25 - Bayesian inference in practice - Disease prevalence

Вставка
- Опубліковано 4 жов 2024
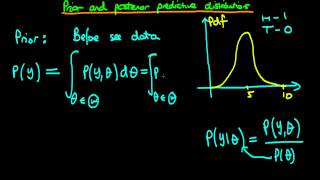
- This video provides an example of applied Bayesian inference, for the case of predicting the disease prevalence within a population.
If you are interested in seeing more of the material, arranged into a playlist, please visit: • Bayesian statistics: a... Unfortunately, Ox Educ is no more. Don't fret however as a whole load of new youtube videos are coming soon, along with a book that accompanies the series: www.amazon.co.... Alternatively, for more information on this video series and Bayesian inference in general, visit: ben-lambert.co... For more information on econometrics and Bayesian statistics, see: ben-lambert.com/








Lovely video Ben! As usual.
This is great leture!!! I really appreciate this!!! It has helped me very much!!
Super helpful! thanks
What if we want the prior to carry more weight? I realise that we could do this by making it more extreme and concentrated, but what if we don't want to do that. For example, what if I have seen something happen a million times previously but never recorded the data, but I trust my memory and have a strong handle on what I believe distribution of the parameter should be. Then we receive 1000 new observations (a high number, but nowhere near the million unrecorded), we might not want the data to dominate in such a circumstance
Your memory on seeing it happen a million times before is what influences the prior to be so extreme. If you made the prior less extreme that would be contradicting your memory.
Best to think of the prior as an 'informed guess' based on your knowledge of the system. The strength of the prior function will depend on how well you know the system. In your case of seeing it a million times your informed guess should be pretty accurate, therefore making the prior more extreme. On the other hand if you knew nothing about the system your prior would be a flat beta(1,1) distrubution and the posterior would only be influenced by the measurements you make after your 1000 new observations.
@@shokker2445 i may be missing something, but what if although seeing it happen a million times, it was quite variable, such that I had a really good handle not just on the location, but the uncertainty around it. Would this need to be Weighted in some way so that it isn't the dominated by the new 1000 cases? Let's say they are all found in one tail of the original prior
Well the prior would be weighted very strongly since you have a good understand of the system. It doesn’t matter whether it is a binomial distribution (coin toss for example) or a completely flat beta(1,1) distribution (such as a random number generator). The weighting of the prior is determined by how well you know the system. After a million previous measurements you should have a good idea and therefore it will be weighted much more strongly than the 1000 measurements. Those 1000 measurements could alter the system slightly to get the posterior, and you could then use that posterior as a new prior for another 1000 measurements. This cycle can be repeated as many times as you like.
I am confused for the weight function of w'. If I cross out the values, wouldn't N also be decreasing the whole w'?