Really enjoyed the video but had a couple of doubts. 1.) Dont you need to preprocess the data to remove all the stop words 2.) if not does the stop words add some intrensic value to the structure of the sentence that would help building the model. 3.) Similarly for slangs, emojis etc etc.
As per the previous video, I get no training data: Traceback (most recent call last): File "imdb-lstm.py", line 26, in (X_train, y_train), (X_test, y_test) = imdb.load_imdb() File "C:\Users\su_matthewbennett\wandb\ml-class\videos\lstm-classifier\imdb.py", line 8, in load_imdb X_train.extend([open(path + f).read() for f in os.listdir(path) if f.endswith('.txt')]) FileNotFoundError: [WinError 3] The system cannot find the path specified: './aclImdb/train/pos/' Am I missing something here?
You're not missing anything! Thanks for bringing these issues to our attention. They are corrected in the most recent commits on the repo. One thing: I haven't tested all of the data downloading code on Windows, and that kind of code can hit subtle bugs cross-platform. Let us know if you see any issues and I'll get right on it!
Hi there, An amazing video. I have been working for some time with text data and I must confess that it is great effort. about code, I am getting an error when I try to build hybrid network i.e LSTM+CNN TypeError: The added layer must be an instance of class Layer. Found: Any ideas ? Regards



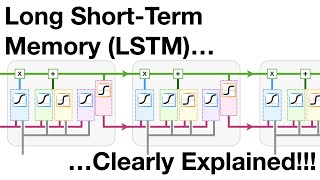






I want to say thank you for your presentation next Sir if you show how hybrid CNN-LSTM work more deeply its better
Really enjoyed the video but had a couple of doubts.
1.) Dont you need to preprocess the data to remove all the stop words
2.) if not does the stop words add some intrensic value to the structure of the sentence that would help building the model.
3.) Similarly for slangs, emojis etc etc.
As per the previous video, I get no training data:
Traceback (most recent call last):
File "imdb-lstm.py", line 26, in
(X_train, y_train), (X_test, y_test) = imdb.load_imdb()
File "C:\Users\su_matthewbennett\wandb\ml-class\videos\lstm-classifier\imdb.py", line 8, in load_imdb
X_train.extend([open(path + f).read() for f in os.listdir(path) if f.endswith('.txt')])
FileNotFoundError: [WinError 3] The system cannot find the path specified: './aclImdb/train/pos/'
Am I missing something here?
You're not missing anything! Thanks for bringing these issues to our attention. They are corrected in the most recent commits on the repo.
One thing: I haven't tested all of the data downloading code on Windows, and that kind of code can hit subtle bugs cross-platform. Let us know if you see any issues and I'll get right on it!
Is deep LSTM better than vanilla lstm?
Hi there,
An amazing video. I have been working for some time with text data and I must confess that it is great effort.
about code, I am getting an error when I try to build hybrid network i.e LSTM+CNN
TypeError: The added layer must be an instance of class Layer. Found:
Any ideas ?
Regards
This issue is fixed I guess.