
- 4
- 23 687
Coding In Rust
Приєднався 24 сер 2013
Future of Standard and CUDA C++
Future of Standard and CUDA C++
Christian Trott, Principal Member of Staff, Sandia National Laboratories
Bryce Lelbach, Standard C++ Library Design Committee Chair, NVIDIA
Eric A Niebler, Author of Standard C++ Ranges and Senders/Receivers, NVIDIA
Michael Garland, Director of Research, NVIDIA
Curious about the future of C++? Interested in learning about C++'s plans for concurrent, parallel, and heterogeneous programming? Join us for a lively discussion of C++'s roadmap by members of the Standard C++ committee.
Christian Trott, Principal Member of Staff, Sandia National Laboratories
Bryce Lelbach, Standard C++ Library Design Committee Chair, NVIDIA
Eric A Niebler, Author of Standard C++ Ranges and Senders/Receivers, NVIDIA
Michael Garland, Director of Research, NVIDIA
Curious about the future of C++? Interested in learning about C++'s plans for concurrent, parallel, and heterogeneous programming? Join us for a lively discussion of C++'s roadmap by members of the Standard C++ committee.
Переглядів: 393
Відео


GTC 2022 - CUDA: New Features and Beyond - Stephen Jones, CUDA Architect, NVIDIA
Переглядів 6 тис.2 роки тому
Learn about the latest additions to the CUDA platform: Language and Toolkit. Presented by one of the architects of CUDA, this engineer-focused session covers all the latest developments for NVIDIA's GPU developer ecosystem as well as looking ahead to where CUDA will be going over the coming year.
GTC 2022 - How CUDA Programming Works - Stephen Jones, CUDA Architect, NVIDIA
Переглядів 17 тис.2 роки тому
Come for an introduction to programming the GPU by the lead architect of CUDA. CUDA's unique in being a programming language designed and built hand-in-hand with the hardware that it runs on. Stepping up from last year's "How GPU Computing Works" deep dive into the architecture of the GPU, we'll look at how hardware design motivates the CUDA language and how the CUDA language motivates the hard...

this video is so clear and great
Thank you!
Your both CUDA videos are one of the best I have ever seen on that topic. Very interesting, insightful and entertaining. Gold.
so I can have multiple thingies running different instructions and I can fire and forget between these thingies without any synchronization penalty? looks pretty cool.
Look like Intel is out of the question here.
They are getting better in terms of energy efficiency and performance www.cnbc.com/2024/04/09/intel-unveils-gaudi-3-ai-chip-as-nvidia-competition-heats-up-.html
@@codinginrust Limitation of Gaudi is that it is a less flexible fixed function matrix math accelerator. General purpose compute engine in Hopper/Blackwell architecture can better support rapidly evolving LLM algos. Another issue is interconnect bandwidth: NVLINK5 absolutely crushes PCIE5
Is there a chance you can do a video about Why AMD's version isnt as good as NVIDIA ?
I've not got a AMD gfx card ZLUDA means it does not really matter www.phoronix.com/review/radeon-cuda-zluda
AMD's issue is tooling and the general software ecosystem. The hardware is reasonably close.
Christopher, do you think the long time it takes for ram to be accessed could be decreased by embedding a basic cpu in those ram modules?
Good question, I don't know!
Thank you for posting this. My knowledge of Cuda is stuck in 2018, and it is a real eye opener what it can do now. Block clusters, grid sync, matrix multiplications kernels launched directly from device...It is making me interested in programming them again. Both of the presentations by Stephen Jones were excellent.
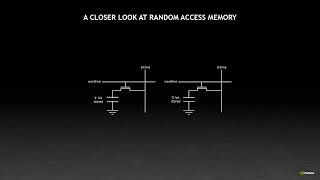
One thing that's confusing: if reading from a memory location in a different row is 3x slower than reading from a memory location in the same row - how come we get 13x slowdown? Worst case (if you're deliberately reading from a different row each time) - one would expect a 3x slowdown? What am I missing out on? Is it the burst mode? 2) You're using float2 type so that means your thread is loading 4 bytes (for 2 points) not 8 bytes? Which would put the 4 warps into 512B loading territory instead of the optimal 1024? -> EDIT: ok, I just saw that p1 & p2 are actually float pointers so that does make sense. 3) How can we guarantee that p1 & p2 arrays (holding the points) are adjacent, i.e. in the same physical row in memory? Great video! The sound quality is a bit off though.
It's 3x slower for reading a single value, but it gets worse when reading many contiguous values where the burst column read can read many values in one operation. For example, let's say that we're reading two sets of 10 values, one set of which are all contiguous in a row, and one set that are all on different rows. And you have the three ops in the video: LOAD a row, READ a column, STORE the row back. For the contiguous values: time = LOAD + BURST READ + STORE = 3 ops For the disjoint values: time = (LOAD + READ + STORE)*10 = 30 ops That's how you get the 10x speed-up.
Excellent. For the matrix multiply, you’re reusing the same row multiple times but the columns would have to be loaded in every time. So how do you increase compute intensity of the columns?
33:10 FlashAttention proved this wrong
"Occupancy is the most powerful tool that you have for tuning a program. **Once you're doing your best for memory access patterns** there's pretty much no algorithmic optimization that you can do that'll speed your program up by as much as 33%" I thought FlashAttention's major contribution was optimizing memory access patterns, namely reducing the number of HBM loads/stores.
can you please explain this a bit more? I'm trying to teach myself flash attention's cuda code.
He literally said "Once you are doing your best for memory access paterns" and Flash Attention is a MEMORY ACCESS algorithm, it reduces the memory access to GPU HMB RAM.
This video is pure gold: thanks so much for uploading I've learnt so much from it. I may have to watch it several times though!!! A great overview and introduction to so many areas for further study.