Guy was asked to design a Web Crawler, ended up designing a fucking BING. All jokes aside, you apply very practical knowledge on your system design. Very nice
Very comprehensive and high level system design. This covers web crawler and search engine. Would like to deep dive into Web Crawler more, such as storage choice, seed URLs selections, re-crawl strategies, politeness etc.
Hi! Excellent design, really helpful. If you revisit this diagram, what would you change? I'd personally like to see more emphasis in the re-crawl strategy, as some sites will be static and some might need to be revisited more often. I think handling one or many priority queues will help, then the re-crawl service could instead help making the prioritization
Thanks for cool video! One question: what makes you decide to decouple "scrape" and "link extract" functionality into two components? I mean why not putting both functionalities into the "scraper" component?




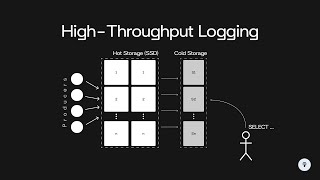





Guy was asked to design a Web Crawler, ended up designing a fucking BING. All jokes aside, you apply very practical knowledge on your system design. Very nice
Very comprehensive and high level system design. This covers web crawler and search engine. Would like to deep dive into Web Crawler more, such as storage choice, seed URLs selections, re-crawl strategies, politeness etc.
unable to access discord channel. But amazing design
Hi! Excellent design, really helpful. If you revisit this diagram, what would you change?
I'd personally like to see more emphasis in the re-crawl strategy, as some sites will be static and some might need to be revisited more often.
I think handling one or many priority queues will help, then the re-crawl service could instead help making the prioritization
Thanks for cool video! One question: what makes you decide to decouple "scrape" and "link extract" functionality into two components? I mean why not putting both functionalities into the "scraper" component?
which excalidraw library do you use to get the database drawings? I couldn't find it