compared to other approaches that solve the same problem they trained it much faster and are able to run it faster too (check their benchmarks)
Welcome back Yannic! I've missed your videos.
Love your work. Very clear explanation. Indeed an interesting innovation.
21:20 my impression is that the (?)regularization(?) or, err, the term they add to make it prefer to halt earlier if it can while still having good results, should somewhat counteract that? But maybe it wouldn’t be enough, I wouldn’t know
Edit: nvm you were about to get to that part
Oh good, I remembered that word “regularization” correctly.
Hello Yannic, you confused P with Lambda in the loss function. Pn=Ln * prod(1-Li). This is why the trivial solution is not making all lambdas equal to zero.
He acknowledged that later
Omg a new papers explAIned video 😍 my brain is about to explode.
Welcome Back!!!
Nice! I normally take notes while watching these and often leave side notes to myself about stuff I didn't understand in order to look into further in the paper. But this time I paused and wrote a note that I was confused about the loss function because I don't get how they handle the risk of λ going to 0 and the 2 variable problem being unstable....... unpause and you say basically the exact same concerns. I feel like I actually must have understood an ML paper at first glance for once! It was very gratifying, haha.
I think the regularization term does a lot of work in forcing the loss to push towards a sane output though. But that creates an assumption on calculations that might not follow in the real world. I mean, if I'm given a math problem, I don't gradually improve my understanding past some threshold, some math problems are instant, some I can't solve. At least at first glance, as I type this, I don't think that this algorithm will be as useful on types of problems that have highly variable amounts of computation needed but I'd probably have to implement to be certain.
Love such papers! So much better than 'all you need' hype
As always, you've made another fascinating video. Thank you. What I wonder is what kinds of models can be trained and used for inference using this architecture on small GPUs? Does this open up possibilities given resource constraints? Can I get GPT3-like performance on a K80 using PonderNet because my network isn't so deep? Or is this just a way to speed up inference? I suppose that with each pass through the model, the combinations of parameters multiply to a Cartesian product, but it's not intuitive to me how this works with a backward pass. After all, this doesn't seem to give new functionality over a feed forward model other than the ability to halt early. In other words, only the same kinds of things can be learned, but perhaps they can be learned more quickly.
i'm no expert but...seems like a dreamcoder punishing Kolmogorov complexity works better for parity, and the general idea of 'aligning model & task complexity?
I was kinda hoping for ablation for the KL divergence. Good stuff though.
What an interesting idea!
Interesting. Good explanation
I wonder if one can just use the expectation of the distribution induced by p_i as a regularizer. Such regularizer would not force a geometric shape on p_i, just ask it to make fewer steps. And the network would be able to model things like sudden changes in p_i more easily.
Consider doing a video on PerceiverIO, it's a major upgrade to vanilla Perceiver and I can easily see it's descendants taking over many areas
Hello Yannic! Can you teach us to matrix multiply without multiplying?
Hi, thanks for your video!.
I plan to do a project on the complexity of tasks on image dataset like imagenet, cifar 100. If I use a vision transformer, then can I implement my project? and Is it meaningful?
Yannic, please do a video on the new Fastformer
the recurrent part seems somewhat like GAN? the ACT is like ada boost while PonderNet is like boosting tree.
41:00 "it is completely thinkable" lol I think the word you're looking for is plausible?
I don't see how the training works with that added output of every timestep.
By adding all possible outputs and their probabilties, you get an overall, statistical error but no feedback signal for individual outputs?
It's Monday, folks!!!
Can you do a Tesla ai day review.
22:18 Why can't you just add a small loss just for low probability, so that it tries to increase it?
Does the paper references universal transformers?
Yes it does! In the bAbI, they compare them with transformers + pondernet and they seem to do better, but imo the big deal of the paper is that the architecture is very general and can be applied on anything you might think of
@@mgostIH So there isn't really an "architecture" in the sense of, say, Transformers vs LSTMs. The contribution is more: (1) The clearer formulation (?), and (2) The corrected term for the stopping probability. Yes?
@@aspergale9836 Indeed, you can apply this method for pretty much any DL model you can think of, instead of putting more layers you use this procedure so that the network learns how deep it needs to be per each input.
In this sense, it's similar to Deep Equilibrium Models, without the need to redefine backpropagation.
Maybe I'm just a noob and I'm missing something... But why not just train a feed forward network to do a halting mechanism on another simple CNN like a nn manager? Seems way simpler than integrating the halting procedure in a single network
That's entirely possible in this framework. The step function can be two different NNs, or a combined one.
Did anyone catch how they normalized the probabilities (lambdas) across time?
There's a hyperparameter determining the minimum cumulative halt probability before ending network rollouts. I'm guessing that when calculating the expected loss, they normalize by the actual cumulative halt probability of the rollouts during training?
QUICK YANNIC! THE TESLA AI DAY IS OUT!
No hurry. It can be stressful. Some are so eager that they do not love slow paced videos. But yeah, we would love you to present those Tesla snippets.
Lex Fridman did a review of that, you can check it out
General Kenobi
Hello there
Holla Todos
I dislike the wishful mnemonics in the paper's title
Be honest, Yan, you down vote your own vids right? Lol you've got a loyal hater out there if not
All things in the universe must have balance :D