
- 7
- 30 553
James Villemarette
United States
Приєднався 5 гру 2017
yes
My Day with Hiroshima Carps’ Slyly
having some fun with the Philly Phantic's space cousin mascot Slyly, of the Hiroshima Carps.
chapters
0:00 playing with mini slyly
1:49 going down the carp walk
4:00 team roster plaques
4:39 going up the carp walk
5:22 indoor practice field
8:49 wedding
9:26 confused construction workers
10:16 friends
chapters
0:00 playing with mini slyly
1:49 going down the carp walk
4:00 team roster plaques
4:39 going up the carp walk
5:22 indoor practice field
8:49 wedding
9:26 confused construction workers
10:16 friends
Переглядів: 1 789
Відео
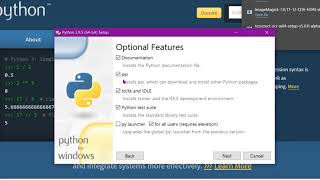

How to make OCR PDFs on Windows using Tesseract
Переглядів 16 тис.3 роки тому
It's free, it's easy, it's Tesseract, which is an Optical Character Recognition (OCR) engine that detects text in images and overlays the text onto PDFs. Here's how to do it in as short as a tutorial as possible. Medium amount of technical knowledge is helpful. 0:00 Introduction 0:48 Tesseract 1:32 PATH variable 2:38 ImageMagick 3:21 Python 3:49 GhostScript 4:21 convert.py 5:08 How to run the s...

UCA Nationals 2020: Harry the Husky's Skit
Переглядів 1,8 тис.4 роки тому
Harry the Husky, a mascot for the University of Washington, performs a one minute and 30 second skit for the Universal Cheer Association in Orlando, Florida. The entry video (which comprises 50% of the total points that the mascots are scored on) was not captured. See other performances in this playlist: ua-cam.com/play/PLPmFfBk35Y5PijiO8lK5BrO5bdRSVyq9S.html

UCA Nationals 2020: Univ. of Colorado Chip's First Place Skit
Переглядів 3,6 тис.4 роки тому
Chip, a mascot of the University of Colorado-Boulder, performs a one minute and 30 second skit that won first place in the Universal Cheer Association Division IA mascot competition in Orlando, Florida. The entry video (which is submitted for the competition and comprises 50% of the total points that the mascots are scored on) was not captured. See other performances in this playlist: ua-cam.co...

UCA Nationals 2020: Oklahoma Boomer's Skit
Переглядів 3,1 тис.4 роки тому
Boomer, a mascot of the University of Oklahoma, performs a one minute and thirty second skit for the Universal Cheer Association in Orlando, Florida. The skit begins at 0:50. The entry video precedes the skit. See other performances in this playlist: ua-cam.com/play/PLPmFfBk35Y5PijiO8lK5BrO5bdRSVyq9S.html

UCA Nationals 2020: Bucky Badger's Skit
Переглядів 2,7 тис.4 роки тому
Bucky Badger, a mascot of the University of Wisconsin, performing a one minute and thirty second skit for the Universal Cheer Association in Orlando, Florida. Skit begins at 1:02. The entry video precedes the skit. See other performances in this playlist: ua-cam.com/play/PLPmFfBk35Y5PijiO8lK5BrO5bdRSVyq9S.html

UCA Nationals 2020: Goldy Gopher's Skit
Переглядів 1,9 тис.4 роки тому
Goldy Gopher from the University of Minnesota performing a one minute and thirty second skit for the Universal Cheer Association in Orlando, Florida. Skit begins at 0:27. The entry video precedes the skit. See other performances in this playlist: ua-cam.com/play/PLPmFfBk35Y5PijiO8lK5BrO5bdRSVyq9S.html
スラィリー動きも可愛くて、心優しいですよね😊 面白い明るい子🎉 会ってハグされたい!
Hi. Your script ran and just created an empty subfolder for every page of my PDF. The PDF itself is untouched. Could you advise what happened here?
same:/
0:17
It hasn't worked for me, I followed each step perfectly. even the routes that are not mentioned but are seen in the cmd of the video.
an absolute G, thanks for saving lifes
so lovely😍
1:23
Any doubt ask copy the code and asky chat GPT it work for me
Thank you so much! I really appreciate how much effort you put into the video, especially with the captions too!
広島スラィリー毎日会える。住所が広島だったらマツダズムズムスタジアムにカープグッズ買い求めたいです😅ハッピースラィリーの目玉がかがやいている。スラィリー広島カープの目玉が事故ったキャラクター可愛くてたまらん。会いたい広島スタジアム生スライリー野球場😊
スラちゃんかわいい広島カープ
My document is ins spanish, how can I choose the language to use?
2:30〜 Koji Yamamoto He is a superstar in Hiroshima. Born in Hiroshima, raised in Hiroshima. Lead Carp to league champion 5 times as player 1 time as manager. League MVP 2 times, 2339 hits, 536 HR, 231 stolen base, get gold glove award 10 times.
I've caught in many erroros and struggled with it for almost half an hour. I've found a few changes about the script and some tips. so I'd like to tell other guys to help. 1. As many guys have mentioned, PdfFileMerger changed into PdfMerger. So we have to replace it. 2. And also, I'd got a parameter error. I thought it seens to be occured at converting phase which is using ImageMagick. so I searched about it and found that 'ImageMagick CLI command is 'magick' on Windows. So I'd changed and It finally worked. But 'convert' command worked at this clip, so I recommend it if 'convert' command were not working. 3. if you want to OCR with a specific language that is not English, find this line tesseract = 'tesseract "' + combined_pic + '" "' + combined_pic + '-ocr" PDF' and insert a language option; -l LANGUAGE_WHAT_YOU_WANT between '-ocr" and "PDF', so result is; tesseract = 'tesseract "' + combined_pic + '" "' + combined_pic + '-ocr" -l LANGUAGE_WHAT_YOU_WANT PDF' if you want to OCR with multiple languages use + between languages; -l LANG01+LANG02 I hope it could help other guys who are in trouble.
Really thank you about your comment, you have a beer paid!
i don't understand what did u mean at num 2
On Windows env, sometimes you could exeperience 'parameter error'. if so, it could be a solution that change 'convert' into 'magick' in this script. - open the script, go to 21st line(it starts with magick = 'convert -density.....') , and change the word 'convert' into 'magick' - This is not a package, so if there were changes on some component, we should adjust them by ourselves. I hope it helps:)
Can I use this script to convert to another language?
i run the script but it's creating a lot of folders, all empty, it's just a 20 pages PDF, what could i be doing wrong? everything was done just as the video says
okay i changed some stuff but idk what did i do, now it is converting to PDF with OCR but it's creating one PDF per page (over 20 files lol) and also as PNGs. So it is "working" i could just merge them, all but any idea why is this happening?
to make it work I had to change (PdfFileMarger to PdfMerger)
# from PyPDF2 import PdfFileMerger from PyPDF2 import PdfMerger # merger = PdfFileMerger() merger = PdfMerger()
What an Amazing script and video ! Thank you very helpful. May Allah bless you more. 😊
hey, my cmd open for a second and closes right after when i try to run the script, doesn't output nothing. anny thoughts on what could it be?
okay nevermind i got it to work running from terminal inside VSCode (don't ask me how)
For those who run the script and it gives an error, the cause is likely that you're using a newer version of Pdfmerger so to fix that you should first use "from PyPDF2 import PdfFileReader, PdfFileWriter, PdfMerger" and then ctrl + f to find where it says "merger = PdfFileMerger()" and change it to "merger = PdfMerger()" that should fix the problem :). I hope the OP sees this and posts an updated comment/python file. This video was incredibly useful and well done. Much thanks
👍
Thank you
@2:23 - After years of going from Win3.1 to win95 to win98 to winXP-Vista-7-8- and now Win10 - I can say this about PATH Variables: In order to keep everything separate and looking nice and working in the easiest way possible - you should always make a NEW path variable named "XXX-path" (like Tesseract-path) and put the path into THAT variable - AND THEN - edit the PATH variable and just add "%Tesseract-path%" to that variable. In this way, you can easily change the "Tesseract-path" variable and not muck up the PATH variable. Now - YES - it does make a NEW variable BUT - put it in the TOP area and not the bottom area so it is only invoked when you open a CLI (Command Line Interface or DOS window). So - the thing to think about is - what if they change where they put a program (or what if they change the name every single time they come out with a new version [like "myprog v1", then "myprog v2", then "myprog this is where it goes v3"]?). With this method all you need to do is to do the pathway selection, go to Environment Variables, find your "Tesseract-path" variable - and change the path there. It would then be automatically changed in the PATH variable. Or what if you wanted TWO versions of Tesseract? Why that's easy! You just put the new version in "Tesseract v2.x-path" and add that in to the PATH variable. Anyway - this is how I do it. It makes life simple (or simpler) if you always do it the same way. And now - back to the video. :-) Which is excellent by the way. :-)
👍
I am having serious trouble here. I don't want to screw up my laptop trying to get this to work. I have followed the instructions to a tee. There is a blip at 4:57. It appears to jump over a step. Either way, I followed it and this is what it said: "...Desktop\OCR-PDF>pip install PyPDF2 'pip' is not recognized as an internal or external command, operable program or batch file." Oh yay! So I tried it another way... "Desktop\OCR-PDF>convert.py Traceback (most recent call last): File "...Desktop\OCR-PDF\convert.py", line 4, in <module> from PyPDF2 import PdfFileMerger ModuleNotFoundError: No module named 'PyPDF2'" So I read TWoboS's steps and that didn't work. I read in Oliver's thread below that some got it to work after rebooting, but not for me. I read that you have to add the PATH to the Desktop folder, but that didn't work either. My computer is completely up to date. Is there another way to do this? Did something get left out?
same problem here, idk how to solve it
This video is great. I tried it. However I got stuck on the procedure you were describing on timelapse 4:35 when I needed to save the covert.py to a certain folder 'ocr-pdf'. Because I did not find such folder in my desktop (I wonder how it happened that you do have it.) Therefore where am I supposed to save the 'covert.py'? Nevetheless, I simply tried to save it just in my desktop, and then I followed the rest of the instructions. Fortunately it worked, but only once and I am mystified. It never worked again when I tried converting another scanned pdf files. I suspect its because I did not save it in folder'ocr-pdf'on my desktop. How would I have such folder? Is there any other workaround to be able for the 'covert.py to consistently work? Thanks in advance.😊
It's just a file he created on his desktop, you can create a folder and name it the same thing.
its the boi
if your having trouble with the pip install part you need to add that script to your paths
I’d love to see the hottie take off the head like Bluffton University and BGSU🥰🥰
I’d love to see the hottie take off the head like Bluffton University and BGSU🥰🥰
Thank you so much! # IF YOU HAD AN ERROR WITH invalid parameter -150 close the files and then do it again. It might take also some time depending on file size.
Danke! Beste Anleitung überhaupt. Kurz, knapp auf den Punkt! Einfach Perfekt!
Thank You for providing all the links of downloads ,It worked for me 👍
last step is too fast i didnt understand. how anyone can run pip install command in cmd.
Pip also needs to be added to System Environment Path,otherwise you cannot run it in cmd directly.
I installed pip with python, however, It gives pip is not a recognized command
look at my comment below, I think the solution is to add python to your envonmental variables like they do for tesseract in the video
@@catcrandell4189 thanks
I installed so many shit as u said ....not working
Thank you so much, it worked! For those having trouble, when you open cmd, make sure you are in the directory of the folder that contains the pdf file (e.g., C:\Users\James> cd OneDrive\Desktop\PDFFolderName). Then that is when you do the pip install PyPDF2.
Thaks. Another very simplest way is just install *"gImageReader"* that you can get for Windows from the GitHub repository *"gImageReader"* by "manisandro". For Linux just use the software Store
Finally something that works for me, thanks!
Does it overlay the text onto the pdf pages or does it just export the unformatted text as a pdf? I'm struggling to find one that overlays the text on the format of the pdf automatically :(
Thanks for making this!!!
Way to go to go junior varsity
Mil gracias! Funcionó perfecto 😃😃😃
me podrias decir si te abren bien los pdfs, a mi me salen de 1kb y dañados.
i just have a problem: Languages ! Is Tesseract auto recognize to choose the right language or we must edit the convert.py file maunaly ? Because it only works well with english documents, special languages so bad 😅 Thanks !
Hi . have you figured out some solution to make this work for languages other than English ?
Please help ! After run convert.py, i got this error: "Error, could not create PDF output file: Permission denied" it's also create Folder with png images and a converted pdf file, but can not open it Thanks for your very detail video !
Solved !!!!!! just allow tesseract.exe in you anti-virus program Anyway, Thank you very much again ! For your time to making very detailed video for me or anyone, who dont know about coding to transform all opensource public data out there, to become very easy to do Yes, very well explained video. Thankful !!
Does this only work with English? My output pdf is empty and the CLI shows invalid argument for each image.
I get the following error when I try to open the ocr-combined file: "There was an error opening this document. This file cannot be opened because it has no pages"
I am facing the same issue ,,did u solve it?
@@akashgeorge5433 me too
@@niksimeo04 idk somehow i tried again after a few days it worked....try restarting your pc after u have installed alll dependencies variables...etc Also just see if that pdf isnt open by another app...like adobe
@@akashgeorge5433 thank you. I will try this, maybe it does need a restart. thank you for your time
@@niksimeo04 welcome....telll me if it works for u
IF YOU CAN'T MAKE THE PIP COMMAND RUN I HAVE THE SOLUTION First, python is no longer installed in the program files, the path for it will be something like C:\Users\[USER NAME]\AppData\Local\Programs\Python\Python310 (I believe the 310 is the version so you will likely be able to find python just by changing the user name to your account name and then by copy and pasting up to C:\Users\[USER NAME]\AppData\Local\Programs\Python) Then, you need to add python (specifically "pip") to your system variables. Search for system variables (it should come up as "edit the system and environmental variables through the control panel), open "Environment Variables", then click "path" on the second box (system variables), click "edit", click on the lower most path then click the "new" button, then copy and paste the path to the python scripts folder (it's the one with the application to install pip... you do not need to include pip in the file path, just end it at scripts). Mine looks like "C:\Users\[USER]\AppData\Local\Programs\Python\Python310\Scripts". You have to press okay three times (once on each box) to save this choice. Finally, about the command prompt. Double check that your pip thing is working (I'm honestly not a computer person so I don't even know what this means myself but anyways). For me, in order to use python I had to start anything related to python with "py -m" (You do not need the quotation marks here and be careful with the dash placement, it goes before the m and that's important). So to check if my pip was working I had to type (again, no quotation marks) "py -m pip". If you're getting an error, i suggest checking out this link stackoverflow.com/questions/23708898/pip-is-not-recognized-as-an-internal-or-external-command So to run the pip install PyPDF2, you actually need to write (don't use the quotation marks here) "py -m pip install PyPDF2" and it should install :) You'll also notice that in the video, the poster originally starts off with something like C://User> you need to change the drive to your ocr folder. To do this, you simply need to write (you must include the quotation marks here): cd "[NEW PATH GOES HERE" Again, include the cd that comes before the path and you must use the quotation marks here. So the command for me looked like: cd "C:\Users\[USERNAME]\Documents\School\4-OCR\ocr-pdfs" I am not great at computers and I don't do coding so I pretty much downloaded python just for this and that's what created all the problems. I hope this helps :)
OMG! It work. Thanks for doing this video and for all of the software.
Good tutorial but you didnt show how to install Pip
I think it comes with Python
very well explained video, congratulations. Unfortunately it doesn't working for me yet... I have the error message that "Tesseract doesn't been recognized as a internal or external command". Think i'll try to use the python wrapper for tesseract, "pytesseract". Or maybe i'll see the tesseract documentation. Another trouble is the execution time... It takes several minutes per page. Does the conversion necesarily be in a png format? Thanks!
ua-cam.com/video/2kWvk4C1pMo/v-deo.html this will solve your issue
This is the start of a comment thread.
Hey. Great video! Very simple and basic. I've done all the steps as you mentiond. Sadly it's not working for me. I opend the convert.py with my Pycharm and got an error message saying : invalid parameter - 150. Could you help me to fix that? If any more output is needed let me know. Greetings :)
I am also getting same error. Did you find solution.
@@mahapavanablereboot did the Job
@@southpaw168 Yes for me too worked rebooting
Cool!)