In the backward function of the dense class you're returning a matrix which uses the weight parameter of the class after updating it, surely you'd calculate this dE/dX value before updating the weights, and thus dY/dX?
This video, instead of the plethora of other videos on "hOw tO bUiLd A NeUrAl NeTwOrK fRoM sCraTcH", is the literal best. It deserves 84 M views, not 84 k views. It is straight to the point, no 10 minutes explanation of pretty curves with zero math, no 20 minutes introduction on how DL can change the world I truly mean it, it is a refreshing video.
@@independentcode Thank you for the reply! I am a researcher, and I wanted to create my own DL library, using yours as base, but expanding it for different optim algorithms, initializations, regularizations, losses etc (i am now just developing it on my own privately), but one day I'll love to post it on my github. How can I appropriately cite you?
I love the 3b1b style of animation and also the consistency with his notation, this allows people to learn the matter with multiple explanations while not losing track of the core ideas. Awesome work man
THANK YOU ! This is exactly the video I was looking for. I always struggled with making a neural network, but following your video, I made a model that I can generalize and it made me understandexactly the mistakes I made in my previous attempts. It's easy to find on youtube videos of people explaining singular neurons and backpropagation, but then quickly going over the hard part: how do you compute the error in an actual network, the structural implementation and how it all ties together. This approach with separating the Dense layer from the activation layer also makes things 100x clearer, and many people end up smacking them both in the same class carelessly. The visuals make the intuition for numpy also much much easier. It's always a thing I struggled with and this explained why we do every operation perfectly. even though I was only looking for one video, after seeing such quality, I HAVE to explore the rest of your channel ! Great job.
Thank you so much for taking the time to write this message! I went through the same struggle when I wanted to make my own neural networks, which is exactly why I ended up doing a video about it! I'm really happy to see that it serves as I intended :)
Thank you so very, very, very much for this video. I have been wanting to do Machine Learning, but without "Magic". It drives me nuts when all the tutorials say "From Scratch" and then proceed to open Tensor Flow. Seriously, THANK you!!!
Thanks for making such great quality videos. I'm working on my Ph.D., and I'm writing a lot of math regarding neural networks. Your nomenclature makes a lot of sense and has served me a lot. I'd love to read some of your publications if you have any.
jesus christ this is a good video and shows clear understanding. no "i've been using neural networks for ten years, so pay attention as i ramble aimlessly for an hour" involved
Man, I love you. How many times i tried too do the multilayer nn on my own, but always faced thousand of problems. But this video explained everything. Thank you
one of the best video i have ever seen. struggled alot to understand this and you have explained so beautifully you made me fall in love with the neural network which i was intimidating from. thank you so much.
Thank you very much for your videos explaining how to build ANN and CNN from scratch in Python: your explanations of the detailed calculations for forward and backward propagation and for the calculations in the kernel layers of the CNN are very clear, and seeing how you have managed to implrment them in only a few lines of code is very helpful in 1. understanding the calculations and processes, 2. demistifying the what is a black box in tensorflow / keras.
I think the last row's indices of the W^T matrix at 17:55 must be (w1i, w2i,...,wji). Still the best explannation i have ever seen btw, thank you so much. I dont know why this channel is still so underrated, looking forward to seeing your new videos in the future
I developed my first neural network in one night yesterday. that could not learn because of backward propagation, it was only going through std::vectors of std::vectors to get the output. I was setting weights to random values and tried to guess how to apply backward propagation from what i have heard about it. But it failed to do anything, kept guessing just as I did, giving wrong answers anyway. This video has a clean comprehensive explanation of the flow and architecture. I am really excited how simple and clean it is. I am gonna try again. Thank you.
I don't know about PhDs since I am not a PhD myself, but I never found any simple explanation of how to make such an implementation indeed, so I decided to make that video :)
@@independentcode I think you should keep going video seris and show how capable this type of abstraction. Implemnting easiliy almost every type of neural nets.
Thank you for the kind words. I did actually take that a step further, it's all on my GitHub here: github.com/OmarAflak/python-neural-networks I managed to make CNNs and even GANs from scratch! It supports any optimization method, but since it's all on CPU you get very quickly restricted by computation time. I really want to make series about it, but I'll have to figure out a nice way to explain it without being boring since it involves a lot of code.
Great video! At 17:45, last row of matrix W' (transpose of W), subscript got a bit messed up. w_1j, w_2j and w_ij should be w_1i, w_2i and w_ji, i.e., j rows and i columns.
In your code you compute the gradient step for each sample and update immediately. I think that this is called stochastic gradient descent. To implement full gradient descent where I update after all samples I added a counter in the Dense Layer class to count the samples. When the counter reached the training size I would average all the stored nudges for the bias and the weights. Unfortunately when I plot the error over epoch as a graph there are a lot of spikes (less spikes than when using your method) but still some spikes. My training data has (x,y) and tries to find (x+y).
I noticed that you are using a batch size of one. make a separate Gradiant variable and ApplyGradiants function for batch sizes > 1 Note 1: also change "+ bias" to "np.add(stuff, bias)" or "+ bias[:,None] Note 2: in backpropagation, sum up the biases on axis 0 (I'm pretty sure that the axis is 0) and divide both weights and biases by batch size
Can you (or someone else) please explain to me what note 1 means. Edit: As for note 2, I successfully implemented it (by summing on axis 1), so thanks for the tip.
in the case of mini batch / batch gradient descent, would the input to the first layer be a matrix of ( Number_of_Features * Data_Points ) ? in that case, do I need to compute the average of the gradients in back propogation in each layer?
This is one of the best videos to really understand the vectorized form of neural networks! Really appreciate the effort you've put into this. Just as a clarification, the video is considering only 1 data point and thereby performing SGD, so during the MSE calculation Y and Y* are in a way depicting multiple responses at the end for 1 data point only right? So for MSE it should not actually be using np.mean to sum them up?
amazing video. one thing we could do is to have layers calculate inputs automatically if possible. Like if I give Dense(2,8), then the next layer I dont need to give 8 as input since its obvious that it will be 8. Similar to how keras does this.
Thank you! If you mean to use the network once it has trained to predict values on other inputs, then yes of course. Simply run the forward loop with your input. You could actually make a predict() function that encapsulates that loop since it will be the same for any network.
Hey. Amazing video man. I just have one question about the mnist Convolutional file in your github. So you only trained your neural network to identify 2 out of 10 classes ie. 0 and 1 but if I were to extend it to all 10 classes with 100 cases each when I preprocess the data, would all the dimensions in your original network layer be the same? like the Reshape and Dense layers? Basically, I was wondering if there is a way I can use the convolutional layer that would account for all classes in the dataset.
Hey, thanks! Sure, all you have to do is make the last dense layer of the network output the number of classes you want to predict. For now it is 2 (0 and 1). Make it 10 to handle all classes, but also don't forget to add the other classes to the training data in the preprocess_data function.
@@independentcode really sorry. I have another question. in the preprocess function can i initialize an empty list and then use a for loop: for i in range(10): current = np.where(y==i)[0][:limit] and then on the next line i can write, indices = indices + current ?? im not exactly sure how np.hstack works, it seems that i need to actually have 10 different lists and apply hstack to them all at once. i apologize again for bombarding you.
also. do you offer tutoring? I think I might purchase your books on machine learning with python and implementing algorithms from scratch. the main issue i have aside from the math is array dimensions for scaling/fitting. its actually my only concern, for any method or function of sklearn and keras, i always get stuck on preprocessing because dimensions are not correct. if you have any resource you can refer me to id greatly appreciate that. or if you offer tutoring id be more than happy to schedule a session.
@@independentcode actually i got it. i tried exactly what i suggested initializing an empty list then appending every class of first100 observations and then applied hstack lol
This indeed is the better explanation of the math behind the neural networks I've found on the internet, could I please use your code on github in my final work for college?
Hi there, great video, super helpful, but at 19:21 line 17 the gradient is computed with the updated weights instead of the original weights which (I believe) caused some exploding/vanishing gradient problems for my test data (iris flower dataset). Fixing that solved all my problems. If I am wrong please let me know. Note: I used leaky RELU as activation function
Is there a practical reason why the activation functions are implemented as layers, rather than the other layers, such as Dense, taking the activation function as an argument & applying it internally?
Yes, for simplicity. If you apply the activation inside the layer, then that layer will also have to account for the activation during backward propagation. And the Dense layer is not the only layer that might use an activation, so will you implement it in every such layer? That's why it's a separate thing
@@independentcode That's a good point. Although i suppose you could implement the activation function handling for both forward and backwards propagation in the base Layer class, right? I'm asking this because I started working on a project where I build a Dense neural net to classify some data, but I decided I might as well build a little neural net library. Your video made me think about creating a better design. I first passed the architecture of the network as a list of layer_lengths to a DenseNeuralNet class. I prefer your design of making a base Layer class that will function as an abstract base class, and specifying separate layer objects, as it's more modular than my initial design.
Hi , Im trying to print the weights after every epoch but I'm not able to do so. Can u help whats going wrong with this approach ..I simply tried to use the forward method..during training, def predict(network, input,train=True): output = input for layer in network: if layer.__class__.__name__ =='Dense': output = layer.forward(output) list_.append(layer.weights) else : output = layer.forward(output) however i get the same corresponding weights all the time
I think you're getting the same value in the list because layer.weights is a reference. You need to copy it. So just do: list_.append(np.copy(layer.weights))
this is an amazing video which explains so perfectly how neural networks work. I appreciate and thank you for all the effort energy you put in this video and it is shame that your work did not receive enough views that it deserves. I believe you use manim to make animations like 3b1b, dont you?
when looking at the error and it's derivative wrt some y[i], intuitively I would expect that if I increased y[i] by 1 the error would increase by dE/dy[i], but if I do the calculations the change in the error is 1/n off from the derivative, does this make sense?



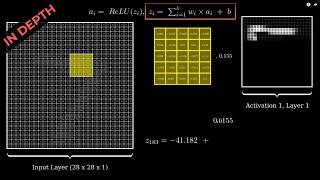






In the backward function of the dense class you're returning a matrix which uses the weight parameter of the class after updating it, surely you'd calculate this dE/dX value before updating the weights, and thus dY/dX?
Wow, you are totally right, my mistake! Thank you for noticing (and well catched!). I just updated the code and I'll add a comment on the video :)
I can't add text or some kind of cards on top of the video, so I pinned this comment in the hope that people will notice it!
@@independentcode Why can't you?
Did the youtube developers remove that awesome function too?
No wonder I've felt things have been off for so long!
Can you plz help me with this .. I want a chess ai to teach me what it learnt
ua-cam.com/video/O_NglYqPu4c/v-deo.html
just curious what happens if we propagate the updated weights backward like in the video? Will it not work? Or will it slowly converge?
This video, instead of the plethora of other videos on "hOw tO bUiLd A NeUrAl NeTwOrK fRoM sCraTcH", is the literal best. It deserves 84 M views, not 84 k views. It is straight to the point, no 10 minutes explanation of pretty curves with zero math, no 20 minutes introduction on how DL can change the world
I truly mean it, it is a refreshing video.
I appreciate the comment :)
@@independentcode Thank you for the reply! I am a researcher, and I wanted to create my own DL library, using yours as base, but expanding it for different optim algorithms, initializations, regularizations, losses etc (i am now just developing it on my own privately), but one day I'll love to post it on my github. How can I appropriately cite you?
That's a great project! You can mention my name and my GitHub profile: "Omar Aflak, github.com/omaraflak". Thank you!
I like how he said he wouldn’t explain how a neural network works, then proceeds to explain it
I love the 3b1b style of animation and also the consistency with his notation, this allows people to learn the matter with multiple explanations while not losing track of the core ideas. Awesome work man
Probably the best explaination of neural network of UA-cam ! The voice and the musique backside is realy soothing !
True
This might be the most intuitive explanation of the backpropagation algorithm on the Internet. Amazing!
This is an unbelievably clear and concise video. It answers all of the questions that linger after watching dozens of other videos. WELL DONE!!
The best tutorial on neural networks I've ever seen! Thanks, you have my subscription!
THANK YOU !
This is exactly the video I was looking for.
I always struggled with making a neural network, but following your video, I made a model that I can generalize and it made me understandexactly the mistakes I made in my previous attempts.
It's easy to find on youtube videos of people explaining singular neurons and backpropagation, but then quickly going over the hard part: how do you compute the error in an actual network, the structural implementation and how it all ties together.
This approach with separating the Dense layer from the activation layer also makes things 100x clearer, and many people end up smacking them both in the same class carelessly.
The visuals make the intuition for numpy also much much easier. It's always a thing I struggled with and this explained why we do every operation perfectly.
even though I was only looking for one video, after seeing such quality, I HAVE to explore the rest of your channel ! Great job.
Thank you so much for taking the time to write this message! I went through the same struggle when I wanted to make my own neural networks, which is exactly why I ended up doing a video about it! I'm really happy to see that it serves as I intended :)
Not only was the math presentation very clear, but the Python class abstraction was elegant.
Very clean and pedagogical explanation. Thanks a lot!
Thank you so very, very, very much for this video. I have been wanting to do Machine Learning, but without "Magic". It drives me nuts when all the tutorials say "From Scratch" and then proceed to open Tensor Flow. Seriously, THANK you!!!
I feel you :) Thank you for the comment, it makes me genuinely happy.
Best tutorial video about neural networks i've ever watched. You are doing such a great job 👏
Thanks for making such great quality videos. I'm working on my Ph.D., and I'm writing a lot of math regarding neural networks. Your nomenclature makes a lot of sense and has served me a lot. I'd love to read some of your publications if you have any.
This could be 3Blue1Brown for programmers! You got yourself a subscriber! Great video!
I'm very honored you called me that. I'll do my best, thank you !
+1
@@independentcode +1 sub
jesus christ this is a good video and shows clear understanding. no "i've been using neural networks for ten years, so pay attention as i ramble aimlessly for an hour" involved
this has to be the single best neural network explaining video I have ever watched
This video is the best on UA-cam for Neural Networks Implementation!
This is the best channel for learning deep learning!
This is basically ASMR for programmers
I almost agree, the only difference is that I can’t sleep thinking about it
@@nikozdevbruh I fall asleep and allow my self to hallucinate in math lol
I felt relaxed definetly :D
This was the best mathematical explanation on UA-cam. By far.
Man, I love you. How many times i tried too do the multilayer nn on my own, but always faced thousand of problems. But this video explained everything. Thank you
Absolutely astonishing quality sir. Literally on the 3b1b level. I hope this will help me pass the uni course. SUB!
This is a so high quality content. I have only basic knowledge of linear algebra and being a non-native speaker I could fully understand this
one of the best video i have ever seen.
struggled alot to understand this and you have explained so beautifully
you made me fall in love with the neural network which i was intimidating from.
thank you so much.
Thank you for your message, it genuinely makes me happy to know this :)
This video really saved me. From matrix representation to chain rule and visualisation, everything is clear now.
best video, very clear-cut. Finally I got the backpropagation and derivatives.
Thank you, that's the best video I have ever seen about neural networks!!!!! 😀
Amazing approach ! Very well explained. Thanks!
There are many solutions on the internet...but i must say this one is the best undoubtedly...👍 cheers man...pls keep posting more.
This is such an elegant and dynamic solution. Subbed!
Thank you very much for your videos explaining how to build ANN and CNN from scratch in Python: your explanations of the detailed calculations for forward and backward propagation and for the calculations in the kernel layers of the CNN are very clear, and seeing how you have managed to implrment them in only a few lines of code is very helpful in 1. understanding the calculations and processes, 2. demistifying the what is a black box in tensorflow / keras.
Such a great video. Really helped me to understand the basics.
This is literally a masterpiece
This is a very good approach to building neural nets from scratch.
I think the last row's indices of the W^T matrix at 17:55 must be (w1i, w2i,...,wji).
Still the best explannation i have ever seen btw, thank you so much. I dont know why this channel is still so underrated, looking forward to seeing your new videos in the future
Yeah I know, I messed it up. I've been too lazy to add a caption on that, but I really should. Thank you for the kind words :)
It is the best one I've seen among the explanation videos available on UA-cam!
Well done!
This is the best video i have seen so far ❤
Very well-done. I appreciate the effort you put into this video. Thank you.
actually,you saved my life, thanks for doing these
You are the only youtuber I sincierly want to return. We miss you!
Impressive, lot of information but remains very clear ! Good job on this one ;)
Thank you so much, my assignment was so unclear, this definitely helps!
I loved the background music. It gives peaceful mind. I hope, you will continue to make videos, very clear explanation
I developed my first neural network in one night yesterday. that could not learn because of backward propagation, it was only going through std::vectors of std::vectors to get the output. I was setting weights to random values and tried to guess how to apply backward propagation from what i have heard about it.
But it failed to do anything, kept guessing just as I did, giving wrong answers anyway.
This video has a clean comprehensive explanation of the flow and architecture. I am really excited how simple and clean it is.
I am gonna try again.
Thank you.
I did it ! Just now my creature learnt xor =D
Finally found the treasure. Please do more video bro. SUBSCRIBED
This is really dope. The best by far. Subscribed right away
Thank you for really great explanation!
Wish you will make even more 😉
your voice is calming and relaxing, sorry if that is weird
Haha thank you for sharing that :) Maybe I should have called the channel JazzMath .. :)
Only 4 video and you have avove 1k subs,
Please continue your work 🙏🏼
Whyyyy you don't have 3Million subscriptions you deserve it ♥️♥️
That was incredibly explained and illustrated. Thanks
Thank you! I'm glad you liked it :)
@@independentcode Most welcome!
Wonderful, informative, and excellent work. Thanks a zillion!!
you are the best 🥺❤️..wow.. finally i able to understand the basics thanks
I think most of the ML PhDs dont aware of this abstraction. Simply the best.
I don't know about PhDs since I am not a PhD myself, but I never found any simple explanation of how to make such an implementation indeed, so I decided to make that video :)
@@independentcode I think you should keep going video seris and show how capable this type of abstraction. Implemnting easiliy almost every type of neural nets.
Thank you for the kind words. I did actually take that a step further, it's all on my GitHub here: github.com/OmarAflak/python-neural-networks
I managed to make CNNs and even GANs from scratch! It supports any optimization method, but since it's all on CPU you get very quickly restricted by computation time. I really want to make series about it, but I'll have to figure out a nice way to explain it without being boring since it involves a lot of code.
@@independentcode GANs would be great also you could try to do RNNs too and maybe even some reinforcement learning stuff :D
This is so ASMR and well explained!
Content at it's peak
Great video! At 17:45, last row of matrix W' (transpose of W), subscript got a bit messed up. w_1j, w_2j and w_ij should be w_1i, w_2i and w_ji, i.e., j rows and i columns.
Big Fan of you from today !
Thank you! Well done! Absolutely wonderful video.
Amazing explanation!!
This video should be the first video you see when you search neural network.
This video is godsend, thank you.
That was helpful, thank you so much.
Very nice and clean video, keep it up
Dude this is amazing
after 1000 videos watched, i think i get it now, thanks
How output gradient is calculated and passed into the backward function?
In your code you compute the gradient step for each sample and update immediately. I think that this is called stochastic gradient descent.
To implement full gradient descent where I update after all samples I added a counter in the Dense Layer class to count the samples.
When the counter reached the training size I would average all the stored nudges for the bias and the weights.
Unfortunately when I plot the error over epoch as a graph there are a lot of spikes (less spikes than when using your method) but still some spikes.
My training data has (x,y) and tries to find (x+y).
Would you be able to share the code? This is where the part where I’m confused.
Keep it up .please make a deep learning and ml series for future.
I noticed that you are using a batch size of one. make a separate Gradiant variable and ApplyGradiants function for batch sizes > 1
Note 1: also change "+ bias" to "np.add(stuff, bias)" or "+ bias[:,None]
Note 2: in backpropagation, sum up the biases on axis 0 (I'm pretty sure that the axis is 0) and divide both weights and biases by batch size
Thanks for the tip on the biases.
Thanks for the tip on the biases. (1)
Can you (or someone else) please explain to me what note 1 means.
Edit: As for note 2, I successfully implemented it (by summing on axis 1), so thanks for the tip.
in the case of mini batch / batch gradient descent, would the input to the first layer be a matrix of ( Number_of_Features * Data_Points ) ? in that case, do I need to compute the average of the gradients in back propogation in each layer?
@@nahianshabab724 I guess yes, I saw that in multiple videos, just add a 1/m in the MSE formula.
Thanks you so much for your contribution in this field.
GOATED video
Clear, to the point. Thank you. Like (because there are just 722, and have to be a lot more)
I would like alot if u continue your channel bro
I love u , best ML video ever
Awesome man!!
This is one of the best videos to really understand the vectorized form of neural networks! Really appreciate the effort you've put into this.
Just as a clarification, the video is considering only 1 data point and thereby performing SGD, so during the MSE calculation Y and Y* are in a way depicting multiple responses at the end for 1 data point only right? So for MSE it should not actually be using np.mean to sum them up?
whiteout any doubt best explanation of NN ive ever seen - why you stop your productivity my friend ?
Amazing tutorial!
My brain is smoking i dont know what the hell is going on but that is kind of cool Keep it up
amazing video. one thing we could do is to have layers calculate inputs automatically if possible. Like if I give Dense(2,8), then the next layer I dont need to give 8 as input since its obvious that it will be 8. Similar to how keras does this.
Great stuff! I find it even better than the one from 3b1b. Can you think of any way the code can be checked with matrices outside the learning set?
Thank you!
If you mean to use the network once it has trained to predict values on other inputs, then yes of course. Simply run the forward loop with your input. You could actually make a predict() function that encapsulates that loop since it will be the same for any network.
Thank you so much for the video!!!
I followed the code exactly, and I still get Numpy shape errors.
Hey. Amazing video man. I just have one question about the mnist Convolutional file in your github. So you only trained your neural network to identify 2 out of 10 classes ie. 0 and 1 but if I were to extend it to all 10 classes with 100 cases each when I preprocess the data, would all the dimensions in your original network layer be the same? like the Reshape and Dense layers?
Basically, I was wondering if there is a way I can use the convolutional layer that would account for all classes in the dataset.
Hey, thanks! Sure, all you have to do is make the last dense layer of the network output the number of classes you want to predict. For now it is 2 (0 and 1). Make it 10 to handle all classes, but also don't forget to add the other classes to the training data in the preprocess_data function.
@@independentcode really sorry. I have another question. in the preprocess function can i initialize an empty list and then use a for loop:
for i in range(10): current = np.where(y==i)[0][:limit] and then on the next line i can write, indices = indices + current ?? im not exactly sure how np.hstack works, it seems that i need to actually have 10 different lists and apply hstack to them all at once. i apologize again for bombarding you.
also. do you offer tutoring? I think I might purchase your books on machine learning with python and implementing algorithms from scratch. the main issue i have aside from the math is array dimensions for scaling/fitting. its actually my only concern, for any method or function of sklearn and keras, i always get stuck on preprocessing because dimensions are not correct. if you have any resource you can refer me to id greatly appreciate that. or if you offer tutoring id be more than happy to schedule a session.
@@independentcode actually i got it. i tried exactly what i suggested initializing an empty list then appending every class of first100 observations and then applied hstack lol
Best tutorial💯💯💯💯
Thank you very very much for this video....
This indeed is the better explanation of the math behind the neural networks I've found on the internet, could I please use your code on github in my final work for college?
Thank you for the kind words! Other videos are coming up ;)
Yes of course, it is completely open source.
Amazing!!
Hi there, great video, super helpful, but at 19:21 line 17 the gradient is computed with the updated weights instead of the original weights which (I believe) caused some exploding/vanishing gradient problems for my test data (iris flower dataset). Fixing that solved all my problems. If I am wrong please let me know.
Note: I used leaky RELU as activation function
Hello, how did you fix this issue?
Is there a practical reason why the activation functions are implemented as layers, rather than the other layers, such as Dense, taking the activation function as an argument & applying it internally?
Yes, for simplicity. If you apply the activation inside the layer, then that layer will also have to account for the activation during backward propagation. And the Dense layer is not the only layer that might use an activation, so will you implement it in every such layer? That's why it's a separate thing
@@independentcode That's a good point. Although i suppose you could implement the activation function handling for both forward and backwards propagation in the base Layer class, right? I'm asking this because I started working on a project where I build a Dense neural net to classify some data, but I decided I might as well build a little neural net library. Your video made me think about creating a better design. I first passed the architecture of the network as a list of layer_lengths to a DenseNeuralNet class. I prefer your design of making a base Layer class that will function as an abstract base class, and specifying separate layer objects, as it's more modular than my initial design.
this is a great video thank you so much
how can we update this to include mini-batch gradient descent? Especially how will the equations change?
Hi , Im trying to print the weights after every epoch but I'm not able to do so. Can u help whats going wrong with this approach ..I simply tried to use the forward method..during training,
def predict(network, input,train=True):
output = input
for layer in network:
if layer.__class__.__name__ =='Dense':
output = layer.forward(output)
list_.append(layer.weights)
else :
output = layer.forward(output)
however i get the same corresponding weights all the time
I think you're getting the same value in the list because layer.weights is a reference. You need to copy it. So just do: list_.append(np.copy(layer.weights))
this is an amazing video which explains so perfectly how neural networks work. I appreciate and thank you for all the effort energy you put in this video and it is shame that your work did not receive enough views that it deserves. I believe you use manim to make animations like 3b1b, dont you?
Thanks a lot for the kind comment 😌 I'm glad if the video helped you in any way :) Yes it is indeed Manim!
sir please keep up with your videos I learn a lot
Yeah, this is awesome
In tensorflow they use weight matrix W dimensions i x j then take transpose in calculation.
when looking at the error and it's derivative wrt some y[i], intuitively I would expect that if I increased y[i] by 1 the error would increase by dE/dy[i], but if I do the calculations the change in the error is 1/n off from the derivative, does this make sense?
why do we use the dot product function for matrix multiplication? i thought that those did different things