33 - Normal prior conjugate to normal likelihood - intuition

Вставка
- Опубліковано 5 лип 2024
- This video provides some intuition for the properties of the posterior distribution for the case of a normal prior and likelihood.
If you are interested in seeing more of the material, arranged into a playlist, please visit: • Bayesian statistics: a... For more information on econometrics and Bayesian statistics, see: ben-lambert.com/


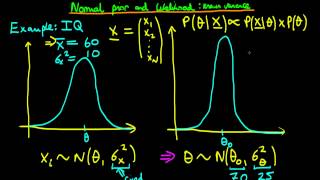






realizing what's going on is a beautiful feeling. thank you
These videos are excellent!!!
Thanks for all these videos
I have question about the result here. We find that the posterior distribution is N(thetaPrime, sigmaPrime^2) and you have given the formulas for thetaPrime and sigmaPrime^2. Now, the posterior distribution is, of course, the distribution we get when we combine the data from our observations together with our prior, so I'd expect that thetaPrime and sigmaPrime would contain the information we gained from our observations. Indeed, thetaPrime depends on the number of observations N as well as the mean of the observed values, xBar. However, sigmaPrime appears to only depend upon the number of observations N, and it seems entirely agnostic as to what the values of the observed xi's are. That is, no matter how wildly different the observed values of xi are from thetaNot (the presumed, uninformed mean prior to applying any data), the variance of the posterior distribution will be completely unaffected by the observations. As a more concrete example, suppose the measured IQs were scattered from 50 to 210 instead of being clustered in the 50s-80s. I would think sigmaPrime would need to grow to reflect the enormous variation in the observed values, but the formula you've derived implies that it does not care what the values are. Is this a consequence of your assumption that sigmaX is a "constant"? Is the result still valid?