Pipelines are separated by blocking operations, while stages are separated by shuffles (in most cases). A stage can have multiple pipelines. For example: the stage with hash aggregate will have multiple pipelines because hash aggregate is a blocking op, if its just a partial hashagg since that does not need a shuffle, all operations would be in a single stage. Hope that helps









Excellent session, very well explained
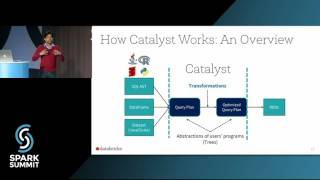
what is the difference between a normal stage in job and a WSCG . Do multiple pipelines within a single WSCG correspond to two separate stages
according to my understanding the stages are separated only if there is a blocking op which requires aggregations ,,
Pipelines are separated by blocking operations, while stages are separated by shuffles (in most cases). A stage can have multiple pipelines. For example: the stage with hash aggregate will have multiple pipelines because hash aggregate is a blocking op, if its just a partial hashagg since that does not need a shuffle, all operations would be in a single stage. Hope that helps