
- 33
- 518 254
Tali Dekel
Приєднався 4 гру 2009
Layered Neural Atlases for Consistent Video Editing
Accompanying video for our SIGGRAPH'21 work: " Layered Neural Atlases for Consistent Video Editing". See more details in project webpage: layered-neural-atlases.github.io/
Authors: Yoni Kasten, Dolev Ofri, Oliver Wang, Tali Dekel
Authors: Yoni Kasten, Dolev Ofri, Oliver Wang, Tali Dekel
Переглядів: 6 321
Відео
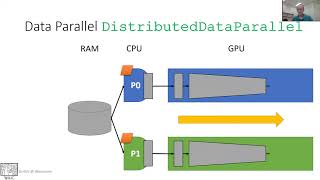

DL4CV@WIS (Spring 2021) Tutorial 13: Training with Multiple GPUs
Переглядів 9 тис.3 роки тому
Mode Parallel, Gradient Accumulation, Data Parallel with PyTorch, Larger Batches Lecturer: Shai Bagon

DL4CV@WIS (Spring 2021) Lecture 13: Theory of Deep Learning
Переглядів 8713 роки тому
Approximation Error, Estimation Error, Optimization Error, Expressiveness, Uniform Convergence, Generalization, Neural Tangent Kernel Guest Lecturer by Ohad Shamir

DL4CV@WIS (Spring 2021) Tutorial 12: Efficient Architectures
Переглядів 9053 роки тому
MobileNetV1-3, Mnasnet, EfficientNets, Performers, RegNet Lecturer: Akhiad Bercovich

DL4CV@WIS (Spring 2021) Lecture 12: Implicit Neural Representations, Neural Rendering
Переглядів 1,2 тис.3 роки тому
Implicit Representation, Neural Rendering, 3D Supervision, NeRF, Neural Level Sets, DVR, IDR,

DL4CV@WIS (Spring 2021) Tutorial 11: Deep Learning Practitioner's Toolbox
Переглядів 9713 роки тому
Hooks, Feature Extraction, TensorBoard, korina, Saving and Loading Models Lecturer: Shir Amir

DL4CV@WIS (Spring 2021) Lecture 11: Computer Graphics and Rendering
Переглядів 9813 роки тому
Rendering, Ray Tracing, Rasterization, Explicit and Implicit Scene Representations, Radiometry, BRDF Lecturer: Meirav Galun

DL4CV@WIS (Spring 2021) Tutorial 10: GPUs Fundamentals
Переглядів 1,3 тис.3 роки тому
GPU vs CPU for deep learning, GPU architectures, CUDA, Tensor cores Lecturer: Asher Fredman (NVIDIA)

DL4CV@WIS (Spring 2021) Lecture 10: Videos
Переглядів 9373 роки тому
Video Models: Early Fusion, Late Fusion, Slow Fusion, 3D CNN, Two Stream Networks, Self-Supervision in Videos: Shuffle & Learn, Video Colorization, Correspondence, Cycle Consistency in Time, SpeedNet Lecturer: Tali Dekel
DL4CV@WIS (Spring 2021) Tutorial 9: Generative Models (w/o GANs)
Переглядів 7263 роки тому
Variational Auto Encoders (VAEs), Vector Quantize VAE (VQ-VAE), VQ-VAE2, DALL-E, Implicit Maximum Likelihood Estimation (IMLE), GPNN Lecturer: Niv Granot
DL4CV@WIS (Spring 2021) Lecture 9: Self-Supervision
Переглядів 9993 роки тому
Context as Supervision (relative patch locations, inpainting, Jigsaw puzzel), Geometric Transformation, Colorization, Contrastive Learning (SimCLR), Depth of moving people by watching frozen people. Lecturer: Tali Dekel
DL4CV@WIS (Spring 2021) Tutorial 7: Sequences
Переглядів 7243 роки тому
RNNs, LSTM, Tranformeres in Computer Vision Lecturer: Akhiad Bercovich
DL4CV@WIS (Spring 2021) Lecture 8: Generative Models
Переглядів 1,1 тис.3 роки тому
Generative Adversarial Networks (GANs), Inception Score, Frechet Inception Distance (FID), Image to image translation, model collapse, SyleGAN, Big-GAN, Single Image GANs Lecturer: Assaf Shocher
DL4CV@WIS (Spring 2021) Lecture 7: Sequences (RNN, Attention)
Переглядів 1,7 тис.3 роки тому
Recurrent Neural Networks (RNNs), Sequence to Sequence, Attention Layer, Self Attention Layer, Non Local Networks, Transformer Layer, Transformer Network, Visual Transformers (ViT) Lecturer: Shai Bagon
DL4CV@WIS (Spring 2021) Tutorial 6: Adversarial Examples
Переглядів 2 тис.3 роки тому
Adversarial Examples, Perturbation Attack, PGD (Iterated-GSM), Black-box Attacks, Adversarial Training Lecturer: Niv Haim
DL4CV@WIS (Spring 2021) Lecture 6: Visualizing and Understanding Neural Networks
Переглядів 1,5 тис.3 роки тому
DL4CV@WIS (Spring 2021) Lecture 6: Visualizing and Understanding Neural Networks
DL4CV@WIS (Spring 2021) Tutorial 4: Advanced PyTorch
Переглядів 8 тис.3 роки тому
DL4CV@WIS (Spring 2021) Tutorial 4: Advanced PyTorch
DL4CV@WIS (Spring 2021) Lecture 5: Object Detection and Segmentation
Переглядів 1,9 тис.3 роки тому
DL4CV@WIS (Spring 2021) Lecture 5: Object Detection and Segmentation
DL4CV@WIS (Spring 2021) Tutorial 3: CNN Architectures
Переглядів 1,2 тис.3 роки тому
DL4CV@WIS (Spring 2021) Tutorial 3: CNN Architectures
DL4CV@WIS (Spring 2021) Lecture 4: Practical Training
Переглядів 1,6 тис.3 роки тому
DL4CV@WIS (Spring 2021) Lecture 4: Practical Training
DL4CV@WIS (Spring 2021) Lecture 3: Convolutional Neural Networks
Переглядів 1,7 тис.3 роки тому
DL4CV@WIS (Spring 2021) Lecture 3: Convolutional Neural Networks
DL4CV@WIS (Spring 2021) Tutorial 2: Introduction to Pytorch
Переглядів 2,1 тис.3 роки тому
DL4CV@WIS (Spring 2021) Tutorial 2: Introduction to Pytorch
DL4CV@WIS (Spring 2021) Lecture 2: Neural Networks
Переглядів 1,7 тис.3 роки тому
DL4CV@WIS (Spring 2021) Lecture 2: Neural Networks
DL4CV@WIS (Spring 2021) Tutorial 1: Linear Regression & Softmax Classifier
Переглядів 2,1 тис.3 роки тому
DL4CV@WIS (Spring 2021) Tutorial 1: Linear Regression & Softmax Classifier
DL4CV@WIS (Spring 2021) Lecture 1: Introduction & Basic Supervised Learning
Переглядів 9 тис.3 роки тому
DL4CV@WIS (Spring 2021) Lecture 1: Introduction & Basic Supervised Learning
Lecture 1: Introduction & Basic Supervised Learning
Переглядів 3743 роки тому
Lecture 1: Introduction & Basic Supervised Learning
Learning Depths of Moving People by Watching Frozen People
Переглядів 40 тис.5 років тому
Learning Depths of Moving People by Watching Frozen People
Sparse, Smart Contours to Represent and Edit Images
Переглядів 1,3 тис.6 років тому
Sparse, Smart Contours to Represent and Edit Images
On the Effectiveness of Visible Watermarks
Переглядів 406 тис.7 років тому
On the Effectiveness of Visible Watermarks
import numpy as np from PIL import Image import tensorflow as tf from tensorflow.keras.applications import MobileNetV2 from tensorflow.keras.applications.mobilenet_v2 import preprocess_input, decode_predictions from art.estimators.classification import TensorFlowV2Classifier from art.attacks.evasion import FastGradientMethod # Step 1: Load and preprocess the image def load_image(image_path): image = Image.open(image_path).convert('RGB') return image def resize_image(image, size=(224, 224)): return image.resize(size, Image.LANCZOS) def preprocess_image(image): image_array = np.array(image).astype(np.float32) image_preprocessed = preprocess_input(image_array) # Scales values as required by MobileNetV2 return image_preprocessed def deprocess_image(image_array): # Convert back from preprocessed [-1,1] to [0,255] image_array = ((image_array + 1.0) * 127.5).astype(np.uint8) return image_array # Step 2: Generate adversarial perturbation def generate_adversarial(model, image_preprocessed, eps=0.1): loss_object = tf.keras.losses.CategoricalCrossentropy() classifier = TensorFlowV2Classifier( model=model, nb_classes=1000, input_shape=image_preprocessed.shape[1:], loss_object=loss_object, clip_values=(-1.0, 1.0), ) attack = FastGradientMethod(estimator=classifier, eps=eps) adversarial_image = attack.generate(x=np.expand_dims(image_preprocessed, axis=0)) return adversarial_image[0] # Remove batch dimension # Step 3: Create the blended image with random weights def create_weighted_image(original_image_array, adversarial_image_array): # Generate random weights between 0 and 1 for each pixel weights = np.random.rand(*original_image_array.shape) # Blend the images blended_image_array = original_image_array * (1 - weights) + adversarial_image_array * weights # Ensure pixel values are within valid range blended_image_array = np.clip(blended_image_array, 0, 255).astype(np.uint8) # Convert array to image blended_image = Image.fromarray(blended_image_array) return blended_image # Main execution if __name__ == '__main__': import os import random # Set random seed for reproducibility random.seed(42) np.random.seed(42) tf.random.set_seed(42) # Paths image_path = 'turtle.jpg' # Replace with your image file path adversarial_image_path = 'adversarial_turtle.jpg' blended_image_path = 'blended_turtle.jpg' # Load the original high-resolution image original_image = load_image(image_path) original_image_array = np.array(original_image).astype(np.float32) # Resize and preprocess image for the model resized_image = resize_image(original_image) image_preprocessed = preprocess_image(resized_image) # Load the pre-trained MobileNetV2 model model = MobileNetV2(weights='imagenet') # Generate adversarial image adversarial_image_preprocessed = generate_adversarial(model, image_preprocessed, eps=0.1) # Deprocess images for blending adversarial_image_array = deprocess_image(adversarial_image_preprocessed) adversarial_image = Image.fromarray(adversarial_image_array) adversarial_image = adversarial_image.resize(original_image.size, Image.LANCZOS) adversarial_image_array = np.array(adversarial_image).astype(np.float32) # Create the blended image blended_image = create_weighted_image(original_image_array, adversarial_image_array) # Save the images adversarial_image_uint8 = adversarial_image_array.astype(np.uint8) adversarial_image_pil = Image.fromarray(adversarial_image_uint8) adversarial_image_pil.save(adversarial_image_path) print(f"Adversarial image saved as '{adversarial_image_path}'") blended_image.save(blended_image_path) print(f"Blended image saved as '{blended_image_path}'") # Optional: Verify the classification of the blended image # Resize blended image to model input size blended_image_resized = resize_image(blended_image) blended_image_preprocessed = preprocess_image(blended_image_resized) # Predictions preds_original = model.predict(np.expand_dims(image_preprocessed, axis=0)) preds_adversarial = model.predict(np.expand_dims(adversarial_image_preprocessed, axis=0)) preds_blended = model.predict(np.expand_dims(blended_image_preprocessed, axis=0)) decoded_preds_original = decode_predictions(preds_original, top=1)[0][0] decoded_preds_adversarial = decode_predictions(preds_adversarial, top=1)[0][0] decoded_preds_blended = decode_predictions(preds_blended, top=1)[0][0] print(f"Original image classified as: {decoded_preds_original[1]} ({decoded_preds_original[2]*100:.2f}% confidence)") print(f"Adversarial image classified as: {decoded_preds_adversarial[1]} ({decoded_preds_adversarial[2]*100:.2f}% confidence)") print(f"Blended image classified as: {decoded_preds_blended[1]} ({decoded_preds_blended[2]*100:.2f}% confidence)")
where can i find other resources like this that talk about practical considerations for deep learning training for an intermediate level.
The question @ 28:18 was actually how do we know when to change (i.e., decay) the learning rate, not how do we choose the initial learning rate value.
very informative. Thanks.
Can you please share a link to the HW assignment (and possibly related code\ Jupyter notbooks) ? Thank you for sharing these lectures and tutorials !
sir if i have more data like more than 100gb which cannot be stored in google colab then how should i approach this problem for training my model on whole data
Thank you! Very useful lecture. The teacher explained basic concepts really well.
Thanks a lot for this, helped with my interview prep!
21:19 Where does the averaging of gradients happen? On the CPU as shown in the animation? Or all the GPUs talk to each other directly and averaging happens on each GPU?
It depends on the HW you got and the backend you are using. I suppose with NVIDIA servers and nccl backend it all happens between GPUs without CPU involvement. The connection is done device-to-device
There are lots of tutorials, introductions, "for beginners", I think we do like to see some "advanced", "useful" materials for all of us.
When is this out or love to know more
Please provide us the course website if it is possible! Thank you!
Found it, it is publicly available for use, here ... dl4cv.github.io/schedule.html
Really good and clear, thank you for this video!
Never released the code did you?
super clear! Thanks!
thanks
so clear and well-explained. Thank you very much
thanks for course
I think the questions are excellent
Thank you so much
so clear,so great
I have a question. The train function runs on each process independent of the other (train functions running on other process). Within train, the epoch may finish at different times for each train function. How does the PyTorch distributed know that when it is time to synchronize gradients? BTW - this is the best lecture I have seen on this topic :+1:
all processes are sync every gradient update.
Thank you very much. Very good presentation, comprehensive and clear.
This tutorial is so underrated! Hands down the most clear and in-depth understanding of DDP for someone who doesn't know multi-processing in Pytorch. I came across this after watching 4-5 other videos. Strongly recommend this one.
Thanks a lot. really enjoyed it. God bless you all
This was very interesting. Are slides also available by any chance? I'd also really like to see the homework and try them out as well. God bless you.
Can you Also share the link to other videos about PyTorch in this series ? This video was quite insightful.
Can be found here: ua-cam.com/play/PL_Z2_U9MIJdNgFM7-f2fZ9ZxjVRP_jhJv.html
Thanks cam explanation is v good
how did you do it can you share with me , thank you
Thanks a zillion times for this very informative series DL4CV. I must ack that I was drawn by the Borat thumbnail (it seemed fun, is located at 6:02) but I stayed for the learning.
Love this!!!!! Great lecturer
Will you release a GUI? Nice project!
I second this!!
Nice
תודה רבה🙏
Can you please make a google colab demo of this that we can try out? thanks in advance!
Super interesting stuff! This was discussed on RoosterTeeth podcast 631 around 38 minutes in.
That's exactly what brought me here as well. Took me a minute to find it. Such an interesting video.
Could you tell more about the object insertion approaches? I am so interested on the achieved effect!
LOCKDOWN FROM GOOGLE
I do a research work on this topic, can you send to me this presentation i saw it is so helpful for me
Simply Amazing.
It's amazing. On this technology, you can make many useful pieces. I just have no words ... it's cool
Use opig watermak problem solvd
Wow! Really amazing results! Congrats!
It's so cool.
Can or is this gonna be converted to a real programm without having to install all the addons for python. Sorry I am not very talented xD
That's insane!
For some better result you can use 4 cameras horizontally and 4 cameras vertically. So the all side parallax can be obtained that can do the work more effectively
This would be very hard to use in motion videos, for acquiring data (filming new manequin challenges) or for aplying it (filiming a movie scene to edit later) I wonder how this apparatus would work (a 360 câmera maybe?) _never the less_ the processing time would increase 8 times!
@@deivisony although it would be so cheap that anyone can afford this easily and can be accuired easily by small scale movie makers..
+3:10 this would incredibly useful for visual effects work. it's a real pain point
We wonder what AI is going to produce out of #10yearschallenge
Beautiful! all this with no synthetic data! *How fast it runs with 1 mega pixel image for example ? *I would want to see how the model works on a scene that a human is walking in a forest environment, with a strong wind that moves everything around. or indoor with many non human moving objects.