Smart RAG: Domain-Specific Fine-Tuning for End-to-End Retrieval

Вставка
- Опубліковано 20 вер 2023
- GPT-4 Summary: "Revolutionize Your AI Skills with Smart RAG Systems: Exclusive Event! Dive into the world of 'real' Retrieval Augmented Generation (RAG) systems and master how to optimize them for top-tier Large Language Model (LLM) outputs. This event is a goldmine for understanding the application of Smart RAG systems in specialized fields like law, medicine, and insurance, harnessing the potential of Domain Adapted Language Models (DALM). Witness the unveiling of arcee.ai, a groundbreaking tool simplifying the creation of Smart RAG systems. Perfect for data scientists, ML engineers, and LLM practitioners in domain-specific languages. Join us for live demonstrations and hands-on experience with our shared GitHub repositories and Colab notebooks. Don't miss this chance to elevate your expertise in advanced RAG QA systems and the fundamentals of RAG!"
Event page: lu.ma/smartRAG
Have a question for a speaker? Drop them here:
app.sli.do/event/25HmFu4PfDhN...
Speakers:
Dr. Greg Loughnane, Founder & CEO, AI Makerspace
/ greglough. .
Chris Alexiuk, CTO, AI Makerspace
/ csalexiuk
Join our community to start building, shipping, and sharing with us today!
/ discord
Apply to our upcoming LLM Ops: LLMs in production course on Maven today!
maven.com/aimakerspace/llmops
How'd we do? Share your feedback and suggestions for future events.
forms.gle/diwu2kDx5PcUbZ5t7 - Розваги
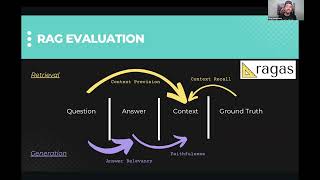








Slides & Colab from the event!
Slides: www.canva.com/design/DAFvFEhCJtg/Mthlo-nWXAPck3iK3JaB7Q/edit?DAFvFEhCJtg&
Google Colab Code: colab.research.google.com/drive/1wwGLuEreZJfpxTvFeMLFbWb1GkRkXFwS?usp=sharing
Same url for both?
Please share the github repo link as well.
As @mohamedchofra pointed, the Colab link is the same for the canva. Could you fix with the correct url?
Whoops @@LeonardoRocha0 And @mohamedchorfa - fixed!
This is super interesting, I hope the channel blows up and we get to see more similar content. 👍
Same!
Thanks Team, for that educative session. 👍
You bet @chrisogonas!
Thank you the topic of RAG is very interesting.
this video saved my life !!!!! amazing work!
We love to hear that!
You guys are the RAG masters ! Thank you for the informative videos.
Hahaha thanks @taylorfans1000!
Thanks for the video, guys, most useful were definitely notebooks with comments of Chris. Thumb up, subscribed. But appreciate also information given by Greg, just seemed a bit high level or not explained deep enough/explained too complex. Probably better would be then to explain less but in more details , with examples. The aim I assume is not watch and think "or that guy knows a lot, although I don't understand anything". But actually to learn something. Straight and maybe not "nice" feedback, but hope it will help. You guys are doing great job sharing insides and helping others. I'm far behind with that so far))
Haven't reached so far a point where I need to fine tune. Working now mostly on retrieval step and different strategies like pre-filtering of text (key word search) before retrieval from vector store. But definitely fine tuning of embedding model might be one of solutions for me. As for now I'm struggling to "emphasize" , give higher priority to some domain relevant words automatically inside the question over other regular non relevant ones like "in", "please" etc. To get chunks that are more relevant for answer within K chunks selected and increase chance to provide more relevant context to LLM. So thanks for hints and well done!
Thanks for your comments, and appreciate the feedback!
Super interesting content. Thanks for posting!
I would say the piece, which I often miss is an actual example of using this thing (is it 1 model, 2 models, do we still use vector db?)
And also some discussion about the practical side of things. What if my data changes?
Nevertheless awesome work, cheers guys!
In this case we're doing simultaneous fine-tuning of both embedding and LLM models! And yes, we're still using a vector DB here for all of our documents.
When data changes significantly, re-training (e.g., fine-tuning) should be considered for sure. Of course, what exactly do you mean by "changes" matters (e.g., what metrics are you measuring, how much have they moved, how you've noticed the performance degrading (or not) from the actual user's perspective, etc. are good places to start).
Thanks for your support @alchemikification!
very good, tks
Awesome video again! These videos are blowing up!
My company has 200K+ pdfs ranging from 100 pages to 10000+ pages. Will this framework work for such enormous data? Wondering how long it will take to create the synthetic triples for millions of PDFs' chunks that would get created from 200K+ pdfs. Would love to hear your thoughts!!!
Thanks Team, this a great video.
How do we now make queries from the dalm after training and finetuning?
You'll query it the same as you might any other Hugging Face model!
You can call itself pipeline directly with the "text generation" task!
Great video on E2E RAG pipelines and where /when to fine tune (embedding model, the LLM itself, or retrieval models). I was wondering if you had a source or links to relevant literature that specifically talks about this E2E evaluation framework (Arxiv papers or something similar)?
Thanks a ton and keep up the work in this retrieval pipeline space. Knowledge augmented language models are going to be amazing.
Thanks for the great comment!
Def start with the e2e RAG paper: arxiv.org/abs/2210.02627
Beyond that, check out DALM docs and source code from Arcee!
github.com/arcee-ai/DALM
Hell yes, I was looking for just a paper like that on E2E RAG. Thanks a ton. I found the Arcee Github a couple hours ago, going to parse through it in the coming days! I'm trying to develop a RAG pipeline for certain finance domains so this is all ultra-relevant. @@AI-Makerspace
@@arkabagchi8689 Of course! Keep us posted as you build, ship, and share!
Thank you for that nice video guys. You mentioned that there are open source models for generating synthetic data. Can you please suggest any?
Generating synthetic data is best done today with the most powerful models that you can find, so we'd highly recommend using GPT-4 for this today. If you'd like to leverage open-source models, then once you see what the OpenAI models can do we recommend using that data quality as a baseline to compare to outputs from the latest and greatest OS models like Solar, Mistral, Yi, Llama 2, etc!
Quick question, if I have a query rewriting model that takes a user's input query into a simplified or a set of simplified sub queries to be sent to the retriever, I'm thinking can I leverage this framework to train the query rewriter, retriever, as well as the generator (LLM) end-to-end?
This process can be used to train any data you'd like - so long as there is a retrieval and generation step in the process!
Thank a lot Team! Question: After finetuning, how does one save the fine-tuned model to disk?
You can use the `.push_to_hub()` method to push the completed model to the Hugging Face Hub!
Dear can you share your keynote? The resolution is up to only 720.
I just saw the slides shared !!!! Appreciated for the grate work, it really save my day
Great tutorial - thank you! However, a lot of useful information is posted in the chat window and it got lost when the tutorial ends. I don't know if there is a practical solution to this, unfortunately.
do you have it?
Do I have what?
Hi @saka242 - thanks for the note! We did not intentionally take it down, have double checked the streaming settings, and are hoping that it shows up within the next day or so 🙏
Looks to be working now!
Can I use a custom model as a generator?
Yes!
Hey guys.
At ~14:30 you talk about genrating answers with question-context pairs, but generate_answer func never calls the context, just the question. Wouldn't it be better to give llm question AND context? Since the question, I would assume, might sound like: "What Arthur decided to do at the end?" And without the context, llm might give suboptimal answer.
I have also not found a link to colab NB, did you give any?
Thanks for the great talk!
Here's the link - it's in a pinned comment: colab.research.google.com/drive/1wwGLuEreZJfpxTvFeMLFbWb1GkRkXFwS?usp=sharing
And yes, you're absolutely correct! Using the context would likely improve the generated answers. I believe the intent was to use both the query and the context - but we must've made a typo that prevented both from being utilized!
@AI-Makerspace I've updated the code to reflect this.
What open source platform/library can I use to create synthetic data, instead of using openIAI?
Llama 3 70B is a decent replacement! Be mindful of any licensing restrictions!
Can you explain how to achieve the same without OpenAI?
Thanks in advance
You only need OpenAI to generate the synthetic dataset (QAC triplets) so you could substitute any process that results in question, answer, context triplets for OpenAI.
Stop reading from a script, Greg, and ditch the goofy hat. It's distracting.
Thanks for the feedback @robertcringely7348
Dude, rock the way you are man! Love the style and presentation! If a hat can be distracting, I can't imagine how you would get anything done in today's age lol.
Who cares, really. If it ain't broke, don't fix it. Awesome content guys!