This list of videos is amazing. It helps me understand more about the task and also its components. I am looking forward to the Anchor Boxes Generation video. Hope it will be up soon!
Thank a lot, this was an amazing explanation! just a question. Why do we need anchor boxes to be a pre-set value when we can just use the original bbox values? Like we use the center of the original bbox and its W and H values. I dont understand this
Network will still make many predictions but we only want to compute the loss for few of them that are near to the ground truth box. Also think about when you have many ground truth objects in an image. If you compare all anchor boxes with all ground box then network will not learn anything
At 8:06, you said, "we will be placing these 3 prior bounding boxes on all cells no matter if they have ground truth bounding boxes or not". Does this apply to YOLO as well pleasE?
Waiting for intuitive explanation of mAP. Although I know it mathematically, I am trying to understand it's real meaning. Will be waiting for your thoughts on it. Thanks a lot for making such high quality content.
Hi, thank you so much for the amazingly intuitive explanation building up the motivation for anchor boxes from foundational concepts! Just had one quick question regarding the criteria used to assign anchor boxes to ground-truths. Do we assign a ground-truth to the anchor box it has the highest IoU with, or do we assign an anchor box to the ground-truth it has the highest IoU with? The former approach may result in an anchor box being assigned to multiple ground-truths (if we have objects very close together in the image) which may confuse the model when it tries to learn optimal offsets. The latter approach may result in some ground-truths not being covered but this can be mitigated by having "enough" anchors. Am I right in my understanding and can you please elaborate a bit on this?
We assign an anchor box (or anchor boxes) to a ground truth. This means that to a ground truth box one or more anchor boxes can be associated. But a given anchor box can not be associated with more than one ground truth box.
if I understood it correctly, Anchor Boxes are instructions about the dimensions for a particular class e.g. a cow's anchor box will be wide with low height a giraffe's anchor box will be tall this is done to refine the number of predictions with our prior knowledge of the domain right sir?
Yes. Since we know the classes of objects we intend to predict will will create the anchor boxes with width and height that are suitable for those objects. I will describe this in the follow up tutorial.
so, each cell in feature map has 'n' anchor boxes and 1 out of n correspond to 1 out of (m+1) classes, where m is the number of ground truth classes. Its not necessary for n=m ?
I don't understand something, we don't have the thuth box if we predict an object ? How can we now were is the ground truth whitout the coordinate ? thx
Not sure if I understand your comment completely. But here is an attempt - During training you do have the ground truth boxes. The concept of anchor boxes is that you start with some assumed prediction boxes and regress them towards the ground truth boxes. The reason to assume these anchor boxes at the start of training is because the image (and feature) space is vast.
@@KapilSachdeva Thank you very much for your reply, would you be available to contact you, as I have to do a presentation and would like some advice please.
If I understand correctly, we pick one anchor box that has the highest IoU with the ground truth and then fine tune the center coordinates, width and height to get final predictions. Is NMS still required since we go with a single prediction?
No it means there are 3 bounding boxes are being predicted per cell. For each bounding box there will be 4 numbers for the offsets, 1 for objectness and m numbers for classes. For e.g if you have 5 classes then m=5









This list of videos is amazing. It helps me understand more about the task and also its components. I am looking forward to the Anchor Boxes Generation video. Hope it will be up soon!
🙏
Really helpful video, especially for someone new to Object Detection
Does YOLOv2 does something similar to what you explained in 6:39 please?
Yes
Thank a lot, this was an amazing explanation! just a question. Why do we need anchor boxes to be a pre-set value when we can just use the original bbox values? Like we use the center of the original bbox and its W and H values. I dont understand this
Second question, why at 4:00, why comparing ground truth BB with all predicitons would cause the network to make many predicitons please?
Network will still make many predictions but we only want to compute the loss for few of them that are near to the ground truth box. Also think about when you have many ground truth objects in an image. If you compare all anchor boxes with all ground box then network will not learn anything
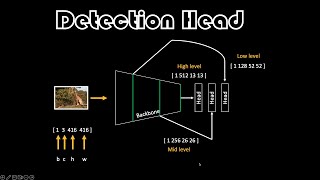
Great video. I did not understand the equation in minute 2:48 please? 416/13=32 what does it mean ?
It shows that the feature map of 13X13 was obtained at the stride of 32. Or, the image dimensions were reduced by the factor of 32
Why now we can apply criteria for selecting the bounding box at 7:11 but we were not able before please?
Not sure I understood your question.
At 8:06, you said, "we will be placing these 3 prior bounding boxes on all cells no matter if they have ground truth bounding boxes or not". Does this apply to YOLO as well pleasE?
Yes
Waiting for intuitive explanation of mAP. Although I know it mathematically, I am trying to understand it's real meaning. Will be waiting for your thoughts on it. Thanks a lot for making such high quality content.
Yes. Will explain mAP as part of this series. It is on my list.
Hi, thank you so much for the amazingly intuitive explanation building up the motivation for anchor boxes from foundational concepts! Just had one quick question regarding the criteria used to assign anchor boxes to ground-truths.
Do we assign a ground-truth to the anchor box it has the highest IoU with, or do we assign an anchor box to the ground-truth it has the highest IoU with?
The former approach may result in an anchor box being assigned to multiple ground-truths (if we have objects very close together in the image) which may confuse the model when it tries to learn optimal offsets. The latter approach may result in some ground-truths not being covered but this can be mitigated by having "enough" anchors. Am I right in my understanding and can you please elaborate a bit on this?
We assign an anchor box (or anchor boxes) to a ground truth.
This means that to a ground truth box one or more anchor boxes can be associated. But a given anchor box can not be associated with more than one ground truth box.
if I understood it correctly, Anchor Boxes are instructions about the dimensions for a particular class
e.g. a cow's anchor box will be wide with low height
a giraffe's anchor box will be tall
this is done to refine the number of predictions with our prior knowledge of the domain
right sir?
Yes. Since we know the classes of objects we intend to predict will will create the anchor boxes with width and height that are suitable for those objects.
I will describe this in the follow up tutorial.
so, each cell in feature map has 'n' anchor boxes and 1 out of n correspond to 1 out of (m+1) classes, where m is the number of ground truth classes. Its not necessary for n=m ?
Not at all. N does not have to be same as M.
I don't understand something, we don't have the thuth box if we predict an object ? How can we now were is the ground truth whitout the coordinate ? thx
Not sure if I understand your comment completely. But here is an attempt -
During training you do have the ground truth boxes. The concept of anchor boxes is that you start with some assumed prediction boxes and regress them towards the ground truth boxes. The reason to assume these anchor boxes at the start of training is because the image (and feature) space is vast.
@@KapilSachdeva Thank you very much for your reply, would you be available to contact you, as I have to do a presentation and would like some advice please.
If I understand correctly, we pick one anchor box that has the highest IoU with the ground truth and then fine tune the center coordinates, width and height to get final predictions. Is NMS still required since we go with a single prediction?
NMS is not used during the training. It is only used during the test phase as we do not have the ground truth during test/inference.
So when you say three predictions per grid cell, did you mean you have three classes as an example?
No it means there are 3 bounding boxes are being predicted per cell. For each bounding box there will be 4 numbers for the offsets, 1 for objectness and m numbers for classes. For e.g if you have 5 classes then m=5