Hi good point. Certainly delta live table simplify the code and the developer experience in a more declarative way. This is a decision engineer need to make. DLT cost is a bit higher and some prefer to code more declarative. I would say that the simpler the transformation and more "cookie cutter" I would go for DLT otherwise better to have CDF.
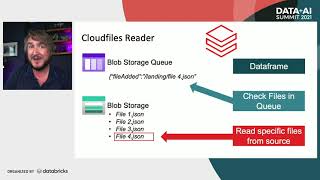
This video is incredibly informative, thank you for sharing it. I have a query about the handling of folders and sub-folders. Can data be ingested taking into consideration the folder structure in my source? My scenario is fairly straightforward: I have a blob store containing both folders and sub-folders, and I aim to retrieve these files to create delta tables directly in my gold layer. Autoloader seems like a viable solution, but I'm uncertain how to effectively manage the folder and sub-folder configuration to access these files. Any advice would be greatly appreciated. Thank you.
Hi Thanks for the comment. You can query the folders hierarchy using patterns and autoloader will watch any new files arriving on that top folder. You can check this on the Databricks docs docs.databricks.com/en/ingestion/auto-loader/patterns.html

![Pyspark for SQL developers the most common code examples [Python]](http://i.ytimg.com/vi/lYYIFRaY8Tk/mqdefault.jpg)
![Pyspark for SQL developers the most common code examples [Python]](/img/tr.png)






Thanks for the video. Would delta live tables , with streaming table , be better for this?
Hi good point. Certainly delta live table simplify the code and the developer experience in a more declarative way. This is a decision engineer need to make. DLT cost is a bit higher and some prefer to code more declarative. I would say that the simpler the transformation and more "cookie cutter" I would go for DLT otherwise better to have CDF.
This video is incredibly informative, thank you for sharing it. I have a query about the handling of folders and sub-folders. Can data be ingested taking into consideration the folder structure in my source? My scenario is fairly straightforward: I have a blob store containing both folders and sub-folders, and I aim to retrieve these files to create delta tables directly in my gold layer. Autoloader seems like a viable solution, but I'm uncertain how to effectively manage the folder and sub-folder configuration to access these files. Any advice would be greatly appreciated. Thank you.
Hi Thanks for the comment. You can query the folders hierarchy using patterns and autoloader will watch any new files arriving on that top folder. You can check this on the Databricks docs docs.databricks.com/en/ingestion/auto-loader/patterns.html