Tmeline links!: 00:00 Introduction 00:54 The Dataset 01:44 Package Imports 03:20 Audio Terms to Know 05:30 Reading and Playing Audio Files 08:58 Plotting Raw Audio 10:18 Trim and Zoom 13:19 Spectogram 17:08 Mel Spectogram 19:37 Outro
I've heard so many people say: "Python can't do...", "Python shouldn't really do...", and "Python isn't..." Throughout all my learning up to this point I'm seeing now that Python can do just about anything and I don't understand this half-aversion to Python a lot of developers seem to have when talking about anything that isn't reading tables and manipulating data. Thanks for making this - everyone I had talked to about this topic kept pointing me back to learning C++ and I thought that was a lame answer.
So the reason why devs say things like this is because Python is rarely used to actually put out a full fledged application that's essentially IOT compatible; then there's the speed. C++ is apparently faster so everyone wants you to learn that.
C++ is a lot more safe to use than python IF you know how to allocate the memory, but it’s a risk if you don’t. Relating to this video, as someone who goes to a C++-focused comp sci department, I’ve never been taught how to audio process in C++ but it may be possible
C++ is a lot more safe to use than python IF you know how to allocate the memory, but it’s a risk if you don’t. Relating to this video, as someone who goes to a C++-focused comp sci department, I’ve never been taught how to audio process in C++ but it may be possible
As an audio engineer who's making a smooth transition to data science, you have no idea how interesting this topic is to me. I feel assured that I can put my current expertise in great use despite the career shift/transition.
I need to create a cell phone application that compares two audios, one previously recorded and the other spoken at the time, and I need the application to say if they are the same, is there any reference work that you can point me to?
Really interesting to learn how to deal with audio/sounds with python...something new! Great idea and as usual clear and simple explanation. Thanks a lot Rob PS would love to join one of the next live condig sessions but unfortunately they are not in confortable time slot for ourself in central europe.
Thanks for the feedback Filippo, glad to hear you learned something new. Cool to know you're watching from Europe maybe I'll do a twitch stream at a different time in the future and you can join!
Working in both audio and IT, this sample rate display in your files feel like they're halved. To be able to display a frequency accurate, you'd need 2xfrequency as the sample rate, therefore it would be 44.1khz (which is much more common and I have never seen the option to record witch 22050hz). With 22050 you would have data representing only up to roughly 10khz when accounting for the inquest filter.
22050 is used all over the place where full CD quality (44100) isn’t required. For speech 8000Hz is the max needed and 22050 can sample as you pointed out up to 11KHz
Awsome, thank you. I built some months ago a music genre classifier using spectograms and a Convolutional Neural Network. It was the best thing ever since I got a high accuracy in the first attempt.
@robmulla @ErickCalderin Could you please help me in my acedemic project. I am getting many errors while implementing speech emotion recognition project using cnn. Please guide me to complete my project
Hi, great video but I have a question: since the power parameter in melspectogram is by default set to 2, shouldn't we apply the power_to_tb instead of amplitude_to_db? (18:30)
hi, do you have tutorial feed the spectrogram or melspectrogram to NN?using CNN or RNN-LSTM algorithm?it will be interesting if you continue to feed them to the NN..great presentation..
Hi! Would you be able to create a tutorial on how we can use the processed audio data (such as the one in this video) to train a machine-learning model? Thanks for the great video!
Great question. In this part of the video I am just zooming into part of the audio to show how it looks visually in the plot. Each datapoint has a relatioship to time by the "sample rate" - this audio file has a sample rate of 22050 Hz (22050 samples / second). so 1 sample is 1/ 22050 of a second. This slice of 500 samples equates to ~0.0227 seconds. Hope that helps!
This is so interesting. A few days ago I wanted to produce a digital reproduction of a particular musical note, using the note as the basis and its harmonics (I was analysing A=440Hz, but I wrote the script in such a way I could alter that). So I had basically two aspects to take into account: the frequencies and its amplitudes. I recorded a note from the piano, cleaned it of noise as much as I could and extracted the amplitudes from it for each frequency that forms an A note. It was terrible! The final result sounded ghastly. Your video will help me understand how I must proceed to make a digital sound that makes more sense. I totally would like to learn how to use machine learning on audio processing too.
Glad you are learning something new. At that timestamp I am only looking at a single audio file results. `audio_files[0]` means I am only reading the first value in the audio_files list.
hi Rob, I have question. what is the meaning number of colorbar in 17:00, why is the number is negatif?does it have units?like freq in Hz or time in second?
Great question OrangUtan - the y-axis values in that plot is in decibels (dB). Decibels are not an absolute measure of sound energy but a comparison with a reference value. In the librosa function "power_to_db" you can see it takes a reference value, which we provide as the max value. Since dBs are in log scale all negative numbers are less than this max value. Hope that helps! Check this out for more info: www.scienceabc.com/pure-sciences/why-negative-decibels-are-a-thing.html
@@robmulla hi rob thanks for the answer. another question, since you mention about "power_to_db" what is the difference with function "amplitude_to_db" 18:27?
Given a flute music file, how can we convert the music to notes and decompress the file back to audio blocks using literally any method( trained spectograms, any ML algorithm..)
using python 3.11, and having an awful time with librosa module. so many dependencies, and it says that librosa is not compatible with 3.11 so 3.7 is required. anyone know of a way around this?
Hi Rob, could you give me some pointers please? I suffer from severe sleep apnea which is getting worse and I'm hoping to build a raspberry pi microphone that buzz me gently when it doesn't hear the regular cpap machine whirring up and down of my respiration for more than twenty seconds. How do I write a bot to listen in ? My prototype is just to listen for a certain decibel and constancy of noise, but I'm hoping I can write something I can share for folks to train their own specific sample to detect. Thank you from Vancouver!
Hey, thanks for the comment. This sounds like an interesting project. I'd be a bit concerned with using something like this for such a serious medical condition like sleep apnea. Definately take the advice of a medical professional. But for a side project I think doing auto detection might be possible. You would need to deal with streaming audio which I don't cover here. I'm not sure what the best approach would be but wish you the best of luck and hope your sleep apnea gets better!
Hello! Thank you for the excellent video! I have a question though: What is the difference in use cases between STFT and Melspectrogram? Both methods appear to extract features for the model, but in distinct ways. I am interested in understanding when one is more advantageous than the other. For example for sentiment analysis, I think melspec seems more appropriate but it's nothing more than a guess with a bit of intuion, and feels like if we feel with a speech its better to use melspec and any other sound stft
Why does it seem like the frequency values in the spectrograms are much higher than they should be? I tried to use the same method with a piano sample of an e minor scale and found that the primary frequencies ranged from 1000 Hz to 3000 Hz. Then I noticed that a lot of the frequency content from the speech examples also seems high. Am I doing something wrong?
great video. kinda odd to see "sr" for sampling frequency(Fs in the dsp world) but thats me being particular.... im trying to make the jump from matlab to python ughhh.....
Hi Rob! Thank you for your videos. You inspired me to start digging deep into DataScience. I read a lot of books, watched almost all your videos and did some courses on Coursera. Do you have any recommendations how to train now on real data. I do some work now with some fields of intresst data but i think it would be great to have a community or at least at the very beginning some kind of guided projects. I discoverd data scratch. Do you recommend something like this?
Thanks. That’s a great question. It would depend on how accurate you would need the system to be and the volume of the voice. You could setup a heuristic to determine if there is voice based on the frequencies. You could also train a machine learning model as a classification problem. This would require a lot of labeled examples. There also may be some pre-trained models you could use.
@@robmulla Thank you for your response. Do you have any recommendations on pre-trained models I could explore? Or videos to watch? I don't need anything precise, but want to find out (roughly) what proportion of a corpus of audio contains human speech (as opposed to silence, music, other noise).
Thanks Larry! I learned a lot of what I know through school and kaggle. Thanks for the congrats on the 1k twitch followers, hopefully just the beginning.
Great question Julien. SHIFT + TAB. In jupyterlab it will show the docstring for the function you are calling. This also works in a kaggle notebook like I'm using in the video. I cover this and more in my jupyter notebook tutorial video.
Thanks Rob. How to upload files so that this works (audio_files = glob('../input/ravdess-emotional-speech-audio/*/*.wav'))? Are you using a website or software in this video to do Python? I just started to know Python
Hi as a new comer to Python - I want to get to a stage that I can librosa to play around with audio in raw form - as appossed to using Audacity etc. Specifically interested in band filtering. If I were to follow your excellent videos where will I find the basics to start with please and which Python app are you using or recommend for Win 10 please? I am pretty good with Excel and VBA and have a reasonable understanding of audio so hoping that I can get a good start to learning Python.
I’d recommend checking out my introduction to jupyter and jupyter notebooks video. It explains how to write python code in a notebook. ua-cam.com/video/5pf0_bpNbkw/v-deo.html
Hi i have an audio dataset with gz extension.i dont know how to load it in python and do preprocessing and extract mfcc from it.Can you give me a brief idea on what to do.i am very lost about this
Ill probably never get a reply to this but is it that its either or with the STFT and the Mel spectrogram? Why did u not create the Mel spec from the transformed data?
This is really awesome! Whats your setup to get tto this? I'm on a Mac and so far Librosa has not been successful ...any tips? SQL background & new to Python 😬
Glad you enjoyed the video. I'm running on linux, but librosa usually installs fairly easily for me. I use conda/anaconda as my base python environment. I then just pip installed librosa. Other than that I'd suggest reading the install instructions on their documents page: librosa.org/doc/latest/install.html
really cool! would you be able to do a video on how something like shazam works. conceptually i understand its using key points in audio spectrogram and matching it against library of known files. but i've never been able to get it really work, so was just curious
if you want to increase the resolution on the x axis you can increase the sr. But how do you increase the resolution of the frequency on the y axis? Edit: It seems quite hard to use this code to shift the frequencies as the frequencies are coded in the iteration of the db matrix ... that was my actual aim because it seemed other software kind of compressed alot of data which mostly seems to be accounted to the mel or log scale... i think. If you want to simple shift 1000 hz to 100 hz you lose a lot of frequencies, which could be compensated with higher y-resolution... but i guess there are more clever methods?
Hi, I am a student from Sweden working on my examination project, that is to preform an FFT on an audiofile and then make a 3D model using the results from said FFT. I was wondering if you had any pointers? Thank you in advance.
How can I store the audio data (X axis would be the time and Y axis will the be the power (db)) in an excel file format (So I can analyze the audio data better). I have been reading a lot regarding this but havent come across any one doing this or found a code snippet that does something like this. Its been really bugging me a lot. I would really appereciate your help a lot.
Although I’m not a fan of excel, this should be pretty easy. Simply wrap the DB transformed dataset like this df = pd.Dataframe(y) and then save the data as CSV df.to_csv(‘my_data.csv’)
Awesome! I wish for a tutorial on TTS & STT technology, audio dataset, in python, to create a model for my indigenous language using IPA phonemes. Thanks
Hi Rob, do you know how I can do similar things like YOLO does, but for audio? I am looking for a fast solution that tells me what sounds are recognized in a live audio-stream. Thanks in advance!
Hi, I hope you are doing well. Excellent tutorial May I know, how should i approach to a problem of to detect (just want to detect the presence) of background noise in an audio file Which python audio libraries can be useful?
That's a great question. There are probably many different ways to do this. One way would be adding a filter to the audio file to remove the specific frequencies containing noise. Check out the librosa filters and try some of them out.
I'm not an expert on PCM data, but if you are able to convert it into a numpy array you should be able to save it as a wav file using librosa. Maybe this could help: stackoverflow.com/questions/16111038/how-to-convert-pcm-files-to-wav-files-scripting
@@robmulla With PCM data I mean something like you showed in your intro, 16 kHz audio samples with 16 bit resolution, we capture sound with a simple ESP32 + I2S microphone and the ESP32 streams the samples over a websocket to any other websocket. Is a numpy array different then a normal array or list? Is there an example in one of your tutorials how to put integer sample values into the numpy array and convert it to a wav file? Can this be done also in real time? What I like to do is to record the streamed sound and analyze it later ( or real time if possible) and count how many times a particular sound occurs in the recording. All advise is very welcome! ( technical college project about AI and sound pollution ) Thanks.
I have a question about sample rate. Is sample rate (that integer sr) defined by that method librosa.load() or by some other way? Btw amazing video! Than you so much!
I had a whole spiel about how the sample rate is dictated by the Nyquist theorem but it answered none of your question so I decided it best not but I am also curious how it derived that sample rate seeing as it appears to be half of 44.1 but I'm not certain why it would give it in that form
@@robmulla if i want to use lstm model, suppose i have a video, i have to trim multiple short videos and convert it into audio, then use librosa transformation for these short videos and convert all transformations into time series? Or is it possible with single audio file to split data into frames?
@@robmulla if my loaded audio data shape is (67032,) can i reshape it to (12,5586) #feature size and then repeat data with 3 time step to create (3,10,5586)
Hi, I want to analyze an SNR using a CSV file. I want no the signal from 0-200 Hz. In CSV file only has the data on G. What should I do for SNR analysis?
Hey Rob, could you please create a video that takes the trimmed audio data, data set, and apply this to the actual mp3 file? This should result in a trimmed MP3 file. Saving need not be necessary. I'd like to open a file, and play specific time stamps within the file. Thanks.
Hey Damon, not sure exactly what you are looking to do but should be pretty easy to save a trimmed audio file using the techniques I show in this video. You would just need to also save the result.
Dose anyone know how to make statistic descriptive based on the audio sound like this? I mean what should we count or you can send a reference instead, thank you
I'm not sure exactly what you mean but there are many ways of doing feature engineering with librosa. Check this out: librosa.org/doc/main/feature.html
Im an iOS engineer currently, and am looking to get into audio processing/ML - would you recommend python over c++? Most recommend python for beginners and ML in general, but I have also mostly seen c++ recommended for audio work.
Hey Trevor, that's a great question. I mainly just code in python so I can't really say which is better. At least for machine learning I believe most of what you want to do can be accomplished with python. Hope that helps!
For all frequencies? You could try librosa.effects.trim which will remove silence below a threshold. Then compare with the original and see which timestamps are removed. Good luck!
Hey Danish. Thanks for watching the video. When you says "different dbs" do you mean change the volume of the audio? If so you might want to check this package out: pydub.com/
Ok so my daughter signed herself up for a science fair project where she wants to build a device to data log gunshots in different areas of restricted government land for managing poachers. We’d have to find a way to write a program to distinguish gunshots from other sounds. Can this be done in python?
Hi Rob interesting video. My task is to create mel spectrograms with windows length 93ms 46ms and 23 ms .And then combine them i need one i am confused with this like (128,216,3) what does 3 shows here. 128 in nmels 128 and 216 nu ber of frames.
As a "I understand what's going on but not a coder" I understand that it would take me months if not years to create what I want. How hard would it be to create a audio visualizer plugin? Like make a plugin for a video editor that takes a audio track, analyzes frequencies with custom ranges and drives parameters based on loudness of the frequency ranges you've set up? I'd have to learn how to manage data, memory, incorporate into video editor, libraries, compiling and who knows what else... ah yes, more than basic coding.
Sir I want to make a quranic qaida in which i want to apply pronunciation technique of each alphabet using deep learning so how i can make this project and please define the steps so i can make this project because i am new to deep learning and it is my final project so plz help me
Great question. From what I've seen they are almost identical. There are some differences with pylab being preferred for non-interactive plots.This post goes into more detail: stackoverflow.com/questions/23451028/matplotlib-pyplot-vs-matplotlib-pylab
Your videos are excellent and I really appreciate them. I'm still trying to figure out why you feel the need to add the annoying music that interferes with your discussion.
Hey, I'm learning Python and want to eventually be able to analyze a drummer's rhythmic timing vs. a "perfect" performance. Definitely stealing a few nuggets from this. Thanks! Anyone out there want to help me out???
I want to mimick others voice with my voice. In short i will give a small audio sample as a input (for example my voice) and the code will get the various charateristics of my voice so that i can manipulate it with audio of some other person's voice. Is it possible to do it in python?
exactly its like he starts with teaching a, b, c's and within a minute starts english philosopy class as we if know how to read paragraphs and understand the meaning leave about philosophy









i have no words to express how helpful this was!!! really thank you
Tmeline links!:
00:00 Introduction
00:54 The Dataset
01:44 Package Imports
03:20 Audio Terms to Know
05:30 Reading and Playing Audio Files
08:58 Plotting Raw Audio
10:18 Trim and Zoom
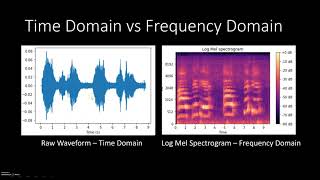
13:19 Spectogram
17:08 Mel Spectogram
19:37 Outro
I've heard so many people say: "Python can't do...", "Python shouldn't really do...", and "Python isn't..."
Throughout all my learning up to this point I'm seeing now that Python can do just about anything and I don't understand this half-aversion to Python a lot of developers seem to have when talking about anything that isn't reading tables and manipulating data.
Thanks for making this - everyone I had talked to about this topic kept pointing me back to learning C++ and I thought that was a lame answer.
Love this feedback. Glad to hear this helps you start your python journey. It’s such an awesome language. The others are good too!
So the reason why devs say things like this is because Python is rarely used to actually put out a full fledged application that's essentially IOT compatible; then there's the speed. C++ is apparently faster so everyone wants you to learn that.
C++ is a lot more safe to use than python IF you know how to allocate the memory, but it’s a risk if you don’t. Relating to this video, as someone who goes to a C++-focused comp sci department, I’ve never been taught how to audio process in C++ but it may be possible
C++ is a lot more safe to use than python IF you know how to allocate the memory, but it’s a risk if you don’t. Relating to this video, as someone who goes to a C++-focused comp sci department, I’ve never been taught how to audio process in C++ but it may be possible
As an audio engineer who's making a smooth transition to data science, you have no idea how interesting this topic is to me. I feel assured that I can put my current expertise in great use despite the career shift/transition.
I went through a similar career change so I can totally relate. You’ll never regret learning python. It’s so powerful!
@@robmulla I found my place in the world. thamks a lot!!!!
I need to create a cell phone application that compares two audios, one previously recorded and the other spoken at the time, and I need the application to say if they are the same, is there any reference work that you can point me to?
How can machine learning and AI change your previous industry ?(audio/sound engineer)
@@EtBilu295 Shazam algorithm, check it out
Am currently doing an GAN project to generate audios this was really helpful, Thank you!!
This intrigued me as a data scientist who works with EEG data (brain signals). Signal is signal in the end :)
Very true. Signal is signal. Glad you found it helpful.
Hey Rob, thanks for a great video. I've been looking at how to do audios and this video was great to jump into.
Thanks Hadi. I'm glad you found it helpful.
Really interesting to learn how to deal with audio/sounds with python...something new! Great idea and as usual clear and simple explanation. Thanks a lot Rob PS would love to join one of the next live condig sessions but unfortunately they are not in confortable time slot for ourself in central europe.
Thanks for the feedback Filippo, glad to hear you learned something new. Cool to know you're watching from Europe maybe I'll do a twitch stream at a different time in the future and you can join!
Thanks for this! Very nice for beginners in this area
Glad you found it helpful!
Working in both audio and IT, this sample rate display in your files feel like they're halved. To be able to display a frequency accurate, you'd need 2xfrequency as the sample rate, therefore it would be 44.1khz (which is much more common and I have never seen the option to record witch 22050hz). With 22050 you would have data representing only up to roughly 10khz when accounting for the inquest filter.
22050 is used all over the place where full CD quality (44100) isn’t required. For speech 8000Hz is the max needed and 22050 can sample as you pointed out up to 11KHz
this is what im looking for, thanks for the great video !!!
Thanks so much. I’m glad it helped you out.
Gonna use this for a project, thanks!
Awesome! I love it.
This guy's videos are so awesome. Big fan.
Awsome, thank you. I built some months ago a music genre classifier using spectograms and a Convolutional Neural Network. It was the best thing ever since I got a high accuracy in the first attempt.
Nice work! Do you have the code you could share?
@robmulla @ErickCalderin
Could you please help me in my acedemic project.
I am getting many errors while implementing speech emotion recognition project using cnn.
Please guide me to complete my project
thank you for sharing this, really cool stuff.
I appreciate that Justin. Glad you liked it.
Hi, great video but I have a question: since the power parameter in melspectogram is by default set to 2, shouldn't we apply the power_to_tb instead of amplitude_to_db? (18:30)
Amazing tutorial, thank you!
Thanks for watching and giving feedback!
hi, do you have tutorial feed the spectrogram or melspectrogram to NN?using CNN or RNN-LSTM algorithm?it will be interesting if you continue to feed them to the NN..great presentation..
That’s a good suggestion. I’ve made models like that before but no video tutorial yet. I’ll put it on my todo list. Thanks for the suggestion
Nice. It’s what I need.
I guess I’m just what you needed!
Hi! Would you be able to create a tutorial on how we can use the processed audio data (such as the one in this video) to train a machine-learning model? Thanks for the great video!
Hey Jerryl. I have plans to do that but I'm not sure when. Hope you liked the video.
hello, i couldn't understand what the numbers in the chosen interval [30000,30500] refer to, are they seconds or maybe microseconds 12:42
Great question. In this part of the video I am just zooming into part of the audio to show how it looks visually in the plot. Each datapoint has a relatioship to time by the "sample rate" - this audio file has a sample rate of 22050 Hz (22050 samples / second). so 1 sample is 1/ 22050 of a second. This slice of 500 samples equates to ~0.0227 seconds. Hope that helps!
@@robmulla thanks a lot !
This is so interesting.
A few days ago I wanted to produce a digital reproduction of a particular musical note, using the note as the basis and its harmonics (I was analysing A=440Hz, but I wrote the script in such a way I could alter that). So I had basically two aspects to take into account: the frequencies and its amplitudes.
I recorded a note from the piano, cleaned it of noise as much as I could and extracted the amplitudes from it for each frequency that forms an A note. It was terrible! The final result sounded ghastly.
Your video will help me understand how I must proceed to make a digital sound that makes more sense. I totally would like to learn how to use machine learning on audio processing too.
Really nice video! Thanks
Thanks so much for the feedback.
sir i am new to data proceesing so plz tell me that on 8:58 In plotting the raw audio you analyze one voice or all the voices
Glad you are learning something new. At that timestamp I am only looking at a single audio file results. `audio_files[0]` means I am only reading the first value in the audio_files list.
@@robmulla thanks for reply
Very nicely explained!!🙂
hi Rob, I have question.
what is the meaning number of colorbar in 17:00, why is the number is negatif?does it have units?like freq in Hz or time in second?
Great question OrangUtan - the y-axis values in that plot is in decibels (dB). Decibels are not an absolute measure of sound energy but a comparison with a reference value. In the librosa function "power_to_db" you can see it takes a reference value, which we provide as the max value. Since dBs are in log scale all negative numbers are less than this max value. Hope that helps! Check this out for more info: www.scienceabc.com/pure-sciences/why-negative-decibels-are-a-thing.html
@@robmulla hi rob thanks for the answer. another question, since you mention about "power_to_db" what is the difference with function "amplitude_to_db" 18:27?
sir in 7:26 this part i am getting module not callable error kindly tell how to solve this issue
it's probably something with how you imported it but I cant say without seeing your code.
@@robmulla is it possible somehow to send you ,it'll be a great help for me
can I make this project using vs code?
Thank You so much sir this video is very helpful.
Given a flute music file, how can we convert the music to notes and decompress the file back to audio blocks using literally any method( trained spectograms, any ML algorithm..)
I’m not sure exactly but I know librosa has some modules for pulling on notes.
I love content thank you. please make more :)
Thanks, will do!
Thank you for informative video. May I ask what software are you using in it? Is it JupyterLab?
great vid!
Thanks for watching 😆
using python 3.11, and having an awful time with librosa module. so many dependencies, and it says that librosa is not compatible with 3.11 so 3.7 is required. anyone know of a way around this?
Why not create a conda or virtual environment with python 3.7?
Super helpful!
Hi Rob, could you give me some pointers please? I suffer from severe sleep apnea which is getting worse and I'm hoping to build a raspberry pi microphone that buzz me gently when it doesn't hear the regular cpap machine whirring up and down of my respiration for more than twenty seconds. How do I write a bot to listen in ? My prototype is just to listen for a certain decibel and constancy of noise, but I'm hoping I can write something I can share for folks to train their own specific sample to detect. Thank you from Vancouver!
Hey, thanks for the comment. This sounds like an interesting project. I'd be a bit concerned with using something like this for such a serious medical condition like sleep apnea. Definately take the advice of a medical professional. But for a side project I think doing auto detection might be possible. You would need to deal with streaming audio which I don't cover here. I'm not sure what the best approach would be but wish you the best of luck and hope your sleep apnea gets better!
Hello! Thank you for the excellent video! I have a question though: What is the difference in use cases between STFT and Melspectrogram? Both methods appear to extract features for the model, but in distinct ways. I am interested in understanding when one is more advantageous than the other. For example for sentiment analysis, I think melspec seems more appropriate but it's nothing more than a guess with a bit of intuion, and feels like if we feel with a speech its better to use melspec and any other sound stft
Did you get answer? I reall wonder what's the difference between them
Why does it seem like the frequency values in the spectrograms are much higher than they should be? I tried to use the same method with a piano sample of an e minor scale and found that the primary frequencies ranged from 1000 Hz to 3000 Hz. Then I noticed that a lot of the frequency content from the speech examples also seems high. Am I doing something wrong?
That’s a good point. I don’t really know. Have you figured it out? I’m curious to know.
Its so cool!
Glad you think so. Thanks for watching.
How can we split an audio file into several equal sized chunks ( with padding)? ( I'm dividing the audio into chunks to apply DCT on every chunk)
Good question. This is pretty comment for deep learning. Check this notebook: www.kaggle.com/code/colinnordin/audio-segmentation-tutorial
@@robmulla Thank you for your response.
Glob, librosa, wavered, ivi kakundaa hasalu dsp audio yenduku work avataledu adigo librosa
great video. kinda odd to see "sr" for sampling frequency(Fs in the dsp world) but thats me being particular.... im trying to make the jump from matlab to python ughhh.....
Glad you liked the video. Welcome to the wonderful world of python. You will love it.
Hi Rob! Thank you for your videos. You inspired me to start digging deep into DataScience. I read a lot of books, watched almost all your videos and did some courses on Coursera.
Do you have any recommendations how to train now on real data.
I do some work now with some fields of intresst data but i think it would be great to have a community or at least at the very beginning some kind of guided projects. I discoverd data scratch. Do you recommend something like this?
Awesome video! Is there a way to use the Melspectrogram to determine programmatically if a file contains human speech?
Thanks. That’s a great question. It would depend on how accurate you would need the system to be and the volume of the voice. You could setup a heuristic to determine if there is voice based on the frequencies. You could also train a machine learning model as a classification problem. This would require a lot of labeled examples. There also may be some pre-trained models you could use.
@@robmulla Thank you for your response. Do you have any recommendations on pre-trained models I could explore? Or videos to watch? I don't need anything precise, but want to find out (roughly) what proportion of a corpus of audio contains human speech (as opposed to silence, music, other noise).
Hey Tom, nice video!
Can you show us wich reference did u use, any books, courses, etc?
Love your content, congrats for the 1k followers on twitch
Thanks Larry! I learned a lot of what I know through school and kaggle. Thanks for the congrats on the 1k twitch followers, hopefully just the beginning.
Can someone explain to me how he can show the details here 11:25 ?
Great question Julien. SHIFT + TAB. In jupyterlab it will show the docstring for the function you are calling. This also works in a kaggle notebook like I'm using in the video. I cover this and more in my jupyter notebook tutorial video.
awesome !!
Glad you liked it!
Thanks Rob. How to upload files so that this works (audio_files = glob('../input/ravdess-emotional-speech-audio/*/*.wav'))? Are you using a website or software in this video to do Python? I just started to know Python
Hi as a new comer to Python - I want to get to a stage that I can librosa to play around with audio in raw form - as appossed to using Audacity etc. Specifically interested in band filtering. If I were to follow your excellent videos where will I find the basics to start with please and which Python app are you using or recommend for Win 10 please? I am pretty good with Excel and VBA and have a reasonable understanding of audio so hoping that I can get a good start to learning Python.
I’d recommend checking out my introduction to jupyter and jupyter notebooks video. It explains how to write python code in a notebook. ua-cam.com/video/5pf0_bpNbkw/v-deo.html
@@robmulla many thanks will do!
Hi i have an audio dataset with gz extension.i dont know how to load it in python and do preprocessing and extract mfcc from it.Can you give me a brief idea on what to do.i am very lost about this
gz is usually a gzipped file. So you need to unzip it first.
how to setup a real time data from opencv, or using python , using usb bluetooth adapter for spectrogram?
cant find a way around for get answer.
Ill probably never get a reply to this but is it that its either or with the STFT and the Mel spectrogram? Why did u not create the Mel spec from the transformed data?
This is really awesome! Whats your setup to get tto this? I'm on a Mac and so far Librosa has not been successful ...any tips? SQL background & new to Python 😬
Glad you enjoyed the video. I'm running on linux, but librosa usually installs fairly easily for me. I use conda/anaconda as my base python environment. I then just pip installed librosa. Other than that I'd suggest reading the install instructions on their documents page: librosa.org/doc/latest/install.html
@@robmulla thank you so much for the info and prompt response. I think my African Bantu Language project has a chance with the milestones.
Sir, you are the one.
I'm a hobbist and it's video was useful to me.
Thanks for share you time and expertise with us.
really cool! would you be able to do a video on how something like shazam works. conceptually i understand its using key points in audio spectrogram and matching it against library of known files. but i've never been able to get it really work, so was just curious
Thanks. That’s a great idea for a future video.
Hey Rob, Can you do a audio background noise cancellation using deep learning tutorial if you can.
Thanks for the suggestion. I’ll add it to the list of potential future videos!
if you want to increase the resolution on the x axis you can increase the sr. But how do you increase the resolution of the frequency on the y axis?
Edit: It seems quite hard to use this code to shift the frequencies as the frequencies are coded in the iteration of the db matrix ... that was my actual aim because it seemed other software kind of compressed alot of data which mostly seems to be accounted to the mel or log scale... i think. If you want to simple shift 1000 hz to 100 hz you lose a lot of frequencies, which could be compensated with higher y-resolution... but i guess there are more clever methods?
Hi, I am a student from Sweden working on my examination project, that is to preform an FFT on an audiofile and then make a 3D model using the results from said FFT. I was wondering if you had any pointers?
Thank you in advance.
nice thanks!!
Glad you like it!
How can I store the audio data (X axis would be the time and Y axis will the be the power (db)) in an excel file format (So I can analyze the audio data better). I have been reading a lot regarding this but havent come across any one doing this or found a code snippet that does something like this. Its been really bugging me a lot. I would really appereciate your help a lot.
Although I’m not a fan of excel, this should be pretty easy. Simply wrap the DB transformed dataset like this df = pd.Dataframe(y) and then save the data as CSV df.to_csv(‘my_data.csv’)
@@robmulla alright. Thank you so much.
Awesome!
I wish for a tutorial on TTS & STT technology, audio dataset, in python, to create a model for my indigenous language using IPA phonemes. Thanks
That’s a good idea. Thanks for watching
Hi Rob, do you know how I can do similar things like YOLO does, but for audio? I am looking for a fast solution that tells me what sounds are recognized in a live audio-stream. Thanks in advance!
Great presentation. What SW did you use to get your video in front of the notebook?
Thanks. I used a green screen sheet with OBS software to overlay my camera in front of the screen.
@@robmulla Thanks. Please check your twitter messages, I've sent you a PM there
Hi,
I hope you are doing well. Excellent tutorial
May I know, how should i approach to a problem of to detect (just want to detect the presence) of background noise in an audio file
Which python audio libraries can be useful?
That's a great question. There are probably many different ways to do this. One way would be adding a filter to the audio file to remove the specific frequencies containing noise. Check out the librosa filters and try some of them out.
Hi If I send sound converted to PCM data to a python websocket, how then convert it to a wav file, save it and analyze it? Thanks!
I'm not an expert on PCM data, but if you are able to convert it into a numpy array you should be able to save it as a wav file using librosa. Maybe this could help: stackoverflow.com/questions/16111038/how-to-convert-pcm-files-to-wav-files-scripting
@@robmulla With PCM data I mean something like you showed in your intro, 16 kHz audio samples with 16 bit resolution, we capture sound with a simple ESP32 + I2S microphone and the ESP32 streams the samples over a websocket to any other websocket. Is a numpy array different then a normal array or list? Is there an example in one of your tutorials how to put integer sample values into the numpy array and convert it to a wav file?
Can this be done also in real time?
What I like to do is to record the streamed sound and analyze it later ( or real time if possible) and count how many times a particular sound occurs in the recording. All advise is very welcome! ( technical college project about AI and sound pollution ) Thanks.
I have a question about sample rate. Is sample rate (that integer sr) defined by that method librosa.load() or by some other way? Btw amazing video! Than you so much!
I had a whole spiel about how the sample rate is dictated by the Nyquist theorem but it answered none of your question so I decided it best not but I am also curious how it derived that sample rate seeing as it appears to be half of 44.1 but I'm not certain why it would give it in that form
thanks for the tutorial.
how can i convert to time series data wrt to frames
ex: (time_step, feature_dim)
Absolutely, a melspectogram is just like that - time x feature!
@@robmulla if i want to use lstm model, suppose i have a video, i have to trim multiple short videos and convert it into audio, then use librosa transformation for these short videos and convert all transformations into time series? Or is it possible with single audio file to split data into frames?
@@robmulla if my loaded audio data shape is (67032,)
can i reshape it to (12,5586) #feature size
and then repeat data with 3 time step to create (3,10,5586)
Hi, I want to analyze an SNR using a CSV file. I want no the signal from 0-200 Hz. In CSV file only has the data on G. What should I do for SNR analysis?
thanks man
Thanks for watching.
Hey Rob, could you please create a video that takes the trimmed audio data, data set, and apply this to the actual mp3 file? This should result in a trimmed MP3 file. Saving need not be necessary. I'd like to open a file, and play specific time stamps within the file. Thanks.
Hey Damon, not sure exactly what you are looking to do but should be pretty easy to save a trimmed audio file using the techniques I show in this video. You would just need to also save the result.
what book can you recommend to learn everything that is needed for machine learning?
There are many. "Approaching (Almost) Any Machine Learning Problem" by my friend Abhishek is a good one but also very technical.
Dose anyone know how to make statistic descriptive based on the audio sound like this? I mean what should we count or you can send a reference instead, thank you
I'm not sure exactly what you mean but there are many ways of doing feature engineering with librosa. Check this out: librosa.org/doc/main/feature.html
Im an iOS engineer currently, and am looking to get into audio processing/ML - would you recommend python over c++? Most recommend python for beginners and ML in general, but I have also mostly seen c++ recommended for audio work.
Hey Trevor, that's a great question. I mainly just code in python so I can't really say which is better. At least for machine learning I believe most of what you want to do can be accomplished with python. Hope that helps!
How to get all time stamp where audio intensity is 0db ¿
For all frequencies? You could try librosa.effects.trim which will remove silence below a threshold. Then compare with the original and see which timestamps are removed. Good luck!
@@robmulla how to compare them, i m a total noob 😂
Great Job, obrigado.
i need help on how to install librosa library in python
Hi. I wanna play an audio in python with different Dbs. how to do that please?
Hey Danish. Thanks for watching the video. When you says "different dbs" do you mean change the volume of the audio? If so you might want to check this package out: pydub.com/
Ok so my daughter signed herself up for a science fair project where she wants to build a device to data log gunshots in different areas of restricted government land for managing poachers. We’d have to find a way to write a program to distinguish gunshots from other sounds. Can this be done in python?
Can you analyze audio to see if it's been edited?
Hi
Can you help for finding glitches or audio obnormalites from wav file
Hi Rob interesting video. My task is to create mel spectrograms with windows length 93ms 46ms and 23 ms .And then combine them i need one i am confused with this like (128,216,3) what does 3 shows here. 128 in nmels 128 and 216 nu ber of frames.
What are the y values that you first extract?
Amazing Tutorial
Great question. Check out the filters in scipy.signal. There are different filters you can apply that should work similar to an equalizer. Good luck!
As a "I understand what's going on but not a coder" I understand that it would take me months if not years to create what I want.
How hard would it be to create a audio visualizer plugin? Like make a plugin for a video editor that takes a audio track, analyzes frequencies with custom ranges and drives parameters based on loudness of the frequency ranges you've set up?
I'd have to learn how to manage data, memory, incorporate into video editor, libraries, compiling and who knows what else... ah yes, more than basic coding.
Sir I want to make a quranic qaida in which i want to apply pronunciation technique of each alphabet using deep learning so how i can make this project and please define the steps so i can make this project because i am new to deep learning and it is my final project so plz help me
Thanks for your question. That sounds like an interesting project but it's well beyond the scope of what I can help you with here. Good luck.
hello everyone, I have audio data, I want to train this audio data and use it offline. Is there anyone to help me?
Not sure exactly what you are asking. By "train" do you mean record?
@@robmulla No, I have voice data, how can I create a model from this voice data, I will use it to convert text to speech
Awsomeeee!!!!, can I feed the CNN network by melspectograms ?
what are you using as notepad to write the codes
Is there different between matplotlib.pyplot and .pylab?
Great question. From what I've seen they are almost identical. There are some differences with pylab being preferred for non-interactive plots.This post goes into more detail: stackoverflow.com/questions/23451028/matplotlib-pyplot-vs-matplotlib-pylab
Thanks @@robmulla
Your videos are excellent and I really appreciate them. I'm still trying to figure out why you feel the need to add the annoying music that interferes with your discussion.
Hey, I'm learning Python and want to eventually be able to analyze a drummer's rhythmic timing vs. a "perfect" performance. Definitely stealing a few nuggets from this. Thanks! Anyone out there want to help me out???
That seems like a cool project. I can’t help directly but you can join my discord and ask there! Glad this video helped you get started
can someone help me out with some scientific papers on the topic?
you're not working in jupyter?
Its kaggle notebook
This is SO cool!!!!!! HOW freeking cool is THIS , sh$%t , right guys? .. .. .. :-D
I want to mimick others voice with my voice. In short i will give a small audio sample as a input (for example my voice) and the code will get the various charateristics of my voice so that i can manipulate it with audio of some other person's voice. Is it possible to do it in python?
I need the video pls
What video do you need. I'm confused about your comment :)
I have subscriber you.
Thanks so much for the sub!
You can create me product?
it's a shame that this is such a low level tutoial but you assume that I'm already familiar with the meaning of the terminology.
exactly its like he starts with teaching a, b, c's and within a minute starts english philosopy class as we if know how to read paragraphs and understand the meaning leave about philosophy
???????????
Sorry - did you have a question?