By definition no. "Intervening on" means you don't affect the upstream. Imagine W is age, and in general treatment is assigned non-randomly wrt age. Changing how treatment is assigned (i.e. intervening on e(W)) does not change the age distribution of the population, let alone any individuals' age. That said, by inserting the node e(w) into the causal graph at 2:06, we're not intervening. We're essentially introducing a mediator variable that we know, by definition, completely mediates W's effect on T.
Thanks a lot for the work Brady! Having a question on the slide 26, and the Equation 7.21 in your book. Should the denominator be n (i.e. the total number of data points) instead? And correspondingly, in the proof, should the empirical estimation of A.18 be \sum y p(y, w | t) / p(t | w), instead of the joint version in A.16?
I've tried to follow the proof of propensity score theorem from your book (section A.2). I'm stuck at A.8: how is this possible that (1) E [T | Y(t), e(W)] is equal to (2) E [ E [T | Y(t), e(W), W] | Y(t), e(W)]? Let's assume a discrete scenario: E [T | Y(t), e(W)] = ∑_i { E [T | Y(t), e(w_i), w_i] * P(w_i) } What bothers me is that in (1) W is given, while in the second part it depends on the expectation.
Mechanically, one can think of it as applying the law of iterated expectations to a conditional expectation. One does need to preserve (Y(t)) and (e(W)) as conditionals in the outer expectation.
What does the e in e(W) stand for? Is it Eulers number or does it stand for exponential? When estimating the propensity score using logistic regression the formula is: e(W) = e(W) / (1- e(W)), right? Thanks in advance for your response!
I think your formula for an estimate of the inverse probability weighting based ATE is wrong: $\hat{\tau}=\frac{1}{n_1} \sum_{i: t_i=1} \frac{y_i}{\hat{e}\left(w_i ight)}-\frac{1}{n_0} \sum_{i: t_i=0} \frac{y_i}{1-\hat{e}\left(w_i ight)}$ The point is the expectation is over the whole population. Both terms should be divided by total n, NOT n_1 or n_0, another intuition is inverse probability is used to inflate those "rare" data points. Another way to check is imagining e(w_i)=1/2.



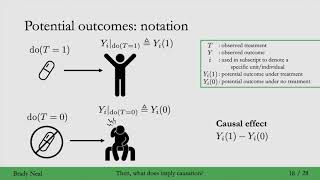






2:06 Inserting e(W) as a node in the causal graph does not make sense to me. Intervening on e(W) would affect W, wouldn't it?
By definition no. "Intervening on" means you don't affect the upstream. Imagine W is age, and in general treatment is assigned non-randomly wrt age. Changing how treatment is assigned (i.e. intervening on e(W)) does not change the age distribution of the population, let alone any individuals' age.
That said, by inserting the node e(w) into the causal graph at 2:06, we're not intervening. We're essentially introducing a mediator variable that we know, by definition, completely mediates W's effect on T.
very nice work
Thanks a lot for the work Brady!
Having a question on the slide 26, and the Equation 7.21 in your book. Should the denominator be n (i.e. the total number of data points) instead? And correspondingly, in the proof, should the empirical estimation of A.18 be \sum y p(y, w | t) / p(t | w), instead of the joint version in A.16?
I've tried to follow the proof of propensity score theorem from your book (section A.2).
I'm stuck at A.8: how is this possible that (1) E [T | Y(t), e(W)] is equal to (2) E [ E [T | Y(t), e(W), W] | Y(t), e(W)]?
Let's assume a discrete scenario: E [T | Y(t), e(W)] = ∑_i { E [T | Y(t), e(w_i), w_i] * P(w_i) }
What bothers me is that in (1) W is given, while in the second part it depends on the expectation.
Mechanically, one can think of it as applying the law of iterated expectations to a conditional expectation. One does need to preserve (Y(t)) and (e(W)) as conditionals in the outer expectation.
What does the e in e(W) stand for? Is it Eulers number or does it stand for exponential? When estimating the propensity score using logistic regression the formula is: e(W) = e(W) / (1- e(W)), right?
Thanks in advance for your response!
e(W) is a function that takes W as an argument. He could have been used k(W).
I think your formula for an estimate of the inverse probability weighting based ATE is wrong:
$\hat{\tau}=\frac{1}{n_1} \sum_{i: t_i=1} \frac{y_i}{\hat{e}\left(w_i
ight)}-\frac{1}{n_0} \sum_{i: t_i=0} \frac{y_i}{1-\hat{e}\left(w_i
ight)}$
The point is the expectation is over the whole population. Both terms should be divided by total n, NOT n_1 or n_0, another intuition is inverse probability is used to inflate those "rare" data points.
Another way to check is imagining e(w_i)=1/2.