Key Value Cache in Large Language Models Explained

Вставка
- Опубліковано 18 вер 2024
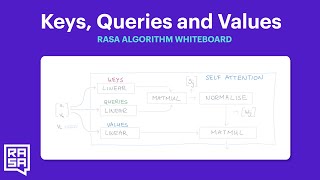
- In this video, we unravel the importance and value of KV cache in optimizing the performance of transformer architectures. We start by exploring the fundamental concepts behind attention mechanisms, the backbone of transformer models. Attention mechanisms enable models to weigh the importance of different input tokens, allowing them to focus on relevant information while processing sequences.
Next, we delve into the KV cache mechanism and its significance in transformer architectures. KV cache optimizes computation by storing previously computed key-value pairs and reusing them across different queries. This not only reduces computational overhead but also enhances memory efficiency, particularly in scenarios where the same key-value pairs are repeatedly used.
We dissect code snippets to compare implementations with and without KV cache, highlighting the computational differences and efficiency gains achieved through KV caching. By analyzing the code, we gain insights into how KV cache streamlines the computation process, leading to faster inference and improved model performance
Llama-2 Paper: arxiv.org/abs/...
Slides and Code: github.com/Vis...
My Links 🔗
👉🏻 Subscribe: / @tensordroid
👉🏻 Twitter: / vishesh_t27
👉🏻 LinkedIn: / vishesh-tripathi


![BERT explained: Training, Inference, BERT vs GPT/LLamA, Fine tuning, [CLS] token](http://i.ytimg.com/vi/90mGPxR2GgY/mqdefault.jpg)





Is kv cache in every LLM? How about the small models