
- 12
- 105 815
Afaque Ahmad
Singapore
Приєднався 10 кві 2023
Hey, I’m Afaque Ahmad, a Senior Data Engineer at QuantumBlack, McKinsey & Company and previously at Urban Company (formerly UrbanClap). This channel was created out of my endeavour for teaching and simplifying complex data engineering concepts and, in doing so, perhaps offer a fresh perspective on how we approach them.
Watch out videos on my channel for best-in-class videos on Apache Spark, complex SQL, Advanced Python, and, emerging topics in the area of data engineering.
LinkedIn: www.linkedin.com/in/afaque-ahmad-5a5847129/
GitHub: github.com/afaqueahmad7117
Contact Email: dataengineer7117@gmail.com
Watch out videos on my channel for best-in-class videos on Apache Spark, complex SQL, Advanced Python, and, emerging topics in the area of data engineering.
LinkedIn: www.linkedin.com/in/afaque-ahmad-5a5847129/
GitHub: github.com/afaqueahmad7117
Contact Email: dataengineer7117@gmail.com
Apache Spark Executor Tuning | Executor Cores & Memory
Welcome back to our comprehensive series on Apache Spark Performance Tuning & Optimisation! In this guide, we dive deep into the art of executor tuning in Apache Spark to ensure your data engineering tasks run efficiently.
🔹 What is inside:
Learn how to properly allocate CPU and memory resources to your Spark executors and the number of executors to create to achieve optimal performance. Whether you're new to Apache Spark or an experienced data engineer looking to refine your Spark jobs, this video provides valuable insights into configuring the number of executors, memory, and cores for peak performance. I’ve covered everything from understanding the basic structure of Spark executors within a cluster, to advanced strategies for sizing executors optimally, including detailed examples and calculations.
📘 Resources:
📄 Complete Code on GitHub: github.com/afaqueahmad7117/spark-experiments
🎥 Full Spark Performance Tuning Playlist: ua-cam.com/play/PLWAuYt0wgRcLCtWzUxNg4BjnYlCZNEVth.html
🔗 LinkedIn: www.linkedin.com/in/afaque-ahmad-5a5847129/
Chapters:
0:00 - Introduction to Executor Tuning in Apache Spark
0:37 - Understanding Executors in a Spark Cluster
3:30 - Example: Sizing Executors in a Cluster
4:58 - Example: Sizing a Fat Executor
9:34 - Example: Sizing a Thin Executor
12:50 - Advantages and Disadvantages of Fat Executor
18:25 - Advantages and Disadvantages of Thin Executor
22:12 - Rules for sizing an Optimal Executor
26:30 - Example 1: Sizing an Optimal Executor
38:15 - Example 2: Sizing an Optimal Executor
43:50 - Key Takeaways
#ApacheSparkTutorial #SparkPerformanceTuning #ApacheSparkPython #LearnApacheSpark #SparkInterviewQuestions #ApacheSparkCourse #PerformanceTuningInPySpark #ApacheSparkPerformanceOptimization #ApacheSpark #DataEngineering #SparkTuning #PythonSpark #ExecutorTuning #SparkOptimization #DataProcessing #pyspark #databricks
🔹 What is inside:
Learn how to properly allocate CPU and memory resources to your Spark executors and the number of executors to create to achieve optimal performance. Whether you're new to Apache Spark or an experienced data engineer looking to refine your Spark jobs, this video provides valuable insights into configuring the number of executors, memory, and cores for peak performance. I’ve covered everything from understanding the basic structure of Spark executors within a cluster, to advanced strategies for sizing executors optimally, including detailed examples and calculations.
📘 Resources:
📄 Complete Code on GitHub: github.com/afaqueahmad7117/spark-experiments
🎥 Full Spark Performance Tuning Playlist: ua-cam.com/play/PLWAuYt0wgRcLCtWzUxNg4BjnYlCZNEVth.html
🔗 LinkedIn: www.linkedin.com/in/afaque-ahmad-5a5847129/
Chapters:
0:00 - Introduction to Executor Tuning in Apache Spark
0:37 - Understanding Executors in a Spark Cluster
3:30 - Example: Sizing Executors in a Cluster
4:58 - Example: Sizing a Fat Executor
9:34 - Example: Sizing a Thin Executor
12:50 - Advantages and Disadvantages of Fat Executor
18:25 - Advantages and Disadvantages of Thin Executor
22:12 - Rules for sizing an Optimal Executor
26:30 - Example 1: Sizing an Optimal Executor
38:15 - Example 2: Sizing an Optimal Executor
43:50 - Key Takeaways
#ApacheSparkTutorial #SparkPerformanceTuning #ApacheSparkPython #LearnApacheSpark #SparkInterviewQuestions #ApacheSparkCourse #PerformanceTuningInPySpark #ApacheSparkPerformanceOptimization #ApacheSpark #DataEngineering #SparkTuning #PythonSpark #ExecutorTuning #SparkOptimization #DataProcessing #pyspark #databricks
Переглядів: 8 805
Відео
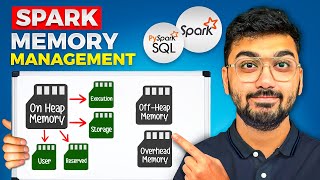

Apache Spark Memory Management
Переглядів 9 тис.5 місяців тому
Welcome back to our comprehensive series on Apache Spark Performance Tuning/Optimisation! In this video, we dive deep into the intricacies of Spark's internal memory allocation and how it divides memory resources for optimal performance. 🔹 What you'll learn: 1. On-Heap Memory: Learn about the parts of memory where Spark stores data for computation (shuffling, joins, sorting, aggregation) and ca...

Shuffle Partition Spark Optimization: 10x Faster!
Переглядів 8 тис.7 місяців тому
Welcome to our comprehensive guide on understanding and optimising shuffle operations in Apache Spark! In this deep-dive video, we uncover the complexities of shuffle partitions and how shuffling works in Spark, providing you with the knowledge to enhance your big data processing tasks. Whether you're a beginner or an experienced Spark developer, this video is designed to elevate your skills an...

Bucketing - The One Spark Optimization You're Not Doing
Переглядів 6 тис.8 місяців тому
Dive deep into the world of Apache Spark performance tuning in this comprehensive guide. We unpack the intricacies of Spark's bucketing feature, exploring its practical applications, benefits, and limitations. We discuss the following real-world scenarios where bucketing is most effective, enhancing your data processing tasks. 🔥 What's Inside: 1. Filter Join Aggregation Operations: A comparison...

Dynamic Partition Pruning: How It Works (And When It Doesn’t)
Переглядів 3,4 тис.8 місяців тому
Dive deep into Dynamic Partition Pruning (DPP) in Apache Spark with this comprehensive tutorial. If you've already explored my previous video on partitioning, you're perfectly set up for this one. In this video, I explain the concept of static partition pruning and then transition into the more advanced and efficient technique of dynamic partition pruning. You'll learn through practical example...

The TRUTH About High Performance Data Partitioning
Переглядів 5 тис.9 місяців тому
Welcome back to our comprehensive series on Apache Spark performance optimization techniques! In today's episode, we dive deep into the world of partitioning in Spark - a crucial concept for anyone looking to master Apache Spark for big data processing. 🔥 What's Inside: 1. Partitioning Basics in Spark: Understand the fundamental principles of partitioning in Apache Spark and why it's essential ...

Speed Up Your Spark Jobs Using Caching
Переглядів 3,9 тис.11 місяців тому
Welcome to our easy-to-follow guide on Spark Performance Tuning, honing in on the essentials of Caching in Apache Spark. Ever been curious about Lazy Evaluation in Spark? I’'ve got it broken down for you. Dive into the world of Spark's Lineage Graph and understand its role in performance. The age-old debate, Spark Persist vs. Cache, is also tackled in this video to clear up any confusion. Learn...

How Salting Can Reduce Data Skew By 99%
Переглядів 7 тис.11 місяців тому
Spark Performance Tuning Master the art of Spark Performance Tuning and Data Engineering in this comprehensive Apache Spark tutorial! Data skew is a common issue in big data processing, leading to performance bottlenecks by overloading some nodes while underutilizing others. This video dives deep into a practical example of data skew and demonstrates how to optimize Spark performance by using a...

Data Skew Drama? Not Anymore With Broadcast Joins & AQE
Переглядів 6 тис.11 місяців тому
Spark Performance Tuning Welcome back to another engaging apache spark tutorial! In this apache spark performance optimization hands on tutorial, we dive deep into the techniques to fix data skew, focusing on Adaptive Query Execution (AQE) and broadcast join. AQE, a feature introduced in Spark 3.0, uses runtime statistics to select the most efficient query plan, optimizing shuffle partitions, j...
Why Data Skew Will Ruin Your Spark Performance
Переглядів 4,9 тис.11 місяців тому
Spark Performance Tuning Welcome back to my channel. In this tutorial to dive into this comprehensive Apache Spark tutorial, where we will cover Apache Spark optimization techniques. Are you struggling with Data Skew and uneven partitioning while running Spark jobs? You're not alone! In this video, we dive deep into the world of Spark Performance Tuning and Data Engineering to tackle the common...
Master Reading Spark DAGs
Переглядів 15 тис.Рік тому
Spark Performance Tuning In this tutorial, we dive deep into the core of Apache Spark performance tuning by exploring the Spark DAGs (Directed Acyclic Graph). We cover the Spark DAGs (Directed Acyclic Graph) for a range of operations from reading files, Spark narrow and wide transformations with examples, aggregation using groupBy count, groupBy count distinct. Understand the differences betwee...
Master Reading Spark Query Plans
Переглядів 29 тис.Рік тому
Spark Performance Tuning Dive deep into Apache Spark Query Plans to better understand how Apache Spark operates under the hood. We'll cover how Spark creates logical and physical plans, as well as the role of the Catalyst Optimizer in utilizing optimization techniques such as filter (predicate) pushdown and projection pushdown. The video covers intermediate concepts of Apache Spark in-depth, de...
Industry level content.
Is this applicable to cloud platform?
I never see such a detailed explanation. Thank you very much @afaque Ahmad. Is there any way we can get the document.
Awesome video! I've been searching for something like this and all the other videos I found don't get to the point and neither explain things as good as you do. I'm definitely subscribing and sharing this with other DE's from my team, please keep posting content like this!
Very informative video afaque. Please create more videos.
What if the nodes are of unequal size?
Excellent.. Keep going..
Am.not able to see spill details in spark 3.5.2 UI?
Excellent Content..!! Loved It. Such detailed explanation on Salting Technique with Graphical Representation.
Hi Sir Please Make a Detailed course on apache spark which include every aspect of spark for Data Engineer role Please make sure there are a lot of begineer course here in market keep the course from intermediate level to advance level. Please tr to make video in Hindi it will be very helpful.
Thank you for this video !!
Sir please do a video on executor out of memory in spark and driver out of memory in spark
This is helpful, but I still have a few doubts. 1. If Broadcast join is immune to skewness, why there is Salting technique? 2. In the Broadcast join example, the customer dataset appeared to be outside of any executor. Where is it actually stored? How can we specify its storage location?
Broadcast is only possible if the other table is really small to be replicated
Want to understand better, Read this: Spark CacheLLM Response: 1. **Why Use Caching?** - Caching can significantly improve performance by reusing persistent data instead of recomputing it - It helps avoid redundant computations on the same dataset across multiple actions 2. **Lazy Evaluation and Caching** - Apache Spark uses lazy evaluation, where transformations are not executed until an action is triggered - Caching can help by materializing the result of a long sequence of transformations, avoiding recomputation 3. **Spark's Lineage Graph** - Spark tracks the lineage of transformations using a Lineage Graph - Caching breaks the lineage, reducing the size of the graph and improving performance 4. **Caching vs. No Caching** - The demo shows a significant performance improvement when caching is used, as seen in the Spark UI 5. **Persist and Storage Levels** - The `persist()` method is used for caching, with different storage levels available - Storage levels like `MEMORY_ONLY`, `DISK_ONLY`, and combinations control memory/disk usage and replication - Choose the appropriate storage level based on your requirements and cluster resources 6. **When to Cache?** - Cache datasets that are reused multiple times, especially after a long sequence of transformations - Cache intermediate datasets that are expensive to recompute - Be mindful of cluster resources and cache judiciously 7. **Unpersist** - Use `unpersist()` to remove cached data and free up resources when no longer needed - Spark may automatically unpersist cached data if memory is needed If you liked it, Upvote it. NarutoLLM Response
Great tutorials 🙏, please create more videos on spark from beginners point of view
Your channel is so underrated, Please dont stop
i like very much of your videos, it's insightful. can you please make series/videos on Spark interview oriented questions. Thanks in advance
Hi Afaque. A suggestion. You could start from the beginning to connect the DOTS! Like if in your scenario we have X Node machine with Y workers and Z exectors and if you do REPARTITION and fit the data like this then this could happen. Otherwise the Machine would sit idle and so on.
Perfect explanation & perfect examples throughout the playlist, Bhai mere Change data capture aur Slowly changing dimension jo bhi apply hote hain project me uska bhi khel samza de.
Thanks for the kind words bhai @tumbler8324. Sab ayega bhai kuch waqt mein, pipeline mein hai :)
a lot of knowledge in just one video
Appreciate it @user-pq9tx6ui2t :)
I spent INR 42000 on a Big Data course but could not understand this concept clearly because the trainer himself lacked clarity. Here I understood completely.
Appreciate the kind words @skybluelearner4198 :)
Great explanation of such a complex topic, thanks and keep up the good work.
Thanks man @Dhawal-ld2mc :)
Great explanation, Thank you, But how would we know how to configure exact (at least best) "spark.sql.shuffle.partitions" at run time? Because each run/day the volume of the data is going to be changed. So, how do we determine the data volume at run time to set the shuffle.partitions number?
Awesome explanations! pls share us more relevant videos
Dead gorgeous stuff.
Appreciate it man :)
Hey Afaque Great tutorials. You should consider doing a full end to end spark project with a Big volume of data so we can understand the challenges faced and how to tackle them. Would be really helpful!
A full-fledged in-depth project using Spark and the modern data stack coming soon, stay tuned @mohitupadhayay1439 :)
Not easy to understand, but it great
Useful information
Thanks for the video! I also have a question: when I execute complex query, there will be multiple stage with different shuffle write sizes, which do I have to take in consideration for the computation of the optimal number of shuffle partitions?
All the concepts are clearly explained. Please do more videos.
Appreciate the kind words @deepikas7462, more coming soon :)
Your teaching skill is very good, please make a full series on PySpark, that'll be helpful for so many aspiring data engineers.
Appreciate the kind words @abusayed.mondal, more coming soon, stay tuned :)
Please make one on AWE aswell
You mean AWS?
@@afaqueahmad7117 Sorry it was supposed to be AQE ( Adaptive Query Execution).
Complete details on AQE is here below :) ua-cam.com/video/bRjVa7MgsBM/v-deo.html
@@afaqueahmad7117 Thanks🌟
Excellent 🎉 👍 appreciate your effort
Correct me if I'm wrong, but these calculations consider the execution of only one job at a time. How do the calculations change when there are multiple jobs running in a cluster, as often happens?
Buddy! You got a new sub here. Loved your detailed explanation. I see no one explaining the query plain this detail and I believe this is the right way of learning. But I would love to see an entire Spark series.
Thank you @snehitvaddi for the kind appreciation. A full-fledged, in-depth course on Spark coming soon :)
@@afaqueahmad7117 Most awaited. Keep up the 🚀
Why to give such a large fraction (0.4) to User memory as in the end when the transformations will be performed in a particular stage , whether we give it a user defined function or any other function execution memory will be only used . So Whats exactly the role of User Memory ??
could you please make video on stack overflow like what are scenario when it can occur and how to fix it
Are you referring to OOM (out of memory errors) - Driver & Executor?
@@afaqueahmad7117 No, basically when we have multiple layers under single session then at that time stack memory getting full so to break it we have to make sure we are using one session per layer. e.g- suppose we have 3 layers (internal, external, combined) and if you run these in single session then it will throw stackoverflow error at any place whenever its stack get overflow. We tried to increase stack as well but that was not working. Hence at the last we come up with approach like will run one layer and then close session likewise
Thanks for the content, really appreciate it. My understanding is AQE take care of Shuffle Partition Optimization and we don't need to manually intervene (starting spark 3) to optimize shuffle partitions. Could you clarify this please?
Hey man. learnt a lot from the video. please help me out on this doubt for example 2, total executors = 44/4 = 11 you have said. But shouldn't we think machine by machine, here each machine can have, 15/4 === 3 executors if 4 core for each, giving total 3*3 nodes = 9. in your workout, it seems like there will be an executor which will use some cores from one node and some from other. Am I wrong in my thought process somewhere?
sorry if I am asking very basic question, can we set executors per spark job or per spark cluster? Also how to set this up using coding examples and all
Every-time I come here before attending an interview , I try to give this video a like , but end up realising that I already did it earlier. Best video on this topic on whole internet.
This means a lot to me @dudechany, I really thank you for the generous and kind appreciation :)
Really appreciate your efforts. This was very easy to understand and comprehensive as well.
@PratikPande-k5h Glad you're finding it easy to understand :)
One of the cleanest explanation I ever come across on the internals of Spark. Really appreciate all the effort you are putting into making these videos. If you don't mind, May I know which text editor are you are using when pasting the Physical plan?
Many thanks for the kind words @venkatyelava8043, means a lot. On the text editor - I'm using Notion :)
Excellent and clear cut explanation, thanks much for taking time and preaparing the content. Please do more.
Appreciate it @senthilkumarpalanisamy365. More coming soon, stay tuned :)
This is the most detailed explanation I have ever seen.
Appreciate it man @ridewithsuraj-zz9cc :)
Explanation is so good
Thank you @satyajitmohanty5039 :)
Hey @Afaque, great content as usual, but I thought this video could be a little concise, great work anyways!
Thank you @rgv5966 for the appreciation. Tried my best to keep it concise, but will take your feedback :)
Consider a scenario where my first data shuffle size is 100gb then giving more shuffle partitions make sense now in the last shuffle data size is drastically reduced to 10gb according to calculations how would be to give shuffle partitions giving 1500 would benefit for the first shuffle and not for the last shuffle. How do one approach this scenario
It's very useful ❤
perfect video