[ICASSP 2020] Streaming Automatic Speech Recognition with the Transformer Model

Вставка
- Опубліковано 26 кві 2020
- MERL Researcher Niko Moritz presents his paper titled "Streaming Automatic Speech Recognition with the Transformer Model" for the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), held virtually May 4-8 2020. The paper was co-authored with MERL researchers Takaaki Hori and Jonathan Le Roux.
Paper: ieeexplore.iee..., www.merl.com/p...
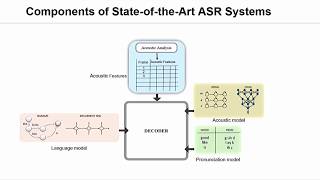
Abstract: Encoder-decoder based sequence-to-sequence models have demonstrated state-of-the-art results in end-to-end automatic speech recognition (ASR). Recently, the transformer architecture, which uses self-attention to model temporal context information, has been shown to achieve significantly lower word error rates (WERs) compared to recurrent neural network (RNN) based system architectures. Despite its success, the practical usage is limited to offline ASR tasks, since encoder-decoder architectures typically require an entire speech utterance as input. In this work, we propose a transformer based end-to-end ASR system for streaming ASR, where an output must be generated shortly after each spoken word. To achieve this, we apply time-restricted self-attention for the encoder and triggered attention for the encoder-decoder attention mechanism. Our proposed streaming transformer architecture achieves 2.8% and 7.2% WER for the "clean" and "other" test data of LibriSpeech, which to our knowledge is the best published streaming end-to-end ASR result for this task. - Наука та технологія