What is a posterior predictive check and why is it useful?

Вставка
- Опубліковано 9 лип 2024
- This video explains what is meant by a posterior predictive check and why this is a vital part of model development in the Bayesian framework.
This video is part of a lecture course which closely follows the material covered in the book, "A Student's Guide to Bayesian Statistics", published by Sage, which is available to order on Amazon here: www.amazon.co.uk/Students-Gui...
For more information on all things Bayesian, have a look at: ben-lambert.com/bayesian/. The playlist for the lecture course is here: • A Student's Guide to B...


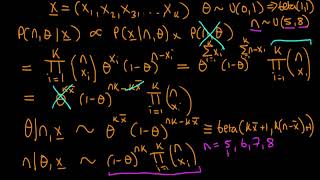






Niels Burghoorn pointed out a mistake here (thanks Niels!) at about 4 mins -- I say "Poisson prior", what I meant to say was "Poisson likelihood". Sorry for any confusion caused! Best, Ben
Just a brief question. Everyone is talking about "sampling" from the posterior. Isn’t it really more like "simulating a posterior"? How can you sample from something unknownˋ
can u please give us the data and codes from the video
Thanks a lot for this video. I've been trying to intuitively pin down posterior predictive distribution for a while now, and within the first two minutes, your explanation of it as an approximation of the posterior distribution on new data, along with the two-step iterative process, finally made it click.
Great video! Thank you
Thanks! That was a great explanation!!
i never heard this technique used in machine learning to decide if the posterior is good, anyone know why?
You are awsome awsome teacher!!
sir, u truly saved me😅
could you plz tell me where to find the Matlab codes which are used in these videos and ox-edu comprehensive bayesian stats list videos ?
Thank you very much for combining your book ("A Students Guide to Bayesian Statistics") with these lectures! 1) Perhaps I missed it, and perhaps it is a naive question, but how does this work in the context of a data generating process that produces a "thinner" distribution than the actual data? 2) Could one conceivably "p-hack" this form of the statistic (e.g., generate a small number of PPC distributions, or use a random seed that is more "favorable" to a desired hypotheses)? I'm just trying to figure out some of the pros and cons of the "Bayesian p-value", considering the headache it has caused in Frequentist statistics. But perhaps the point was to use the Bayesian p-value as an example of a kind of PPC?