I was always puzzled and fascinated about how those grid/block/threads work in parallel in the GPU and this video explains it in one and all. very impressive and helpful!
Great presentation!It is mentioned that 4 warps x 256 bytes per warp = 1024 bytes, and that equals to the Memory page size 1024 bytes. It only happens when the 4 warps running adjacent threads。Are the 4 warps always running adjacent threads?
@21:17 "Its exactly the right amount of data to hit the peak bandwidth of my mem system , Even if my program reads data from all over the place , each read is exactly ONE page of my memory " I didnt understand this statement 21:17 "Even if my program reads data from all over the place" Does it mean even if the data is read from non consecutive memory ??
@@perli216 "Even if my program reads data from all over the place" , I think I got it , Initially I thought "... all over the place" as in any random memory / non consecutive . all over the place as in diff threads from same page , because single thread will bring in the data from same page anyway.



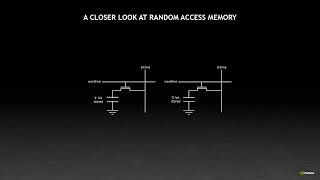






this is one of the clearest and most lucid presentations i have seen, on any topic
Fantastic presentation, wow!
Great presentation on GPU architecture, performance tradeoffs and considerations.
Dan is definitely the MAN.
Great talk!
I was always puzzled and fascinated about how those grid/block/threads work in parallel in the GPU and this video explains it in one and all. very impressive and helpful!
Man this is amazing
Another great presentation by Stephen Jones, fascinating
Great presentation!
thanks for detailed explanation. Really enjoyed it.
oh man I hope my mum fixed me with a better brain processing unit so I could understand this
Great presentation!It is mentioned that 4 warps x 256 bytes per warp = 1024 bytes, and that equals to the Memory page size 1024 bytes. It only happens when the 4 warps running adjacent threads。Are the 4 warps always running adjacent threads?
@@kimoohuang Not necessarily. Depends on the warp scheduler
Interesting!
@21:17 "Its exactly the right amount of data to hit the peak bandwidth of my mem system , Even if my program reads data from all over the place , each read is exactly ONE page of my memory " I didnt understand this statement 21:17 "Even if my program reads data from all over the place" Does it mean even if the data is read from non consecutive memory ??
yes
You got the benefits of reading contiguous memory for free basically, even when doing random reads
@@perli216 Ok cool so basically only mem is contigues we get advantage like if i = tid + bid*bsize , and not like i = 2*(tid + bid*bsize)
@@KalkiCharcha-hd5un I don't understand your question
@@perli216 "Even if my program reads data from all over the place" , I think I got it , Initially I thought "... all over the place" as in any random memory / non consecutive .
all over the place as in diff threads from same page , because single thread will bring in the data from same page anyway.
Looks like the link in the description is broken/truncated?
@@LetoTheSecond0 yes, yourube did this. It's just the original source for the video