No, probably not! Indeed, 100% accuracy of a model is only possible if you have training data where the annotators are 100% consistent, which is usually not the case for any interesting data. However, in settings where you don't have a lot of training data, topic models can help you figure out what the labels should be and can sometimes be a useful feature when you do build a classifier: mimno.infosci.cornell.edu/papers/baumer-jasist-2017.pdf
Is your equation @ 3:10 (bottom of slide) right ? you want to integrate against the posterior density of \theta_d which by conjugacy should be \theta_d^{\alpha_i + n_{d,i}} , and now you want to to multiply the probability of seeing the words conditioned on a particular probability of topic assignment which should be \theta_d^{ n_{d,i}}.
I think it's right (famous last words). Is your question where the \alpha_i-1 is coming from? The \alpha_i-1 comes from the definition of the Dirichlet. This is also why alpha=1 leads to a uniform prior.
8:40 what happens if the word "trade" is repeated many times in a given document? Do you assume that you don't know the topic of the current word "trade" while assuming the topics of all the other word "trade" are correct?
1) Yes, that's right. You assume that you don't know the topic of that specific "trade". But the other "trades" still have an effect: it will be much more likely to be assigned to the same topic. 2) An earlier version of the comment asked if there were multiple senses of "trade" in a document ... would they all get the same topic? That's a great question and a large part of my research. Traditional topic models like LDA don't know how to distinguish them and don't know what a sense is. Here are some (complicated) models that do know the difference: users.umiacs.umd.edu/~jbg/docs/jbg-EMNLP07.pdf arxiv.org/abs/1002.4665
Thank you so much for this great video! I have one question: at the end of your explanation you say that we draw a random number between 0 and 1 and then find the first bin that is greater than this random number. But what happens if I draw a number so small that we will end up with a worse assignment of a topic for a particular word in a document than the original one? (E.g. if I got 0.005, a lot (if not all) of the topics would have greater probability than this number, despite the fact that some of these topics might be more probable than the others. However, according to the algorithm I have to choose the first one, which might be suboptimal). I am curious how in the end we end up with a better assignment than the initial one. Thank you!
Great question. While it may seem like what you described is a bad outcome (and it usually is), sometimes it's exactly what you want. The whole point of Gibbs sampling is to fully explore the posterior. By taking that one "wrong" move in the probability space, you then make other options more probable. Then you might (for instance) discover a new topic, or separate one topic into two. This is particularly important early on when the topics haven't quite fully congealed. This is also an example of how human intuition can sometimes lead you astray ... it's hard to average over tens or hundreds of thousands of events in your head!
Why the hell is this such a straightforward computer-sciency algorithm but always formulated with a billion complicated integrals when I search for it?
I know the integrals can be scary, but it is often the answer to the question "why is this straightforward algorithm like this". For algorithms that use probabilities, you need to consider all of the options and add them up. For discrete probability distributions, this means that you need to have a sum. For continuous probability distributions, this means you need to have an integral.
When the topics are assigned in the beginning you mentioned it is done randomly. What if "trade" receives a wrong assignment most of the times. Say it is assigned a topic 3 for 10 times but in reality it should be belonging to topic 1. Will the further assignments not get biased because of the wrong assignments in the beginning? What am I missing? Kindly help.
The topics can be swapped (this is called non-identifiable assignments). The initial assignments will be really bad, but all equally so. The words that appear together in documents will gradually gravitate toward each other and lead to good topics. You can see that in this toy example: users.umiacs.umd.edu/~jbg/teaching/CMSC_726/16b.pdf
It took me so long to wrap my head around this as well. The problem is in the sentence "Say it is assigned a topic 3 for 10 times but in reality it should be belonging to topic 1". Based on what would you judge whether a word would better belong to topic 1? There is no wrong assignment per se because what we get as topics in the end is not at all about the topic-concept based on human intuition. ;-) We can read the words of a topic and think "those words don't sound like they belong to the same topic" but it's actually about a representation of words that occur together not about their similarity. For example we could end up with topics like this: top1: bank bank cash transfer top2: water water bank river dog top3: cat animal leash paw You could think that bank from top2 should belong to the other bank-tokens in top1, but what if it's a river bank and occurs together with water a lot? You could think that dog should rather belong to top3 as it's about animal-themed words, but actually dog occurs together with the other words in documents, that's why it ends up there. The algorithm works because each word gets its topic assigned based on how probable the topic is for the word's document (i.e. to which topics the other words in the same doc are assigned) AND how probable the word is for the topic.
I tried to implement the algorithm based on the description for K=3 but I get into a state where there is a topic which is not assigned to any word. Is there some obvious flaw in what I might be doing wrong?
@@JordanBoydGraber Thank you very much for the reply, I hope the implementation is correct but the reason that makes me question that is because when I try direct sampling with Gibbs I get a clear indication that words get distributed among 3 topics, but in the case of the collapsed Gibbs implementation I get them assigned to only two. Just for sake of context my corpus is fairly simple X = [["a","a","a","a","a","a","a","b","b","b"]*10, ["a","a","a","a","a","b","b","c","c","c"]*10, ["c","c","c","c","d","d","d","e","e","e"]*10, ["d","d","d","d","d","e","e","e","e","e"]*10]
@@elionushi8037 If you want to be sure your sampler is working correctly, you probably want to *generate* your data from the LDA distribution (i.e., use the Dirichlet / Multinomial distributions from sklearn) and then see if you can recover the underlying topics. Humans are bad at creating topics by hand (I had to learn this mistake the hard way) even when you expect certain topics to emerge from your toy data.
i have a question. after run gibbs sampling, we have topic for each word in every document. But i want to find how distribution of word for each topic (Beta) and topic for each document (Theta). what should i do ?
I think all of recipe relate with graphical distribution. Why do you use Gibbs to evaluate for topics for each word (Z) but not for distribution of word for each topic (Beta) and topic for each document (Theta) ?. about Bete và Theta, why just use MAP to evaluated ?. i also referd to this file: pdfs.semanticscholar.org/a166/d65a5d5a2905b038288e59c4fd98864c6f44.pdf. My purpose is understand recipe in total. please help my if you can.
If it is, it's unintentional. I haven't watched their material. I guess my green screen setup is similar to Emily's, though (I've only seen her tweet when they were setting it up).




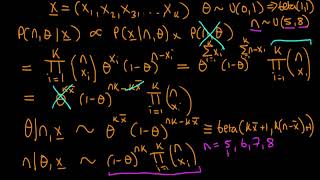





Omg, thank you. I've been reading this topic (pun not intended) for 2 years and this is the first time I've developed some intuition.
I need to do Google reviews classification into n categories and will this model give me 💯 accurate results..i am worried about the accuracy 😮
No, probably not! Indeed, 100% accuracy of a model is only possible if you have training data where the annotators are 100% consistent, which is usually not the case for any interesting data.
However, in settings where you don't have a lot of training data, topic models can help you figure out what the labels should be and can sometimes be a useful feature when you do build a classifier:
mimno.infosci.cornell.edu/papers/baumer-jasist-2017.pdf
The fact that this guy doesn't blink even once throughout the whole video reveals that he is actually an artificial intelligence.
This is nonsense! I blink exactly every 9.3 seconds, which is consistent with bipedal Earth mammals.
Is your equation @ 3:10 (bottom of slide) right ? you want to integrate against the posterior density of \theta_d which by conjugacy should be \theta_d^{\alpha_i + n_{d,i}} , and now you want to to multiply the probability of seeing the words conditioned on a particular probability of topic assignment which should be \theta_d^{ n_{d,i}}.
I think it's right (famous last words). Is your question where the \alpha_i-1 is coming from? The \alpha_i-1 comes from the definition of the Dirichlet. This is also why alpha=1 leads to a uniform prior.
does the formula in estimating theta and beta matrix for every topic modeling (i.e STM, CTM, LSA) is the same with LDA?
If you're doing Gibbs Sampling, yes. Sadly, not all of those models work with Gibbs sampling.
8:40 what happens if the word "trade" is repeated many times in a given document? Do you assume that you don't know the topic of the current word "trade" while assuming the topics of all the other word "trade" are correct?
1) Yes, that's right. You assume that you don't know the topic of that specific "trade". But the other "trades" still have an effect: it will be much more likely to be assigned to the same topic.
2) An earlier version of the comment asked if there were multiple senses of "trade" in a document ... would they all get the same topic? That's a great question and a large part of my research. Traditional topic models like LDA don't know how to distinguish them and don't know what a sense is. Here are some (complicated) models that do know the difference:
users.umiacs.umd.edu/~jbg/docs/jbg-EMNLP07.pdf
arxiv.org/abs/1002.4665
Thank you so much for this great video! I have one question: at the end of your explanation you say that we draw a random number between 0 and 1 and then find the first bin that is greater than this random number. But what happens if I draw a number so small that we will end up with a worse assignment of a topic for a particular word in a document than the original one? (E.g. if I got 0.005, a lot (if not all) of the topics would have greater probability than this number, despite the fact that some of these topics might be more probable than the others. However, according to the algorithm I have to choose the first one, which might be suboptimal). I am curious how in the end we end up with a better assignment than the initial one. Thank you!
Great question. While it may seem like what you described is a bad outcome (and it usually is), sometimes it's exactly what you want. The whole point of Gibbs sampling is to fully explore the posterior. By taking that one "wrong" move in the probability space, you then make other options more probable. Then you might (for instance) discover a new topic, or separate one topic into two. This is particularly important early on when the topics haven't quite fully congealed.
This is also an example of how human intuition can sometimes lead you astray ... it's hard to average over tens or hundreds of thousands of events in your head!
Why the hell is this such a straightforward computer-sciency algorithm but always formulated with a billion complicated integrals when I search for it?
I know the integrals can be scary, but it is often the answer to the question "why is this straightforward algorithm like this". For algorithms that use probabilities, you need to consider all of the options and add them up. For discrete probability distributions, this means that you need to have a sum. For continuous probability distributions, this means you need to have an integral.
When the topics are assigned in the beginning you mentioned it is done randomly. What if "trade" receives a wrong assignment most of the times. Say it is assigned a topic 3 for 10 times but in reality it should be belonging to topic 1. Will the further assignments not get biased because of the wrong assignments in the beginning? What am I missing? Kindly help.
The topics can be swapped (this is called non-identifiable assignments). The initial assignments will be really bad, but all equally so. The words that appear together in documents will gradually gravitate toward each other and lead to good topics. You can see that in this toy example:
users.umiacs.umd.edu/~jbg/teaching/CMSC_726/16b.pdf
It took me so long to wrap my head around this as well. The problem is in the sentence "Say it is assigned a topic 3 for 10 times but in reality it should be belonging to topic 1". Based on what would you judge whether a word would better belong to topic 1?
There is no wrong assignment per se because what we get as topics in the end is not at all about the topic-concept based on human intuition. ;-) We can read the words of a topic and think "those words don't sound like they belong to the same topic" but it's actually about a representation of words that occur together not about their similarity.
For example we could end up with topics like this:
top1: bank bank cash transfer
top2: water water bank river dog
top3: cat animal leash paw
You could think that bank from top2 should belong to the other bank-tokens in top1, but what if it's a river bank and occurs together with water a lot?
You could think that dog should rather belong to top3 as it's about animal-themed words, but actually dog occurs together with the other words in documents, that's why it ends up there.
The algorithm works because each word gets its topic assigned based on how probable the topic is for the word's document (i.e. to which topics the other words in the same doc are assigned) AND how probable the word is for the topic.
I tried to implement the algorithm based on the description for K=3 but I get into a state where there is a topic which is not assigned to any word. Is there some obvious flaw in what I might be doing wrong?
That can happen without there being a bug! It might just suggest that you have too many topics.
@@JordanBoydGraber Thank you very much for the reply, I hope the implementation is correct but the reason that makes me question that is because when I try direct sampling with Gibbs I get a clear indication that words get distributed among 3 topics, but in the case of the collapsed Gibbs implementation I get them assigned to only two. Just for sake of context my corpus is fairly simple X = [["a","a","a","a","a","a","a","b","b","b"]*10,
["a","a","a","a","a","b","b","c","c","c"]*10,
["c","c","c","c","d","d","d","e","e","e"]*10,
["d","d","d","d","d","e","e","e","e","e"]*10]
@@elionushi8037 If you want to be sure your sampler is working correctly, you probably want to *generate* your data from the LDA distribution (i.e., use the Dirichlet / Multinomial distributions from sklearn) and then see if you can recover the underlying topics. Humans are bad at creating topics by hand (I had to learn this mistake the hard way) even when you expect certain topics to emerge from your toy data.
Very clearly explained- thank you for this!
you are a great lecturer!
Thanks so much!
i have a question. after run gibbs sampling, we have topic for each word in every document. But i want to find how distribution of word for each topic (Beta) and topic for each document (Theta). what should i do ?
The MAP estimate for these is \hat \theta = \frac{n_{d,t} + \alpha_t}{n_{d, \cdot} + \sum \alpha}, etc.
@@JordanBoydGraber why this fomular has alpha_t in numerator and alpha in denominator ?
@@ggsgetafaf1167 Whoops, that's just laziness on my part. It should be consistent. :)
Hi thanks for the video. Is this not collapsed Gibbs sampling?
He has a paper on this and according to the paper it's the collapsed one.
Indeed, the integration over \theta and \beta make it "collapsed".
Excellent explanation, thank you!
I think all of recipe relate with graphical distribution. Why do you use Gibbs to evaluate for topics for each word (Z) but not for distribution of word for each topic (Beta) and topic for each document (Theta) ?. about Bete và Theta, why just use MAP to evaluated ?. i also referd to this file: pdfs.semanticscholar.org/a166/d65a5d5a2905b038288e59c4fd98864c6f44.pdf. My purpose is understand recipe in total. please help my if you can.
Excellent explanation
谢谢!
thank you, great example!
I stole it from David Mimno!
mimno.infosci.cornell.edu/
This is a copy of the coursera course "Machine Learning: Clustering & Retrieval"
If it is, it's unintentional. I haven't watched their material. I guess my green screen setup is similar to Emily's, though (I've only seen her tweet when they were setting it up).
very clear!
really excellent explanation