References: Taming Transformers for High-Resolution Image Synthesis, Esser et al., 2020 ►Project link with paper and results: compvis.github.io/taming-transformers/ ►Code: github.com/CompVis/taming-transformers ►Colab demo to start sampling right away: colab.research.google.com/github/CompVis/taming-transformers/blob/master/scripts/taming-transformers.ipynb
I prefer to use Transforms to make neural nets. The fast Hadamard transform can be viewed as fixed collection of dot products. Then you can swap around what is adjusted in a net using the fixed dot products and adjustable (parametric) activation functions like fi(x)=ai.x x=0, i=0 to m. The advantage is the number of operations per layer falls to log2(n) add subtracts and n multiplies. And the number of parameters to 2n where n is the width of the net. How can that work? Each dot product is a statistical summary measure and filter looking back at the entire prior layer of neurons and capable of modulating its response to whatever it sees. And that works fine. Fast Transform fixed filter bank neural networks.
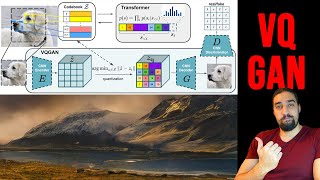
bro, I really don't understand what the function of the transformer is in this architecture. Is it only because of the fact that it can be used to predict information that is missing from the images by having learned the distribution of the latent space from others during training?
Exactly! It helps to 'control' the latent space using a "codebook". In fact, since a high-resolution image is too big to be directly used in the transformer architecture, they need to attack this problem with another angle. In this case, they encode the information using CNNs and save these encoded parameters in a codebook instead of the pixels themselves. t These encodings will be used in the transformer to change the style of the image. Mainly to help control the overall image realism while the CNN encodings ensure the local realism.









References:
Taming Transformers for High-Resolution Image Synthesis, Esser et al., 2020
►Project link with paper and results: compvis.github.io/taming-transformers/
►Code: github.com/CompVis/taming-transformers
►Colab demo to start sampling right away: colab.research.google.com/github/CompVis/taming-transformers/blob/master/scripts/taming-transformers.ipynb
Wow Really Neat 😁
Thanks you for all this work
Thank you so much ! It is a pleasure to make these videos! :)
Perfect !
Thank you for these insights !
It is my pleasure!
I prefer to use Transforms to make neural nets. The fast Hadamard transform can be viewed as fixed collection of dot products. Then you can swap around what is adjusted in a net using the fixed dot products and adjustable (parametric) activation functions like fi(x)=ai.x x=0, i=0 to m.
The advantage is the number of operations per layer falls to log2(n) add subtracts and n multiplies. And the number of parameters to 2n where n is the width of the net. How can that work? Each dot product is a statistical summary measure and filter looking back at the entire prior layer of neurons and capable of modulating its response to whatever it sees. And that works fine. Fast Transform fixed filter bank neural networks.
Great breakdown!
Thank you!
Have YOU downloaded the dataset ?
bro, I really don't understand what the function of the transformer is in this architecture. Is it only because of the fact that it can be used to predict information that is missing from the images by having learned the distribution of the latent space from others during training?
Exactly! It helps to 'control' the latent space using a "codebook". In fact, since a high-resolution image is too big to be directly used in the transformer architecture, they need to attack this problem with another angle. In this case, they encode the information using CNNs and save these encoded parameters in a codebook instead of the pixels themselves. t
These encodings will be used in the transformer to change the style of the image. Mainly to help control the overall image realism while the CNN encodings ensure the local realism.
@@WhatsAI
Can YOU please make a video regarding the code also
I mean Transformers architecture on CNN by code