Image Classification Using Vision Transformer | ViTs

Вставка
- Опубліковано 1 лип 2023
- Step by Step Implementation explained : Vision Transformer for Image Classification
Github: github.com/AarohiSingla/Image...
*******************************************************
For queries: You can comment in comment section or you can mail me at aarohisingla1987@gmail.com
*******************************************************
In 2020, Google Brain team introduced a Transformer-based model that can be used to solve an image classification task called Vision Transformer (ViT). Its performance is very competitive in comparison with conventional CNNs on several image classification benchmarks.
Vision transformer (ViT) is a transformer used in the field of computer vision that works based on the working nature of the transformers used in the field of natural language processing.
#transformers #computervision - Наука та технологія



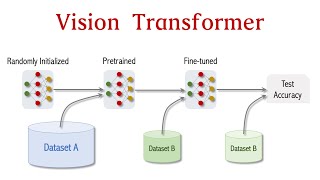





Dataset : universe.roboflow.com/search?q=flower%20classification
Dear Aarohi
Your channel is very knowledgeable & helpful for all Artificial Intelligence/ Data Scientist Professionals. Stay blessed & keep sharing such a good content.
I will try my best
hey, in the paper they said that there is a linear projection. im not sure that I fully understand where is the implementation of the linear projection? it is require a multiplication of the flattened patches with matrix, correct?
I think that I miss something, I've overviewed your embedding layer and im not sure where is the linear projection. If you can explain what im missing that would be great! thanks!
Very well explained, Madam, how to get the confusion matrix and other metrics such as f-1 score, precision, recall? How to check actually which test samples are detected correctly and which are not?
I'm student learning AI in Korea, your video helps me a lot, thanks for good material!
i'll try ViT for another image data.
please keep upload your video
Sure, Thanks!
@@CodeWithAarohi I have Q, I use colab for this code, every codes runs well but i cannot import going_modular.
how can i deal with this?
@@user-wx1ty7yj3r same issue are you able to solve?
where can i get that custom dataset
please correct me if i'm wrong here:
while applying the self.patcher with in class PatchEmbedding(nn.Module) (where you split the input image into 16x16 small patches then flatten),
on the forward method, you are also applying the convolution with random initial weights. hence your vectorization does not just vectorize the input image, it also apply a single layer of convolution to the image. this maybe a mistake. or i maybe mistaken
i have realized this issue after seing negative values on the output of
print(patch_embedded_image)
is vision transform support any other format(text format for yolov8n we are use for img and labels.)
It's very clear conceptual explanation, very rare. Keep teaching us.
Thank you, I will
very nice explanation! Patch Size, data loader of loading the images, resizing them and converting to tensors, efficient loading by giving batch size to optimize memory usage and more :)
Glad it was helpful!
Thanks for sharing, Great content
Thanks for watching
This is great, thank you so much for sharing and putting in all this effort.
Glad you enjoyed it!
thank u madam, sharing advanced concepts...
You're most welcome
Mam, could you please provide me the custom dataset that you've used on the video?
From your provided link, I couldn't find the exact dataset.
please make a landmark detection here in vision transformer. i greatly in need for this project to be finished and the task is to create a 13 landmark detection using vision transformer. and i cant find any resources that teaches how to do a landmark detection if vision transformer. this channel is my only hope.
wow
Thank you for the lovely tutorial and explanation!
Glad it helped you!
mam u r teaching standards are next level mam
Glad my videos are helpful 🙂
Informative Video
Glad you think so!
I am getting the following error any guide "RuntimeError:
An attempt has been made to start a new process before the
current process has finished its bootstrapping phase.
This probably means that you are not using fork to start your
child processes and you have forgotten to use the proper idiom
in the main module:
if __name__ == '__main__':
freeze_support()
...
The "freeze_support()" line can be omitted if the program
is not going to be frozen to produce an executable."
Excellent explanation, Thank you.
Glad you enjoyed it!
Please mam i have a little problem. The training is given but at the last cell of the colab , that is the code to predict the is a runtime error here is the error below
runtimeeeror: the size of tensor a(197) must match the size of tensor b(257) at non singleton dimension 1
clearly explained vit! Thanks!
Glad it was helpful!
Ma'am how we can make novelty in this Transformer architecture? For my PhD research. Thanks.
Thanks for your video. Does ViT work for non-square images? is it better to use the pretrained ViT for our specific task, right?
ViT (Vision Transformer) models are primarily designed to work with square images but ViT for non-square images is possible, but it requires some modifications to the architecture and preprocessing steps.
Regarding using pretrained ViT models for specific tasks, it can be a good starting point in many cases, especially if you have a limited amount of task-specific data.
very nice video but you did not explain what "going_modular.going_modular import engine" it is and where you got it from ??
Great video! Thanks
You're welcome!
Thanks for the great content! I was wondering if you could show a 70-20-10 split as it's a common approach in many projects to prevent overfitting and ensure robust model evaluation. Would be great to see that in action!
Sure
@@CodeWithAarohi mam i downloaded the going_modular but still geeting the going_modular error. can you please guide us how to use this going_modular properly after downoading
Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn
@CodeWithAarohi can you help with this error?
Hi, thank you so much for this tutorial. Where can I find the flowers dataset from?
Get it from roboflow universe
your teaching are so awesome mam.
Thanks a lot
nice content... appreciate this.
Glad you liked it!
Amazing video
Glad you think so!
How to give residual connection in transformer encoder as shown in block
Thank you for the lovely tutorial and explanation!
Can you do a tutorial on multiple outputs for a singular image?
Many immense thanks in advance!
I will try!
Thank you so much for such amazing content. I tried converting this model to onnx but I am getting "UnsupportedOperatorError: Exporting the operator 'aten::_native_multi_head_attention' to ONNX opset version 11 is not supported." this error. I tried alll the opset versions and different versions of pytorch as well. But still I am not able to solve this issue. It would be really great if you could help me with the issue. Thanks in advance
I have images, where there are multiple classes within the same image. Can ViT detect and draw bounding boxes around them as in Yolo?
Yes , You can use ViT for Object detection
Very well explained
Keep watching
hi ma'am, can i work with rectangular images? if yes what changes should i do? because i think if i pad images, the accuracy would go down
Yes, you can work with rectangular images in Vision Transformers (ViTs), but you're correct that padding may not be the best solution, especially if it introduces a lot of empty space.
You can resize your rectangular images to a square shape before inputting them into the ViT.
Or you can crop your rectangular images to a square shape, preserving the most important parts of the image.
Hello Aarohi,
Its a great vedio. The way you explained is very clear and perfect and i learned a lot from this video.
Can you also please make a vedios on transformer-based model for temporal action localization.
Thank you once again for such a great video...!!!
Yes, sure
Nice explanation mam but i am beginner of vits so i want customized the vit as per my need so what type parameters I need to chage in standard model specially for image classification
The original ViT paper used a fixed-size patch (e.g., 16x16 pixels), but you can experiment with different patch sizes based on your dataset and task. Larger patches may capture more global features but require more memory.
2- The number of Transformer blocks in your model. Deeper models may capture more complex features but also require more computational resources.
3- The dimensionality of the hidden representations in the Transformer. Larger hidden sizes may capture more information but also increase computational cost.
4- The number of parallel attention mechanisms in the Transformer block. Increasing the number of heads can help capture different aspects of relationships in the data.
YOu can make changes in learning rate, drop out, weight decay, batch size, Optimizer also.
I also have a question: Why class embeddings have been added as a row to patch embedding matrix which is of size 196x768. Should that not be added as a column, instead? Also there is an addition of position embedding. In that case two vectors (one for class embeddings and another for position embedding)? Please clarify.
In the Vision Transformer (ViT) architecture, class embeddings are indeed added as a row to the patch embedding matrix, rather than a column. This might seem counterintuitive at first, but it aligns with the way the self-attention mechanism in the transformer model operates. Let's break down why this is the case:
Patch Embeddings and Self-Attention:
In ViT, an image is divided into fixed-size patches, which are then linearly embedded to create patch embeddings. These embeddings are arranged in a matrix, where each row corresponds to a patch, and each column corresponds to a feature dimension. The transformer's self-attention mechanism operates on these embeddings, attending to various positions within the same set of embeddings.
Class Embeddings:
The class embedding represents the information about the overall image category or class. In a traditional transformer, the position embeddings capture the spatial information of the input sequence, and the model learns to differentiate between different positions based on these embeddings. However, in ViT, since the patches don't have a natural sequence order, we use a separate class embedding to convey the class information.
Concatenation with Class Embedding:
By adding the class embedding as a row to the patch embedding matrix, you're effectively concatenating the class information with each individual patch. This makes it possible for the self-attention mechanism to consider the class information while attending to different parts of the image.
Position Embeddings:
Position embeddings are indeed used in ViT to provide spatial information to the model. These embeddings help the self-attention mechanism understand the relative positions of different patches in the image. Both the class embeddings and position embeddings are added to the patch embeddings before being fed into the transformer encoder.
@@CodeWithAarohi Thanks Aarohi!
Thanks for a great tutorial. But I am facing an issue that when I change the image, it is displaying the newer image but the predicted class label and probability are not getting updated.
have u try re run the script from the beginning ?
Thank you for your videos. Along with accuracy, I wish know precision, recall and F1 score too. Could you please include precision, recall and F1 score metrics evaluation code.
Noted
Do you have code to calculate precision, recall, F1 score in vision transformer. Please reply
How would be the code with multiple layers?
mam, i have some problems at the level of the Going_modular library. I try installing it using pip but is not given
going_modular is a folder in my github repo. You need to paste it in your current working directory.
Very nice .
Thanks a lot
Awesome tutorial
Can I use this code with resize image of 96x96
i need this project noow , can you give me the link of the dataset
Hello mam
Vision transformer only has an encoder and no decoder. So when using vit in image captioning which part of this architecture create captions for the input image?
ViT is only for image classification, if you want to use vit architecture in image captioning, you need quite different model form. find google scholar and find the modified model for image captioning
thank you for your video , can you please explain for image classification in vision transformer without using pytorch in a pretrained model?
Will try.
hello,
In forward() function of class MultiheadSelfAttentionBlock() if I am not wrong query, key and value should be query=Wq*x , key=Wk*x and value=Wv*x where Wq , Wk, Wv learnable parameter matrix.
Dear maam when I tried to run this code on my computer in jupyter notebook I come across an error saying at training part the libarary called going modular doesn't exist could you please tell me how to solve this issue?
You have to download the going_modular folder from my github repo and paste it in your working directory. github.com/AarohiSingla/Image-Classification-Using-Vision-transformer
what is the image format which u have used for this code...i am getting error on tiff file format..
I have used jpg format.
Hello Aarohi, i am getting the following error " No module named 'going_modular' " for from going_modular.going_modular import engine while executing the code in jupyter notebook in anaconda navigator . is there any solution for this ?
You can download that from github.com/AarohiSingla/Image-Classification-Using-Vision-transformer
@@CodeWithAarohi Hello mam, first of all great video and amazing explanation of ViT. going_modular package is not compatible with my python version. I tried all other option to install it from git, using pip install but still problem persist. Plz help... i am beginner in ViT rest of the code works perfect.
I am running code in Jupyter Notebook with Python 3.12.2
Hello Aarohi, thank you for this great video. But I had going_modular error, and helper_functions error. I know my colab version is different from yours, I even try to change to the version you showed in the video, it still reported the same problem saying cannot find the model. I try to install the 2 libraries, but still had the errors. Any suggestions?
Thank you.
Copy the going_modular folder and helper.py file from this link and paste it in the directory where your jupyter notebook is: github.com/AarohiSingla/Image-Classification-Using-Vision-transformer
Great video ma'am! Actually I am working on video classification problem. Could you make video on how can we implement video vision Transformer?
I will try to cover the topic.
Thanks mam i saw the going_modular folder
ok
Make speical video on how to improve accuracy and avoid overfitting with solution example for VIT.. thses are most common problem for all i guess..
Sure!
thank you so much
Welcome 😊
please tell me where i can get this dataset
universe.roboflow.com/enrico-garaiman/flowers-y6mda/dataset/7
Hello Singra, Can I use the folder going_modular in Google Colab?
yes
@CodeWithAarohi how can we use the going_modular in google colab i tried but i don t know how
@tajikhaoula8068 copy going_modular folder in your google drive and then import it
@@CodeWithAarohi hello maam it didn't worked for me maybe im missing some steps could you please make a video on how to import it in Jupiter or google colab.
Hello aarohi,
I was trying your code but had an issue with "from going_modular.going_modular import engine" this. Kindly help
I tried installing the going_modular module, but unable to do it.
Going_modular is a folder present in my repo. You need to download it and put it in your current working directory.
@@CodeWithAarohi very nice video but you did not explain what "going_modular.going_modular import engine" it is and where you got it from ??
Wonderful tutorial! Could I know when I can find the custom dataset you used in this video? Thanks!
You can get it from here: universe.roboflow.com/search?q=flower%20classification
Thank you!@@CodeWithAarohi
Mam , where can i find the dataset, its not in the repo
You can download it from roboflow100
what is the minimum system requirement for run this model ?
There isn't a strict minimum requirement for running Vision Transformers.
But just to give you an idea- Use a CUDA-enabled GPU (e.g., NVIDIA GeForce GTX/RTX), at least 16GB of RAM (32GB recommended for larger models)
you did not provide the dataset of flowers you used in this video what if i want to replicate your result from where i can get this dataset?
universe.roboflow.com/enrico-garaiman/flowers-y6mda/dataset/7
Dear mam, thank you so much for your beneficial videos. I have one doubt mam by changing the class variables can we implement compact convolution transformer and convolution vision transformer. If possible can you please post videos on implementation of compact convolution and convolution vision transfomer code for plant disease detection
I will try after finishing my pipelined work.
Mam i am getting error when importing the going_modular. Its saying module not found ,, mam how to fix that
You have to copy this going_modular folder in your current working directory. This folder is available here: github.com/AarohiSingla/Image-Classification-Using-Vision-transformer
Thank you so much for your efforts. Please, could you make a video about vision transformer using Keras?
I will try
Thank you so much, we are waiting your brilliant video@@CodeWithAarohi
Amazing! Could you do an example using Tensorflow? :)
I will try!
Your explanation is very good. Thank you very much .How to install going_modular? please answer
going_modular is a folder in github repo. You need to download that.
github.com/AarohiSingla/Image-Classification-Using-Vision-transformer
@@CodeWithAarohi when can we put it because i am using google colan and i didn t know how to put it , i already clone the Github project , please try to help me ?
Thank you for an informative code walk-through. Could you please provide the data used in this code in your Github page?
I took this dataset from roboflow
Great explanation madam, can use please show us how to print confusion matrix and classification report (like precision and F1 SCORE) for vision transformers ON IMAGE CLASSIFICATION
Sure
Yes, Do you have code to calculate precision, recall, F1 score?
Nice Content. But after 10 epochs, Training Loss and Test Loss are shown as "Nan". How can I fix that ?
This can happen for various reasons, and here are some steps you can take to diagnose and potentially fix the issue:
Smaller batch sizes can sometimes lead to numerical instability. Try increasing the batch size to see if it has an impact on the problem.
Implement gradient clipping to limit the magnitude of gradients during training. This can prevent exploding gradients, which can lead to "NaN" values in the loss.
The learning rate used in your optimization algorithm might be too high, causing the model's weights to diverge during training. Try reducing the learning rate and experiment with different values to find the appropriate one for your model.
Regularization techniques like L1 or L2 regularization can help stabilize training. Consider adding regularization to your model to prevent overfitting.
Hello Aarohi,
Thank you for making such wonderful videos on ViT. Very well explained.
I guess you could have added something else for position embedding. Because torch.rand will always create random numbers because of that model will every time get a new position for patches and that will mislead. I guess so. you can correct me if i am wrong.
Please keep making more videos on Computer Vision and Transformer models for visions such as Swin, graph vision etc.
Also please bring videos on segmentation as well. I really waiting for videos on Hypercorrelation squeeze network(HSnet), 4D convolution, swin4D, Cost aggregation with Transformer such as CAT model, and lot more
Thank you once again for helping vision community.
Thank you..!
Hi, I used torch.rand because this is just the first video on vision transformer and I want to start from the very basic. But thankyou for your suggestion. I really appreciate it. Also I will try to cover the requested topics.
@@CodeWithAarohi Thank you..!
Can we add top layer to create bounding box?
Yes
@@CodeWithAarohi can you share the link
Hello mam, thank you so much for your videos.
Can you please post a video on object detection from scratch using compact convolution and compact vision transformer.
Thanks in advance
Will try
HI, I am getting ModuleNotFoundError: No module named 'going_modular' error. Is there any solution for this? I am running the code in colab. Thanks in advance.
Please check the repo, this folder is already there.
@@CodeWithAarohi Thank you!
@@MonishaRaja hi can you please tell me how did you run it in colab
Can I apply the same code for spectrogram Images for Alzheimer'S disease?
Never tried it. but, I think you can use.
@@CodeWithAarohi can I conntact you I need your help?
@@CodeWithAarohi did the images should have special dimanation?
from going_modular.going_modular import engine, what is this? it is showing error in google colab. how to overcome this error? kindly help.thank you ma'am.
going_modular is a fodler in my github repo. Place this folder in your google drive and then run your colab
ok ma'am let me try.. thank you@@CodeWithAarohi
@@CodeWithAarohi mam still its not working. can you please help?
Thank you for wonderful video can you we load data from google drive
Yes you can
@@CodeWithAarohi how can give me access to your google drive
wonderful video it would be better if you zoom the code while teaching
Ok next time
I am facing a problem from here onwards madam # Setup the optimizer to optimize our ViT model parameters using hyperparameters from the ViT paper
from going_modular.going_modular import engine
what is the error?
Download going_modular from github.com/AarohiSingla/Image-Classification-Using-Vision-transformer
I will try
Maximum your videos are tensorflow or keras but now you used pytorch
May be you said your torch version is 1.12.1 some thing, my torch version is 1.9.0, and torch.summary also not working madam
Next videos please do it in tensorflow or keras, and do any image datasets not cifar10 or mnist datasets madam
Mam can you pls do a video on how vision transformers are used for image captioning
I will try!
Ok mam
Vision transformer can only extract features from the image right, so for creating captions do we have to use a decoder?
@@liyaaelizabeththomas8818 Yes, to create captions from features extracted, a separate decoder is typically used.
Thank you mam
So image captioning using vit and Deep Learning methods both uses an encoder decoder architecture. So which method is better? Does vit have any advantage over deep learning models
Where is the link to the datasets used?
public.roboflow.com/classification/flowers_classification/3
Code with Aarohi is Best UA-cam channel for Artificial Intelligence #CodeWithAarohi
What is the difference between CNN and vit. Describe the sceniro in which they used.you are producing best video s.lots of love and respect from Lahore Pakistan
Thank you for your appreciation. CNNs (Convolutional Neural Networks) operate on local features hierarchically, extracting patterns through convolutional layers, while ViTs (Vision Transformers) process global image structure using self-attention mechanisms, treating image patches as tokens similar to text processing in transformers.
@@CodeWithAarohi thanks for your kind reply. Love from Lahore Pakistan
mam plx provide the pdfs with ur captions as well ..
can u pls implement vit for segmentation? thanks in advance
I never did that but will surely try.
going_modular : unable to install this package can you tell me how your were able to install this package:
going_modular
You can download the going_modular folder from github.com/AarohiSingla/Image-Classification-Using-Vision-transformer
@@CodeWithAarohi you make a video of how to install the going modular im fresher to it.
getting Error of unable to render code block on GitHub link, kindly solve it, it will be helpful in understanding concepts
Post full error message.
Can we implement instance segmentation using ViTs ?
Did you get solution for this ?
@@mehwish60 Not instance but you can do semantic segmentation using segformer from huggingface (model name is mit-b0)
another thing you can zoom in to bigger size during video we can not see
Training the model is taking way to much time.
Even in google colab it says the RAM resource is exhausted.
can you take same for the video classification using transformer
I will try.
Thank you for wonderful video can you give me the dataset link in this project.
I took this dataset from roboflow 100
@@CodeWithAarohiok ma'am
@@CodeWithAarohi The video was really good ma'am, can you give the link of the dataset. I searched but couldn't find it.
Hey Aarohi, great video. The github link shows invalid notebook, would be glad if you fixed it asap!
github.com/AarohiSingla/Image-Classification-Using-Vision-transformer
@@CodeWithAarohi Thanks!
@@CodeWithAarohi Hey idk why, but it still says this : Invalid Notebook missing attachment: image.png
why do we do: x = self.classifier(x[:, 0])?
To reduce the output sequence from the transformer encoder to a single token representation by selecting the first token and passing it through a classifier.
@@CodeWithAarohi Can we not combine all the tokens together into one with cat + lin or sum? Intuitively, they all contain contextual information, so would that be a bad idea?
need dataset
How we can make a hybrid model to bulid custom model of ViT. Need your email
aarohisingla1987@gmail.com