Gradient Boost Part 3 (of 4): Classification

Вставка
- Опубліковано 16 чер 2024
- This is Part 3 in our series on Gradient Boost. At long last, we are showing how it can be used for classification. This video gives focuses on the main ideas behind this technique. The next video in this series will focus more on the math and how it works with the underlying algorithm.
This StatQuest assumes that you have already watched Part 1:
• Gradient Boost Part 1 ...
...and it also assumed that you understand Logistic Regression pretty well. Here are the links for...
A general overview of Logistic Regression: • StatQuest: Logistic Re...
how to interpret the coefficients: • Logistic Regression De...
and how to estimate the coefficients: • Logistic Regression De...
Lastly, if you want to learn more about using different probability thresholds for classification, check out the StatQuest on ROC and AUC: • THIS VIDEO HAS BEEN UP...
For a complete index of all the StatQuest videos, check out:
statquest.org/video-index/
This StatQuest is based on the following sources:
A 1999 manuscript by Jerome Friedman that introduced Stochastic Gradient Boost: statweb.stanford.edu/~jhf/ftp...
The Wikipedia article on Gradient Boosting: en.wikipedia.org/wiki/Gradien...
The scikit-learn implementation of Gradient Boosting: scikit-learn.org/stable/modul...
If you'd like to support StatQuest, please consider...
Buying The StatQuest Illustrated Guide to Machine Learning!!!
PDF - statquest.gumroad.com/l/wvtmc
Paperback - www.amazon.com/dp/B09ZCKR4H6
Kindle eBook - www.amazon.com/dp/B09ZG79HXC
Patreon: / statquest
...or...
UA-cam Membership: / @statquest
...a cool StatQuest t-shirt or sweatshirt:
shop.spreadshirt.com/statques...
...buying one or two of my songs (or go large and get a whole album!)
joshuastarmer.bandcamp.com/
...or just donating to StatQuest!
www.paypal.me/statquest
Lastly, if you want to keep up with me as I research and create new StatQuests, follow me on twitter:
/ joshuastarmer
#statquest #gradientboost - Фільми й анімація
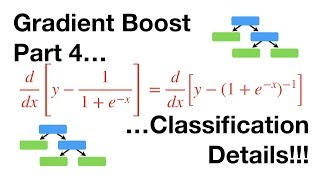







NOTE: Gradient Boost traditionally uses Regression Trees. If you don't already know about Regression Trees, check out the 'Quest: ua-cam.com/video/g9c66TUylZ4/v-deo.html Also NOTE: In Statistics, Machine Learning and almost all programming languages, the default base for the log function, log(), is log base 'e' and that is what I use here.
Support StatQuest by buying my book The StatQuest Illustrated Guide to Machine Learning or a Study Guide or Merch!!! statquest.org/statquest-store/
I am a bit confused. The first Log that you took : Log(4/2) - was that to some base other than e? Cause e^(log(x)) = x for log to the base e
And hence the probability will be simply 2/(1+2) = 2/3 = No of Yes / Total Obs = 4/6 = 2/3
Pls let me know if this is correct.
@@parijatkumar6866 The log is to the base 'e', and yes, e^(log(x)) = x. However, sometimes we don't have x, we just have the log(x), as is illustrated at 9:45. So, rather than use one formula at one point in the video, and another in another part of the video, I believe I can do a better job explaining the concepts if I am consistent.
For Gradient Boost for CLASSIFICATION, because we convert the categorical targets(No or Yes) to probabilities(0-1) and the residuals are calculated from the probabilities, when we build a tree, we still use REGRESSION tree, which use sum of squared residuals to split the tree. Is it correct? Thank you.
@@jonelleyu1895 Yes, even for classification, the target variable is continuous (probabilities instead of Yes/No), and thus, we use regression trees.
I cannot imagine the amount of time and effort used to create these videos. Thanks!
Thank you! Yes, I spent a long time working on these videos.
Thank you so much Josh, I watch 2-3 videos everyday of your machine learning playlist and it just makes my day. Also the fact that you reply to most of the people in the comments section is amazing. Hats off. I only wish the best for you genuinely.
bam!
@@statquest Double Bam!
Bam?
Love these videos! You deserve a Nobel prize for simplifying machine learning explanations!
Wow, thanks!
you really explain complicated things in very easy and catchy way.
i like the way you BAM
BAM!!! :)
Thanks for all you've done. You know your videos is first-class and precision-promised learning source for me.
Great to hear!
The best explanation I've seen so far. BAM! Catchy style as well ;)
Thank you! :)
@@statquest are the individual trees which are trying to predict the residuals regression trees?
@@arunavsaikia2678 Yes, they are regression trees.
That's an excellent lesson and a unique sense of humor. Thank you a lot for the effort in producing these videos!
Glad you like them!
This content shouldn’t be free Josh. So amazing Thank You 👏🏽
Thank you very much! :)
Will recommend the channel for everyone study the machine learning :) Thanks a lot, Josh!
Thank you! :)
I'm enjoying the thorough and simplified explanations as well as the embellishments, but I've had to set the speed to 125% or 150% so my ADD brain can follow along.
Same enjoyment, but higher bpm (bams per minute)
Awesome! :)
Thank you very much! Your step by step explanation is very helpful. It gives to people with poor abstract thinking like me chance to understand all math of these algorithms.
Glad it was helpful!
Yet again. Thank you for making concepts understandable and applicable
Thanks!
Thank you Josh for another exciting video! It was very helpful, especially with the step-by-step explanations!
Hooray! I'm glad you appreciate my technique.
Finally a video that shows the process of gradent boosting. Thanks a lot.
Thanks!
Amazing illustration of a complicated concept. This is best explanation. Thank you so much for all your efforts in making us understand the concepts very well !!! Mega BAM !!
Thank you! :)
I'm new to ML and these contents are gold. Thank you so much for the effort!
Glad you like them!
Love these videos. Starting to understand the concepts. Thank you Josh.
Thank you! :)
Very simple and practical lesson. I did created a worked sample based on this with no problems.
It might be obvious, but not explained there, that initial mean odd should be more than 1. It might be explained as odd of more rare event should be closer to zero.
Glad to see this video arrived just at the time I started to interest this topic.
I guess it will become a "bestseller"
I wish I had a teacher like Josh! Josh, you are the best! BAAAM!
Thank you!:)
Fantastic video , I was confused about the gradient boosting, after watching all parts of gb technique from this channel, I understood it very well :)
Bam! :)
Already waiting for Part 4...thanks as always Josh!
I'm super excited about Part 4 and should be out in a week and a half. This week got a little busy with work, but I'm doing the best that I can.
Thank you so much for this series, I understand everything thanks to you!
bam! :)
Absolutely wonderful. You are are my guru and a true salute to you
Thank you!
Thanks for the video! I’ve been going on a statquest marathon for my job and your videos have been really helpful. Also “they’re eating her...and then they’re going eat me!....OH MY GODDDDDDDDDDDDDDD!!!!!!”
AWESOME!!!
This is amazing. This is the nth time I have come back to this video!
BAM! :)
I have beeeeennnn waiting for this video..... Awesome job Joshh
Thanks!
Excellent as always! Thanks Josh!
Thank you! :)
Amazing and Simple as always. Thank You
Thank you very much! :)
All your videos are super amazing!!!!
Thank you! :)
man, you videos are just super good, really.
Thank you!
amazing as always !!
Any time! :)
Hi Josh, great video.
Thank you so much for your great effort.
Thank you!
I was wrong! All your songs are great!!!
Quadruple BAM!
:)
First of all thank you for such a great explanations. Great job!
It would be great if you could make a video about the Seurat package, which very powerful tool for single cell RNA analysis.
thanks alot , ur videos helped me too much, plz keep going
Thank you!
Great video! Thank you!
Thanks!
Another great lecture by Josh Starmer.
Hooray! :)
@@statquest I actually have a draft paper (not submitted yet) and included you in the acknowledgements if that is ok with you. I will be very happy to send it to you when we have a version out.
@@ElderScrolls7 Wow! that's awesome! Yes, please send it to me. You can do that by contacting me first through my website: statquest.org/contact/
@@statquest I will!
Thank you very much for sharing! :)
Thanks! :)
Best original song ever in the start!
Yes! This is a good one. :)
Your are very helpful, thank you!
Thank you!
Thank you for good videos!
Thanks! :)
Thank you, awesome video
Thank you! :)
This is great!!!
Thank you! :)
absolute gold
Thank you! :)
God bless you , thanks you so so so much.
Thank you! :)
Congrats!! Nice video! Ultra bam!!
Thank you very much! :)
This is absolutely a great video. Will you cover why we can use residual/(p*(1-p)) as the log of odds in your next video? Very excited for the part 4!!
Yes! The derivation is pretty long - lots of little steps, but I'll work it out entirely in the next video. I'm really excited about it as well. It should be out in a little over a week.
Simply Awesome!!!!!!
Thank you! :)
THIS IS A BAMTABULOUS VIDEO !!!!!!
BAM! :)
very detailed and convincing
Thank you! :)
Super Cool to understand and study, Keep Up master..........
Thank you!
Now I want to watch Troll 2
:)
Somewhere around the 15 min mark I made up my mind to search this movie on google
@@AdityaSingh-lf7oe bam
You save me from the abstractness of machine learning.
Thanks! :)
So finallyyyy the MEGAAAA BAMMMMM is included.... Awesomeee
Yes! I was hoping you would spot that! I did it just for you. :)
@@statquest i was in office when i first wrote the comment earlier so couldn't see the full video...
nice explanation and easy to understand thanks bro
You are welcome
Hey Josh,
I really enjoy your teaching. Please make some videos on XG Boost as well.
XGBoost Part 1, Regression: ua-cam.com/video/OtD8wVaFm6E/v-deo.html
Part 2 Classification: ua-cam.com/video/8b1JEDvenQU/v-deo.html
Part 3 Details: ua-cam.com/video/ZVFeW798-2I/v-deo.html
Part 4, Crazy Cool Optimizations: ua-cam.com/video/oRrKeUCEbq8/v-deo.html
the best video for GBT
Thanks!
Bloody awesome 🔥
Thanks!
You r amazing sir! 😊 Great content
Thanks a ton! :)
You are awesome !!
Thank you!
I salute your hardwork, and mine too
Thanks
Superb video without a doubt!!!
one query Josh, do you have any plans to cover a video on "LightGBM" in near future?
I wish I could give you the money that I pay in tuition to my university. It's ridiculous that people who are paid so much can't make the topic clear and comprehensible like you do. Maybe you should do teaching lessons for these people. Also you should have millions of subscribers!
Thank you very much!
thank you very much for your videos !
when will you post the next one ?
thanks for videos. best of anything else I did see. Will use this 'pe-pe-po-pi-po" as message alarm on phone)
bam!
Great videos again! XGBoost next? As this is supposed to solve both variance (RF) & bias (Boost) problems.
Hi Statquest would you please make a video about naive bayes? Please it would be really helpful
Josh my hero!!!
:)
my life has been changed for 3 times. First, when I met Jesus. Second, when I found out my true live. Third, it's you Josh
Triple bam! :)
Hi, I have a few questions: 1. How do we know when GBDT algorithms stops( except the M, number of trees) 2. how do I choose value for the M, how do I know this is optimal ?
Nice work by the way, best explanation I found on the internet.
You can stop when the predictions stop improving very much. You can try different values for M and plot predictions after each tree and see when predictions stop improving.
@@statquest thank you!
Great ..
Very helpful explanation. Can you also add a video on how to do this in R? Thanks
Thank you so much.
you're super humorous!!
bam!
Respect and many thanks from Russia, Moscow
Thank you!
Another superb video Josh. The example was very clear and I’m beginning to see the parallels between the regression and classification case.
One key distinction seems to be in calculating the output value of the terminal nodes for the trees.
In the regression case the average was taken of the values in the terminal nodes (although this can be changed based on the loss function selected). In the classification case it seems that a different method is used to calculate the output values at the terminal nodes but it seems a function of the loss function (presumably a loss function which takes into account a Bernoulli process?).
Secondly we also have to be careful in converting the output of the tree ensemble to a probability score. The output is a log odds score and we have to convert it to a probability before we can calculate residuals and generate predictions.
Is my understanding more or less correct here? Or have I missed something important? Thanks again!
You are correct! When Gradient Boost is used for Classification, some liberties are taken with the loss function that you don't see when Gradient Boost is used for Regression. The difference being that the math is super easy for Regression, but for Classification, there are not any easy "closed form" solutions. In theory, you could use Gradient Descent to find approximations, but that would be slow, so, in practice, people use an approximation based on the Taylor series. That's where that funky looking function used to calculate Output Values comes from. I'll cover that in Part 4.
love it
Thanks! :)
Thank you so much. Great videos again and again.
One question, what is the difference between xgboost and gradient boost?
please reply @statQuest team
Hi Josh thanks alot for your clearly explained videos. I had a question @12.17 when you make the second tree spliting the tree twice with Age only the node and the decision node both are Age. If this is correct will not be a continuous variable create kind of biasness? My second question when we classify the the new person @ 14.40 the initial log(odds) still remains 0.7? Assuming this is nothing but your test set however what happens in the real world scenario were we have more records does the log odds changes as per the new data we want to predict meaning the log of odds for train and test set depends on their own averages (the log of odds)?
Thank you for sharing this Josh. I have a quick question - the subsequent trees which are predicting residuals are regression trees (not classification tree) as we are predicting continuous values (residual probabilities)?
Yes
really liked this intro
bam! :)
How does the multi-classification algorithm work in this case? Using one vs rest method?
It's been over 11 months and no reply from josh... bummer
have the same question
@@AnushaCM well, we could use one vs rest approach
It uses a Softmax objective in the case of multi-class classification. Much like Logistic(Softmax) regression.
Can GB for classification be used for multiple classes? If yes, how will the math be, the video explains for binary classes.
Fantastic song, Josh. I have started picturing that I am attending a class and the professor/lecturer walks by in the room with the guitar, and the greeting would be the song. This could be the new norm following stat quest. One question regarding gradient boost that I have is why it restricts the size of the tree based on the number of leaves. What would happen if that restriction is ignored? Thanks, Josh. Once again, superb video on this topic.
If you build full sized trees then you would overfit the data and you would not be using "weak learners".
finished watching
bam!
Listening to your song makes me thinking of Phoebe Buffay haha.
Love it, anyway !
See: ua-cam.com/video/D0efHEJsfHo/v-deo.html
@@statquest Smelly stat, smelly stat, It's not your fault (to be so hard to understand)
@@statquest btw i like your explanation on gradient boost too
Need to learn how to run powerpoint presentation lol. Amazing stuff
:)
How do you create each tree? In your decision tree video you use them for classification, but here they are used to predict the residuals (something like regression trees)
same question
Waiting for part 4
16:25 My first *Mega Bam!!!*
yep! :)
Thank you so much can you please make a video for Support Vector Machines
Agreed!
subscribed sir....nice efforts sir
Thank you! :)
@StatQuest Thanks for the great content you provide. It's a great explanation of binary-class classification, but how will all this explanation apply to multi-class classification?
Usually people combine multiple models that test class vs everything else.
HEY ! THANKS FOR THIS AWESOME VIDEO. I HAVE A QUESTION : IN THE 12:00 MIN HOW DID YOU BUILD THIS NEW TREE? WHAT WAS THE CRITERIA FOR CHOOSING AGE LESS THAN 66 AS THE ROOT ?
Gradient Boost uses Regression Trees: ua-cam.com/video/g9c66TUylZ4/v-deo.html
Hi Josh, great video as always! Can you explain to me or recommend a material to understand the GB algorithm when we are using it for a non-binary classification? E.g. we have three or more possible outputs for classification.
Unfortunately I don't know a lot about that topic. :(
The legendary MEGA BAM!!
Ha! Thank you! :)
How do you create the classification trees using residual probabilities? Do you stop using some kind of purity index during the optimization in that case? Or do you use regression methods?
We use regression trees, which are explained here: ua-cam.com/video/g9c66TUylZ4/v-deo.html
Thanks for the great video! One question: Why do you use 1-sigmoid instead of sigmoid itself?
What time point in the video are you asking about?
Thanks so much for the amazing videos as always! One question: why the loss function for Gradient Boost classification uses residual instead of cross entropy? Thanks!
Because we only have two different classifications. If we had more, we could use soft max to convert the predictions to probabilities and then use cross entropy for the loss.
@@statquest Thank you!
@statquest you mentioned at 10:45 that we build a lot of trees. Are you trying to refer to bagging or having different tree at each iteration?
Each time we build a new tree.