
- 41
- 417 495
Kapil Sachdeva
United States
Приєднався 26 вер 2013
"Work like Hell. Share all you know. Abide by your handshake. Have fun!" - Dan Geer
I saw this on my mentor’s internal profile page some 20 years back, I shamelessly stole it and made it mine .... years later I discovered Dan Geer, the author of this quote ...but it does not matter who said it, rather the key is to assimilate these adages, these words of wisdom in your very being and is equally important to keep them in your sight as the gentle reminder of what is important!
Amongst the many obligations and responsibilities that we all have, the one that remains most dear to me is to keep learning and then sharing what I learned. I have done this for as long as I can remember; very early on in my life, I had accidentally discovered that you learn more when you share what you know. This is one aspect of my life that has been very consistent & the one I cherish the most.
This youtube channel is my new medium of sharing what "I think I know"!
I saw this on my mentor’s internal profile page some 20 years back, I shamelessly stole it and made it mine .... years later I discovered Dan Geer, the author of this quote ...but it does not matter who said it, rather the key is to assimilate these adages, these words of wisdom in your very being and is equally important to keep them in your sight as the gentle reminder of what is important!
Amongst the many obligations and responsibilities that we all have, the one that remains most dear to me is to keep learning and then sharing what I learned. I have done this for as long as I can remember; very early on in my life, I had accidentally discovered that you learn more when you share what you know. This is one aspect of my life that has been very consistent & the one I cherish the most.
This youtube channel is my new medium of sharing what "I think I know"!
Eliminate Grid Sensitivity | Bag of Freebies (Yolov4) | Essentials of Object Detection
This tutorial explains a training technique that helps in dealing with objects whose center lies on the boundaries of the grid cell in the feature map.
This technique falls under the "Bag of Freebies" category as it adds almost zero FLOPS (additional computation) to achieve higher accuracy during test time.
Pre-requisite:
Bounding Box Prediction
ua-cam.com/video/-nLJyxhl8bY/v-deo.htmlsi=Fv7Bfgxd1I-atZF0
Important links:
Paper - arxiv.org/abs/2004.10934
Threads with a lot of discussion on this subject:
github.com/AlexeyAB/darknet/issues/3293
github.com/ultralytics/yolov5/issues/528
This technique falls under the "Bag of Freebies" category as it adds almost zero FLOPS (additional computation) to achieve higher accuracy during test time.
Pre-requisite:
Bounding Box Prediction
ua-cam.com/video/-nLJyxhl8bY/v-deo.htmlsi=Fv7Bfgxd1I-atZF0
Important links:
Paper - arxiv.org/abs/2004.10934
Threads with a lot of discussion on this subject:
github.com/AlexeyAB/darknet/issues/3293
github.com/ultralytics/yolov5/issues/528
Переглядів: 1 160
Відео


GIoU vs DIoU vs CIoU | Losses | Essentials of Object Detection
Переглядів 4,6 тис.Рік тому
This tutorial provides an in-depth and visual explanation of the three Bounding Box loss functions. Other than the loss functions you would be able to learn about computing per sample gradients using the new Pytorch API. Resources: Colab notebook colab.research.google.com/drive/1GAXn6tbd7rKZ1iuUK1pIom_R9rTH1eVU?usp=sharing Repo with results of training using different loss functions github.com/...
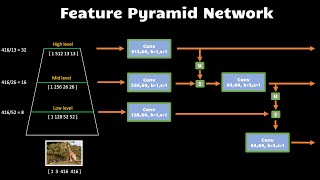
Feature Pyramid Network | Neck | Essentials of Object Detection
Переглядів 13 тис.Рік тому
This tutorial explains the purpose of the neck component in the object detection neural networks. In this video, I explain the architecture that was specified in Feature Pyramid Network paper. Link to the paper [Feature Pyramid Network for object detection] arxiv.org/abs/1612.03144 The code snippets and full module implementation can be found in this colab notebook: colab.research.google.com/dr...

Bounding Box Prediction | Yolo | Essentials of Object Detection
Переглядів 9 тис.Рік тому
This tutorial explains finer details about the bounding box coordinate predictions using visual cues.

Anchor Boxes | Essentials of Object Detection
Переглядів 11 тис.Рік тому
This tutorial highlights challenges in object detection training, especially how to associate a predicted box with the ground truth box. It then shows and explains the need for injecting some domain/human knowledge as a starting point for the predicted box.

Intersection Over Union (IoU) | Essentials of Object Detection
Переглядів 4,3 тис.Рік тому
This tutorial explains how to compute the similarity between 2 bounding boxes using Jaccard Index, commonly known as Intersection over Union in the field of object detection.
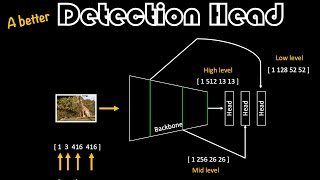
A Better Detection Head | Essentials of Object Detection
Переглядів 2,3 тис.Рік тому
This is a continuation of the Detection Head tutorial that explains how to write the code such that you can avoid ugly indexing into the tensors and also have more maintainable and extensible components. It would beneficial to first watch the DetectionHead tutorial Link to the DetectionHead tutorial: ua-cam.com/video/U6rpkdVm21E/v-deo.html Link to the Google Colab notebook: colab.research.googl...
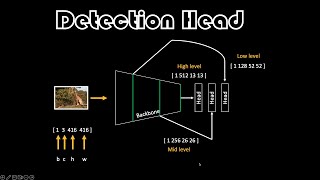
Detection Head | Essentials of Object Detection
Переглядів 5 тис.Рік тому
This tutorial shows you how to make the detection head(s) that takes features from the backbone or the neck. Link to the Google Colab notebook: colab.research.google.com/drive/1KwmWRAsZPBK6G4zQ6JPAbfWEFulVTtRI?usp=sharing

Reshape,Permute,Squeeze,Unsqueeze made simple using einops | The Gems
Переглядів 5 тис.Рік тому
This tutorial introduces to you a fantastic library called einops. Einops provides a consistent API to do reshape, permute, squeeze, unsqueeze and enhances the readabilty of your tensor operations. einops.rocks/ Google colab notebook that has examples shown in the tutorial: colab.research.google.com/drive/1aWZpF11z28KlgJZRz8-yE0kfdLCcY2d3?usp=sharing
Image & Bounding Box Augmentation using Albumentations | Essentials of Object Detection
Переглядів 7 тис.Рік тому
This tutorial explains how to do image pre-processing and data augmentation using Albumentations library. Google Colab notebook: colab.research.google.com/drive/1FoQKHuYuuKNyDLJD35-diXW4435DTbJp?usp=sharing
Bounding Box Formats | Essentials of Object Detection
Переглядів 7 тис.Рік тому
This tutorial goes over various bounding box formats used in Object Detection. Link the Google Colab notebook: colab.research.google.com/drive/1GQTmjBuixxo_67WbvwNp2PdCEEsheE9s?usp=sharing
Object Detection introduction and an overview | Essentials of Object Detection
Переглядів 9 тис.Рік тому
This is an introductory video on object detection which is a computer vision task to localize and identify objects in images. Notes - * I have intentionally not talked about 2-stage detectors. * There will be follow-up tutorials that dedicated to individual concepts
Softmax (with Temperature) | Essentials of ML
Переглядів 3,7 тис.2 роки тому
A visual explanation of why, what, and how of softmax function. Also as a bonus is explained the notion of temperature.
Grouped Convolution - Visually Explained + PyTorch/numpy code | Essentials of ML
Переглядів 4,8 тис.2 роки тому
In this tutorial, the need & mechanics behind Grouped Convolution is explained with visual cues. Then the understanding is validated by looking at the weights generated by the PyTorch Conv layer and by performing the operations manually using NumPy. Google colab notebook: colab.research.google.com/drive/1AUrTK622287NaKHij0YqOCvcdi6gVxhc?usp=sharing Playlist: ua-cam.com/video/6SizUUfY3Qo/v-deo.h...
Convolution, Kernels and Filters - Visually Explained + PyTorch/numpy code | Essentials of ML
Переглядів 2,1 тис.2 роки тому
This tutorial explains (provide proofs using code) the components & operations in a convolutional layer in neural networks. The difference between Kernel and Filter is clarified as well. The tutorial also points out that not all kernels convolve/correlate with all input channels. This seems to be a common misunderstanding for many people. Hopefully, this visual and code example can help show th...
Matching patterns using Cross-Correlation | Essentials of ML
Переглядів 1,2 тис.2 роки тому
Matching patterns using Cross-Correlation | Essentials of ML
Let's make the Correlation Machine | Essentials of ML
Переглядів 1,8 тис.2 роки тому
Let's make the Correlation Machine | Essentials of ML
Reparameterization Trick - WHY & BUILDING BLOCKS EXPLAINED!
Переглядів 11 тис.2 роки тому
Reparameterization Trick - WHY & BUILDING BLOCKS EXPLAINED!
Variational Autoencoder - VISUALLY EXPLAINED!
Переглядів 13 тис.2 роки тому
Variational Autoencoder - VISUALLY EXPLAINED!
Probabilistic Programming - FOUNDATIONS & COMPREHENSIVE REVIEW!
Переглядів 5 тис.3 роки тому
Probabilistic Programming - FOUNDATIONS & COMPREHENSIVE REVIEW!
Metropolis-Hastings - VISUALLY EXPLAINED!
Переглядів 34 тис.3 роки тому
Metropolis-Hastings - VISUALLY EXPLAINED!
Markov Chains - VISUALLY EXPLAINED + History!
Переглядів 14 тис.3 роки тому
Markov Chains - VISUALLY EXPLAINED History!
Monte Carlo Methods - VISUALLY EXPLAINED!
Переглядів 4,5 тис.3 роки тому
Monte Carlo Methods - VISUALLY EXPLAINED!
Conjugate Prior - Use & Limitations CLEARLY EXPLAINED!
Переглядів 3,4 тис.3 роки тому
Conjugate Prior - Use & Limitations CLEARLY EXPLAINED!
How to Read & Make Graphical Models?
Переглядів 3,1 тис.3 роки тому
How to Read & Make Graphical Models?
Posterior Predictive Distribution - Proper Bayesian Treatment!
Переглядів 6 тис.3 роки тому
Posterior Predictive Distribution - Proper Bayesian Treatment!
Sum Rule, Product Rule, Joint & Marginal Probability - CLEARLY EXPLAINED with EXAMPLES!
Переглядів 6 тис.3 роки тому
Sum Rule, Product Rule, Joint & Marginal Probability - CLEARLY EXPLAINED with EXAMPLES!
Noise-Contrastive Estimation - CLEARLY EXPLAINED!
Переглядів 11 тис.3 роки тому
Noise-Contrastive Estimation - CLEARLY EXPLAINED!
Bayesian Curve Fitting - Your First Baby Steps!
Переглядів 7 тис.3 роки тому
Bayesian Curve Fitting - Your First Baby Steps!
Maximum Likelihood Estimation - THINK PROBABILITY FIRST!
Переглядів 7 тис.3 роки тому
Maximum Likelihood Estimation - THINK PROBABILITY FIRST!
Hernandez Betty Lewis Kenneth Gonzalez Christopher
Haley Corner
You're awesome.
Moore Kevin Moore Sharon Lewis Richard
5:57 gave me the aha!-moment. Thank you so much!
선생님 감사합니다. 이 영상을 보고 MCMC를 깨우쳤습니다. 오래오래 건강하십시오.
So the bounding box comes with labeled data ?.....or we ourself are creating bounding box
What a clear explanation ! A gem.
Exactly what I was looking for, thank you!
Brilliant explanation! Thank you so much!
Thank you, the tutorial helped me a lot to get started with Einops.
209 Lisandro Ridge
Hernandez Michael Taylor Donald Walker Richard
8831 Osvaldo Heights
Excellent explanation. Please, continue doing that.
when we were calculating Pr(x>5) what is the role of h(x) here ? Cant we just use p(x)
Pagac Road
I have a question if it is possible for the sum of probabilities for future state to be greater than 1 as in the case of s3 at 14:04 in video...? It seems it should sum to 1 always.
Incredible explanatory skills!
awesome explanation!
Can you please guide me whether weight vector is column vector or row vector. It is creating confusion in multiplication. Thanks in advance for the great series.
Wilson Jose Lewis Matthew Smith Matthew
Thank you so much.
Thompson Cynthia Martin Frank Brown Jason
Awesome video. Is there any intuition on why we are using reverse KL as opposed to forward KL?
How do we evaluate the target function f, if we assume that it is not known and we want to discover it?
Garcia Larry Lewis Charles Hernandez Carol
Have been using Chris Bishop's new DL book and he reuses the same figure from PRML. Thanks for your video, the general equations are crystal clear now! ❤
Thank you for your work, you are a very talented and valuable teacher
then why not just use f(x), let c*g be a straight line equal to the maximum of f(x)
Amazing!!
Walker William Moore Patricia Perez Anthony
Very good explanation of Kalman filter, thanks for your time and work for that video.
Damn, einops is nice.
I just found your channel today and I am glad I did! Great stuff
Comparing to other videos, this one's fantastic.
Still not very clear to me why that hasting generalization is required? It would have been better if you had explicitly pointed out the problem statement with metropolis that requires generalization solution.
What is t1,t2..tn.. are these different instance of target variable? If so why each has different distribution. Are you assuming these categorical target variable and each has it own distribution? This part is confusing me in all the videos.
P(w|x) - what is x mean her exactly. Probability of weight given different data within training or different training set or something else?
How is this different from U-net? I think they're pretty similar if you think that in the U-net you're going down in the encoder, up in the decoder and sideways with the skip connections. It's like an upside-down U-net
Professor Kaiming He is the GOD of Deep Residual Networks .
How can we use these (predictions_box, predictions_obj, predictions_cls) information from the decoder and create visualizations on input image ?
Thank a lot, this was an amazing explanation! just a question. Why do we need anchor boxes to be a pre-set value when we can just use the original bbox values? Like we use the center of the original bbox and its W and H values. I dont understand this
This ground-up approach is excellent 🙂Thank you for explaining...
Thank you for posting this great video! At 3:53, why did you use a "squared" Euclidean distance, instead of an Euclidean distance? I wonder if you use an Euclidean distance, the properties of the "squared" Euclidean distance are the same?
Amazing !
Very intuitive explanation. Thank you.
Excellent overview. Highly appreciated.
Amazing, thx a lot.
What a wonderful explanation